Eagle7B: 通过RWKV降低推理成本10-100倍的无注意力大模型
 发布于2024-11-28 阅读(0)
发布于2024-11-28 阅读(0)
扫一扫,手机访问
无注意力大模型Eagle7B:基于RWKV,推理成本降低10-100 倍
在AI赛道中,小模型近来备受瞩目,相较于拥有上千亿参数的模型。例如,法国AI初创公司发布的Mistral-7B模型在每个基准测试中都表现优于Llama 2 13B,并且在代码、数学和推理方面都超过了Llama 1 34B。
与大模型相比,小模型具有很多优点,比如对算力的要求低、可在端侧运行等。
近日,又有一个新的语言模型出现了,即 7.52B 参数 Eagle 7B,来自开源非盈利组织 RWKV,其具有以下特点:

- 基于 RWKV-v5 架构构建,该架构的推理成本较低(RWKV 是一个线性 transformer,推理成本降低 10-100 倍以上);
- 在 100 多种语言、1.1 万亿 token 上训练而成;
- 在多语言基准测试中优于所有的 7B 类模型;
- 在英语评测中,Eagle 7B 性能接近 Falcon (1.5T)、LLaMA2 (2T)、Mistral;
- 英语评测中与 MPT-7B (1T) 相当;
- 没有注意力的 Transformer。

Eagle 7B是基于RWKV-v5架构构建而成的。RWKV(Receptance Weighted Key Value)是一种结合了RNN和Transformer的优点,并规避了它们的缺点的新颖架构。它的设计非常精良,能够缓解Transformer在内存和扩展方面的瓶颈问题,实现更有效的线性扩展。同时,RWKV还保留了让Transformer在该领域占据主导地位的一些性质。
目前RWKV已经迭代到第六代RWKV-6,性能与大小与Transformer相似。未来研究者可利用该架构创造更高效的模型。
关于 RWKV 更多信息,大家可以参考「Transformer 时代重塑 RNN,RWKV 将非 Transformer 架构扩展到数百亿参数」。
值得一提的是,RWKV-v5 Eagle 7B 可以不受限制地供个人或商业使用。
在 23 种语言上的测试结果
不同模型在多语言上的性能如下所示,测试基准包括 xLAMBDA、xStoryCloze、xWinograd、xCopa。
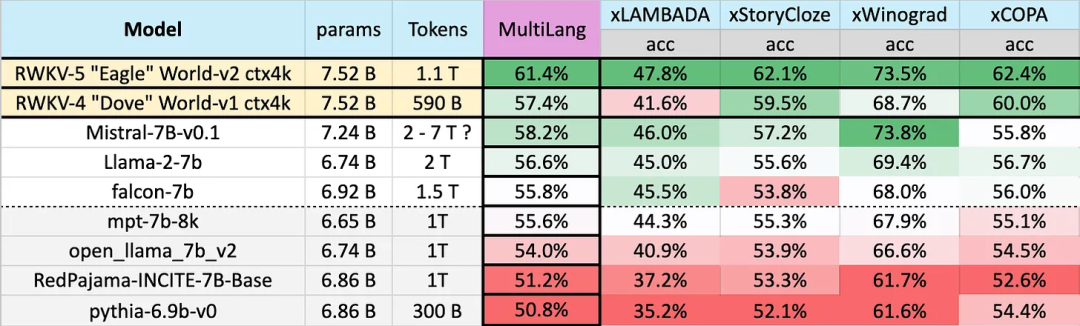
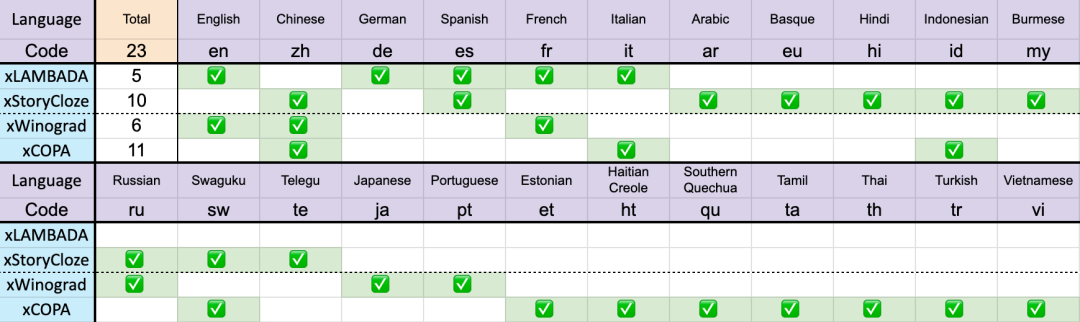
共 23 种语言
这些基准测试包含了大部分常识推理,显示出 RWKV 架构从 v4 到 v5 在多语言性能上的巨大飞跃。不过由于缺乏多语言基准,该研究只能测试其在 23 种较常用语言上的能力,其余 75 种以上语言的能力目前仍无法得知。
在英语上的性能
不同模型在英语上的性能通过 12 个基准来判别,包括常识性推理和世界知识。

从结果可以再次看出 RWKV 从 v4 到 v5 架构的巨大飞跃。v4 之前输给了 1T token 的 MPT-7b,但 v5 却在基准测试中开始追上来,在某些情况下(甚至在某些基准测试 LAMBADA、StoryCloze16、WinoGrande、HeadQA_en、Sciq 上)它可以超过 Falcon,甚至 llama2。
此外,根据给定的近似 token 训练统计,v5 性能开始与预期的 Transformer 性能水平保持一致。
此前,Mistral-7B 利用 2-7 万亿 Token 的训练方法在 7B 规模的模型上保持领先。该研究希望缩小这一差距,使得 RWKV-v5 Eagle 7B 超越 llama2 性能并达到 Mistral 的水平。
下图表明,RWKV-v5 Eagle 7B 在 3000 亿 token 点附近的 checkpoints 显示出与 pythia-6.9b 类似的性能:
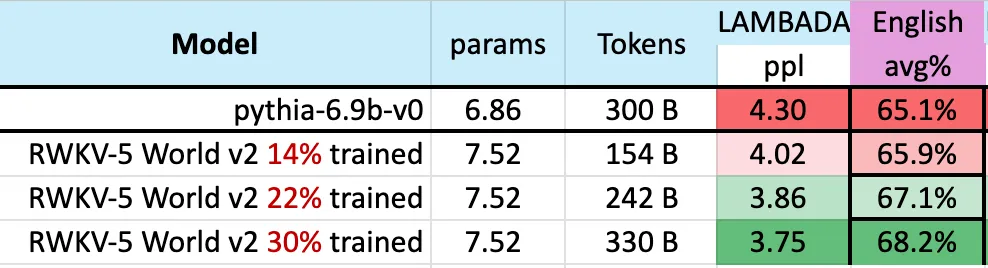
这与之前在 RWKV-v4 架构上进行的实验(pile-based)一致,像 RWKV 这样的线性 transformers 在性能水平上与 transformers 相似,并且具有相同的 token 数训练。
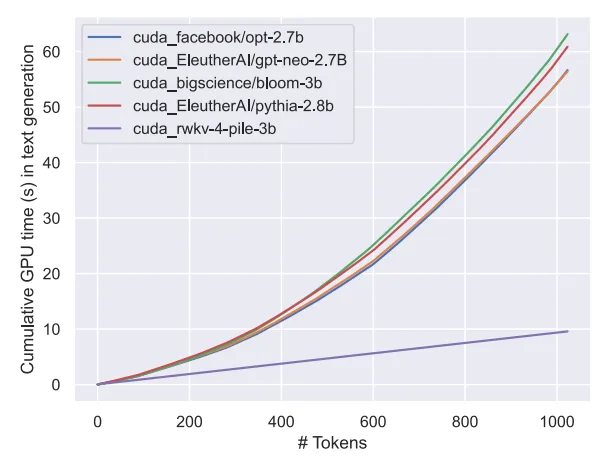
可以预见,该模型的出现标志着迄今为止最强的线性 transformer(就评估基准而言)已经来了。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 颠覆GPT-4的开源模型曝光!Mistral老板确认:正式版将更加强大
- Mistral-Medium竟然意外泄露?此前仅能通过API获得,性能直逼GPT-4。CEO最新发声:确有其事,系早期客户员工泄露。但仍表示敬请期待。图片换句话说,这个版本尚且还是旧的,实际版本性能还会更好。这两天,这个名叫“Miqu”的神秘模型在大模型社区里炸了锅,不少人还怀疑这是LIama的微调版本。图片MistralCEO解释说,他们对MistralMedium进行了重新训练,基于Llama2的基础上进行了改进。这是为了尽快向早期客户提供接近GPT-4性能的API。预训练工作在Mistral7B发布
- 3分钟前 模型 GPT-4 开源 0
-
 正版软件
正版软件
- 马斯克与擎天柱一同散步
- 特斯拉机器人叠衣服刚掀热潮,短短几天,马斯克又晒擎天柱“散步”视频,再次引来大量网友围观。只见偌大的工厂里,擎天柱悠哉悠哉的一步两步,首先可以肯定的是没有顺拐:腿部动作比之前更自然一些,速度也比以前快了不少:也可以看到脚后跟先着地这样的细节处理:总的来说,主打一个字“稳”,步态似乎更接近人类了:短短十几秒视频,激起网友们热烈讨论。英伟达机器学习专家BojanTunguz化用阿姆斯特朗登月时的名言,称:对一个机器人来说这是一小步,但对“机器人类”(robotkind)来说却是巨大的飞跃。毕竟,之前擎天柱走起
- 8分钟前 模型 AI 0
-
 正版软件
正版软件
- 谷歌安卓 15 将提供新功能:Auracast 页面,实现音频共享至附近设备
- 本站2月1日消息,根据国外科技媒体AndroidAuthority报道,谷歌计划在安卓15系统中,开辟专门的音频分享界面,凸显Auracast功能,方便用户向就近设备共享媒体音频。蓝牙特别兴趣小组于2022年宣布了Auracast功能,这是一种即将推出的蓝牙广播功能,旨在提升无线音频体验。Auracast将赋予用户与朋友和家人共享音频的能力,为他们带来更加丰富的互动体验。这一创新功能有望开启全新的无线音频时代,让人们更加轻松地分享和欣赏音乐、播客等内容。该功能以前被称为AudioSharing,随后更改为
- 23分钟前 谷歌 安卓 0
-
 正版软件
正版软件
- 思特威推出新品SC5000CS手机图像传感器,有效降低暗场噪声
- 2月1日,CMOS图像传感器供应商思特威发布了一款专为手机设计的5000万像素图像传感器SC5000CS。这一最新研发成果将为手机摄影带来更高质量的图像拍摄能力。这款新型的背照式(BSI)传感器采用了0.702μm像素尺寸设计,并集成了思特威独家的SFCPixel-SL技术。通过SFCPixel专利技术架构的进一步优化,该技术创新地在像素内实现了双转换增益设计,从而显著提升了传感器的动态范围,并在暗场环境下展现出更低的噪声表现。传感器尺寸为1/2.5英寸,非常适合用作智能手机的主摄像头,并且支持PDAF相
- 38分钟前 思特威 0
-
 正版软件
正版软件
- 奇瑞推出全新政策:二手车官方认证可享受终身质保服务
- 奇瑞汽车宣布,自2024年2月1日起,符合条件的“官方认证二手车”也可享受终身质保。这一政策的推出为消费者带来了更多的利好。作为其“全系车型整车终身质保”政策实施一周年的庆祝活动,奇瑞汽车再次展示了对消费者的关注和承诺。这一举措将进一步提升二手车购买的信心,为消费者提供更加可靠和放心的选择。奇瑞汽车于2022年发布了“官方认证二手车”标准,要求车龄不超过8年,行驶里程不超过15万公里,且无重大事故、火烧、泡水等情况。符合标准的车辆可以被认定为“官方认证二手车”,享有原厂提供的1年或2万公里保修服务,以及免
- 53分钟前 奇瑞 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1814天前
-
 2
2
- Overture设置踏板标记的方法
- 1651天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1640天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1839天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1805天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1801天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1816天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1837天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00