GPT-4推出以应对Bard的超越:最新模型已问世
 发布于2024-11-28 阅读(0)
发布于2024-11-28 阅读(0)
扫一扫,手机访问
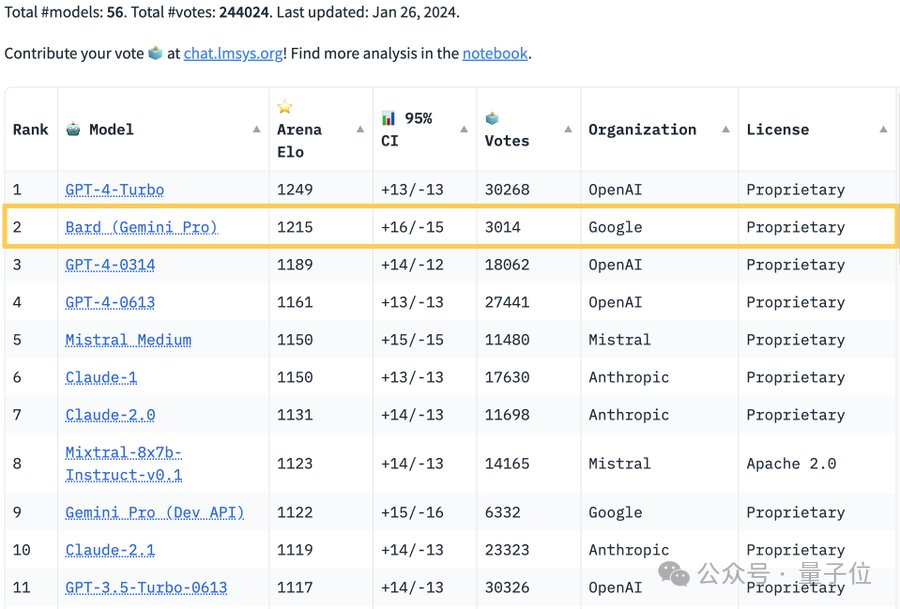
“大模型排位赛”权威榜单Chatbot Arena刷新:
谷歌Bard超越GPT-4,排名位居第二,仅次于GPT-4 Turbo。
然鹅,众多网友对此却表示“不服”、“不公平”。
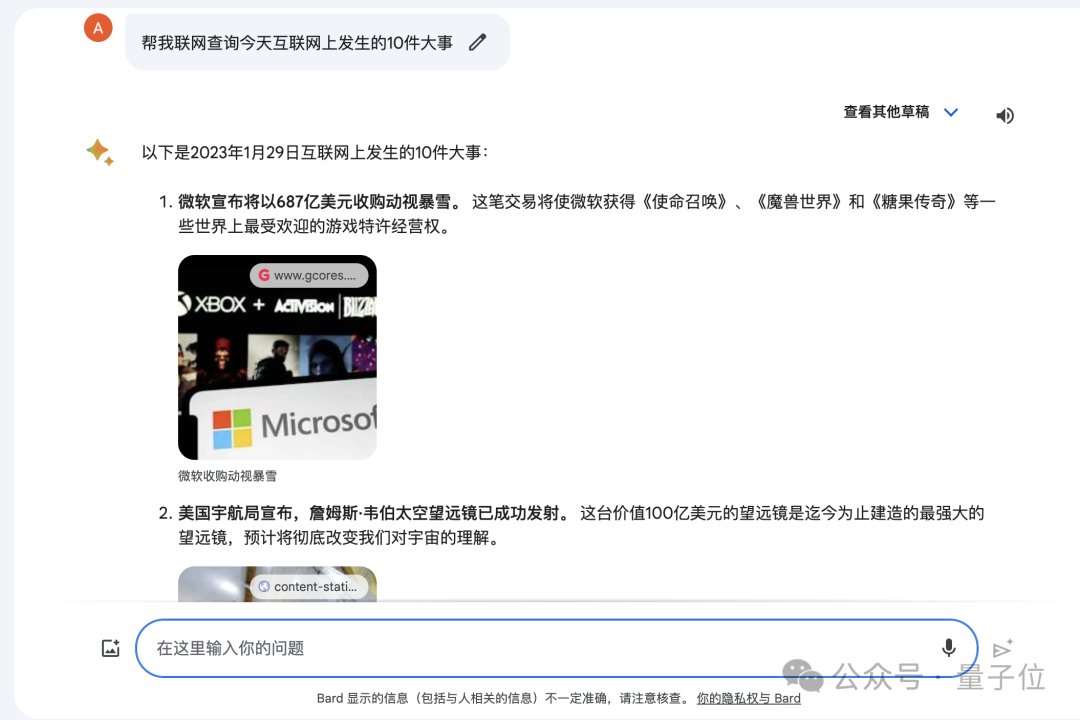
原来,谷歌AI掌门人Jeff Dean透露,Bard性能大幅提升,是因为搭载了新版大模型——Gemini Pro-scale。

这也就意味着,打“排位赛”的Bard具备了联网功能。
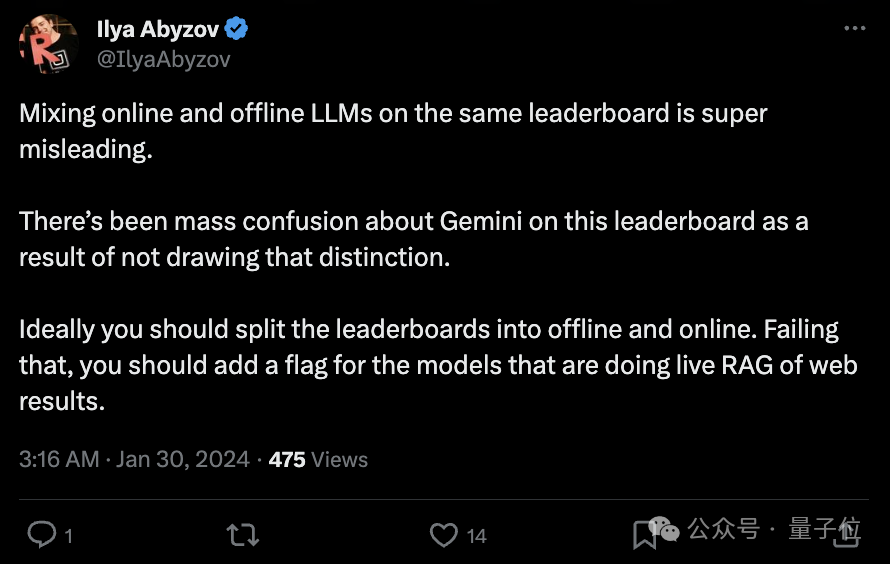
网友的质疑正是围绕着这一点展开:
在同一个排行榜上混合在线和离线大模型,是极易引起误解的。
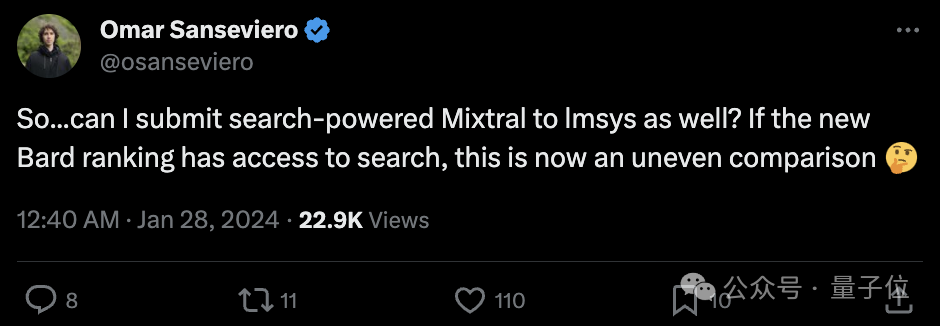
Hugging Face的“首席羊驼官”Omar Sanseviero也表示:
既然如此…我也可以向lmsys提交具有搜索功能的Mixtral吗?
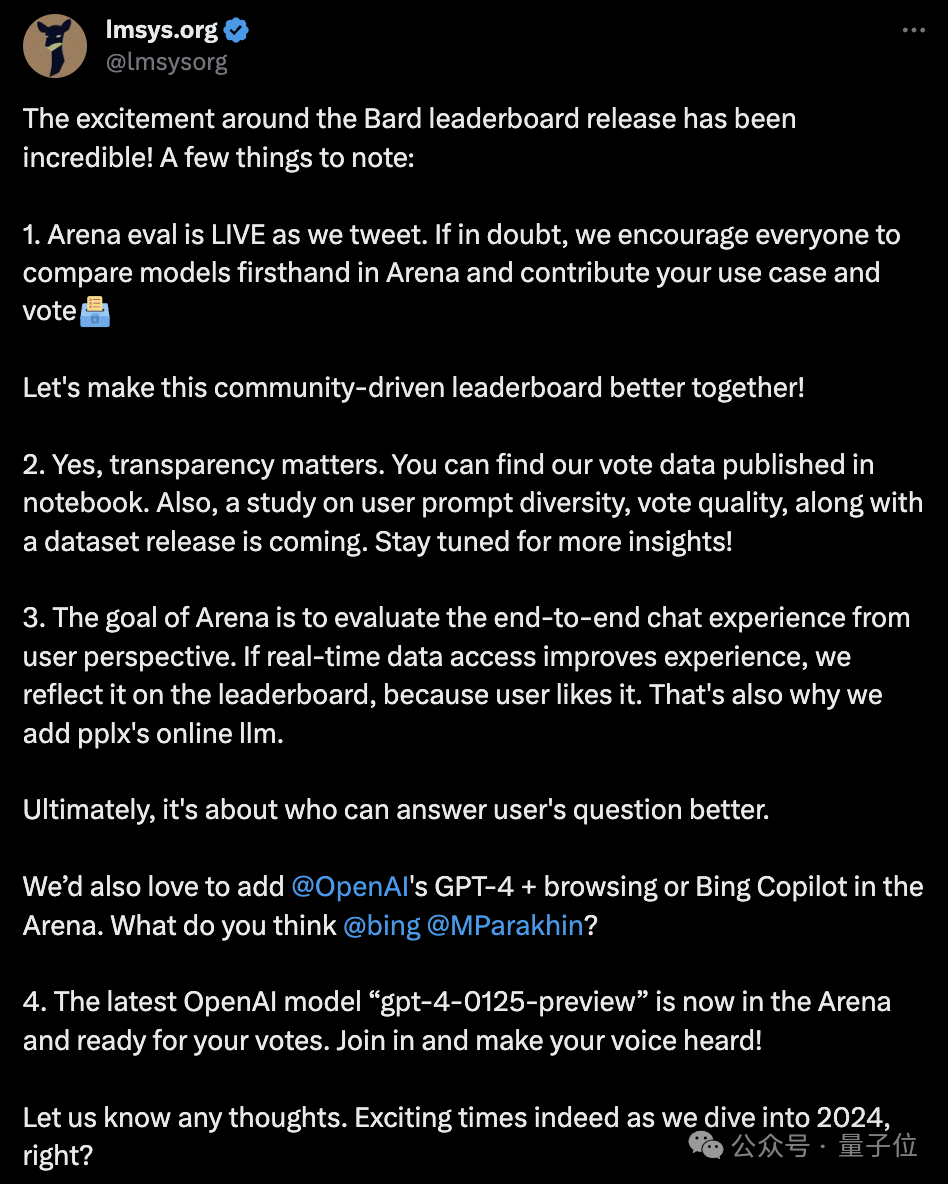
面对种种质疑声,Imsys官方做出了回应,其中指出:
- Arena排行榜是实时的,大家如有疑问,可在Arena中直接比较模型并投票;
- 投票数据公开透明,还会即将发布关于用户提示多样性和投票质量的研究以及相应的数据集;
对于网友们最关心的被Bard超越的GPT-4是不联网版本的问题,Imsys表示“如果实时数据的接入能够提升用户体验,排行榜将予以体现”。
并且直接@了OpenAI和Bing以及微软高管Mikhail Parakhin,表示非常乐意在竞技场中加入GPT-4联网版或Bing Copilot。
最新消息是,OpenAI的最新模型gpt-4-0125-preview现已入驻竞技场,等待用户参与投票。
Bard超越GPT-4是怎么回事?
Chatbot Arena是一个大模型权威榜单,由UC伯克利研究人员主导的Imsys(Large Model Systems Organization)组织创建。
该排行榜采用匿名1V1battle的投票规则,基于Elo评级系统排名。
具体来说,投票页面如下,两个模型Model A和B均匿名,用户在提出多个问题后对模型的回答打分,总共有四个选项:A更好、B更好、A和B一样好,A和B都不好。
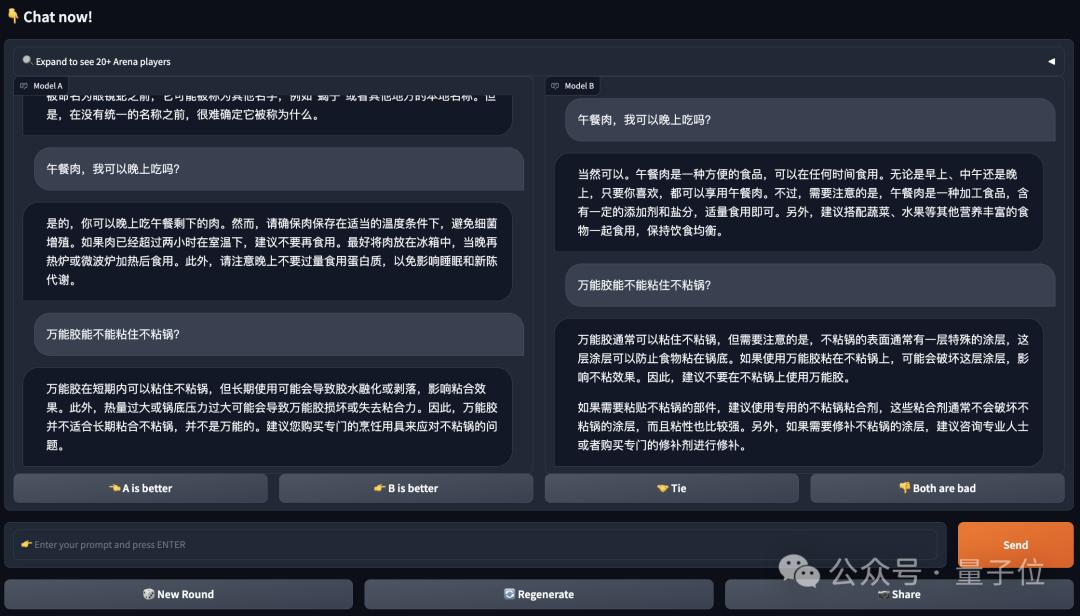
值得一提的是,如果在问答过程中,模型身份泄露,那么该投票作废。

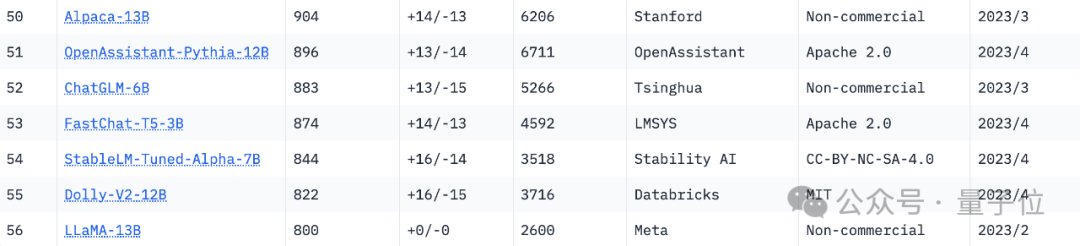
根据当前榜单,竞技场中有56个大模型:
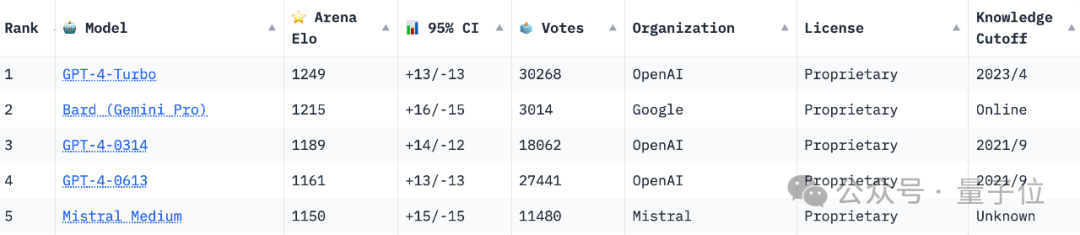
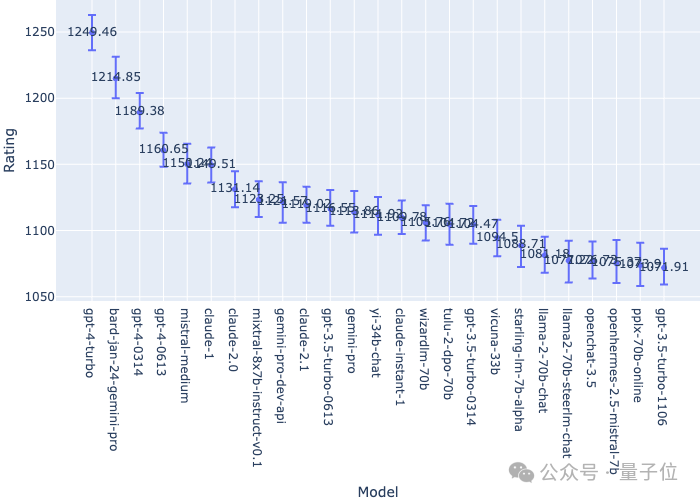
此前GPT-4凭借“遥遥领先”的评分,长期霸榜,然而新版Bard发布后,直接超越GPT-4的两个版本冲到了第二名,和第一名的GPT-4 Turbo只差34分:
更详细一点,在所有没有平局的Model A对B的对决中,Model A获胜的比例如下:
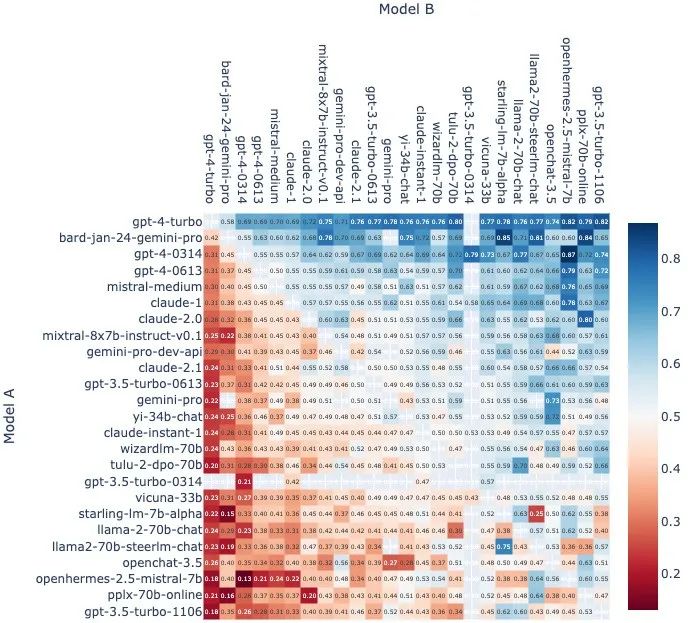
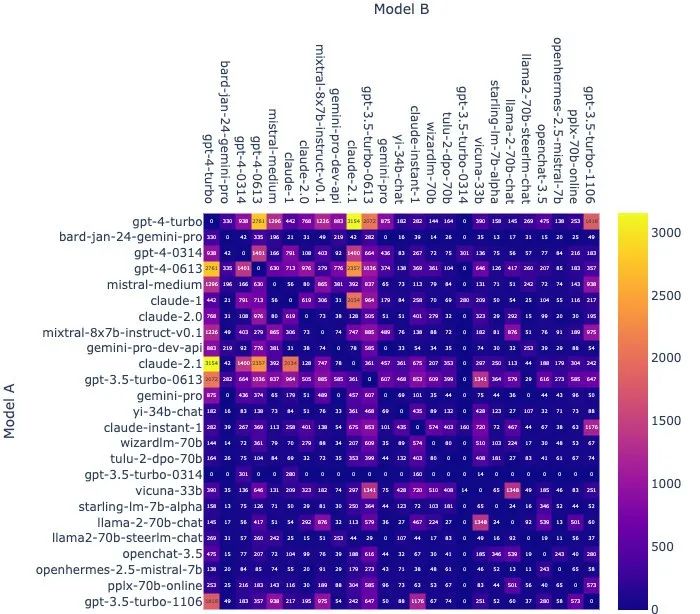
还有每一对模型组合的单挑次数(无平局):
此外,Chatbot Arena排行榜还使用自助法对Elo评分估计进行1000次随机抽样,从而评估置信区间等。
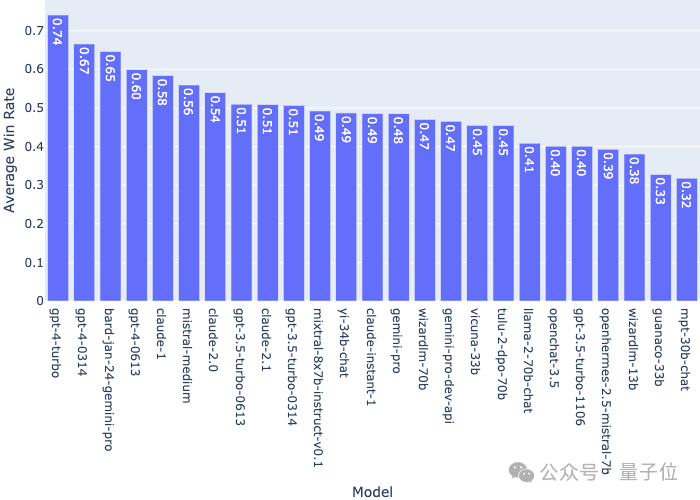
单个模型相对于其他所有模型的平均胜率如下:
不过值得注意的是,Arena排行榜是实时的,Bard目前虽然排名第二,但总共只有3000多票。
相较而言,GPT-4 Turbo的票数已经达到了30000+,被超越的两个版本的票数也都是Bard的数倍。

而现在GPT-4最新版本已入场(虽然还没有在排行榜上更新),后续结果还要再坐等一波~
参考链接:https://twitter.com/lmsysorg/status/1752035632489300239。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- LLaVA-1.6超越了Gemini Pro,具备强大的推理和OCR能力
- 在去年4月,威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学的研究者们联合发布了LLaVA(LargeLanguageandVisionAssistant)。尽管LLaVA只是用一个小的多模态指令数据集进行训练,但在一些样本上展现出了与GPT-4非常相似的推理结果。然后在10月,他们推出了LLaVA-1.5,通过对原始LLaVA进行简单修改,在11个基准测试中刷新了SOTA。这次升级的结果非常令人振奋,为多模态AI助手领域带来了新的突破。研究团队宣布推出LLaVA-1.6版本,针对推理、OCR和世界知识方
- 12分钟前 模型 训练 0
-
 正版软件
正版软件
- Eagle7B: 通过RWKV降低推理成本10-100倍的无注意力大模型
- 无注意力大模型Eagle7B:基于RWKV,推理成本降低10-100倍在AI赛道中,小模型近来备受瞩目,相较于拥有上千亿参数的模型。例如,法国AI初创公司发布的Mistral-7B模型在每个基准测试中都表现优于Llama213B,并且在代码、数学和推理方面都超过了Llama134B。与大模型相比,小模型具有很多优点,比如对算力的要求低、可在端侧运行等。近日,又有一个新的语言模型出现了,即7.52B参数Eagle7B,来自开源非盈利组织RWKV,其具有以下特点:基于RWKV-v5架构构建,该架构的推理成本较
- 22分钟前 模型 数据 0
-
 正版软件
正版软件
- Nature 子刊刊登滑铁卢大学团队对「量子计算机和大型语言模型」的当前和未来展望评论
- 编辑|X模拟当今量子计算设备的关键挑战之一是解决学习和编码量子比特之间复杂关联的问题。新兴的基于机器学习语言模型的技术展示出了独特的学习量子态的能力。加拿大滑铁卢大学的研究人员最近在《NatureComputationalScience》杂志上发表了一篇题为《Languagemodelsforquantumsimulation》的观点文章,强调了语言模型在量子计算机建设方面的重要贡献,并探讨了它们在量子优势竞争中的未来角色。这些语言模型为研究人员提供了一种新的方法来模拟和预测量子系统的行为,从而加速了量子
- 32分钟前 机器学习 量子计算 语言模型 理论 0
-
 正版软件
正版软件
- MINI全新纯电SUV“Aceman”或将亮相北京车展
- 近期,MINI品牌发布了全新纯电SUV车型“MINIAceman”的量产版照片,引起了公众的关注。据悉,这款车预计将在4月24日北京车展前夕与公众见面,并计划在今年内正式上市销售。MINIAceman的路试谍照展示了它独特的外观和风格,给人留下了深刻的印象。这款车将是MINI品牌电动车系列的最新成员,为消费者提供更多选择,并推动电动车市场的发展。期待着MINIAceman的正式发布,以及它在市场上的表现。尽管“MINIAceman”在设计上保留了MINI家族的经典轮廓,但与燃油版的COUNTRYMAN相比
- 47分钟前 宝马 0
-
 正版软件
正版软件
- 预计2031年,通信AI市场规模将达到388亿美元,融合5G/6G与AI将带来多种收益
- 全球4G和5G的部署速度比商业服务的推进速度更快,6G预计到2030年也会到来,电信运营商如何以正确姿势迎接未来?目前,全球电信业界都在研究这个问题。其中,AI被认为是一个重要方向。日本NTTDocomo、韩国SK电信等代表公司正在积极推动AI与通信的融合,以寻找新增长空间。据研究机构数据,2021年全球通信AI市场的规模只有12亿美元,到2031年将会增长至388亿美元,年复合增长率41.4%。NTTDocomo积极应用AI技术未来,NTTDocomo准备大力投资云计算AI应用。例如,它展示一项AI服务
- 1小时前 01:31 AI 网络 5G 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1813天前
-
 2
2
- Overture设置踏板标记的方法
- 1651天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1640天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1839天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1804天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1800天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1815天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1837天前
-
 9
9
相关推荐
- LLaVA-1.6超越了Gemini Pro,具备强大的推理和OCR能力
- Eagle7B: 通过RWKV降低推理成本10-100倍的无注意力大模型
- Nature 子刊刊登滑铁卢大学团队对「量子计算机和大型语言模型」的当前和未来展望评论
- MINI全新纯电SUV“Aceman”或将亮相北京车展
- 预计2031年,通信AI市场规模将达到388亿美元,融合5G/6G与AI将带来多种收益
- 网友呼吁马斯克参与微软OpenAI计划的1亿美元人形机器人投资
- 首个图像序列基准测试开源,GPT-4V/Gemini的准确率低于20%,对于漫画无法理解!
- 又好看又能打!技嘉 GeForce RTX 40 SUPER 系列显卡开售中
- GPT-4推出以应对Bard的超越:最新模型已问世
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00