UCLA华人创新自我对弈方式:LLM自主训练超越GPT-4,在专家指导下取得卓越成果
 发布于2024-11-28 阅读(0)
发布于2024-11-28 阅读(0)
扫一扫,手机访问
合成数据已经成为了大语言模型进化之路上最重要的一块基石了。
去年底,有网友曝出前OpenAI首席科学家Ilya多次表示LLM的发展没有数据瓶颈,合成数据可以解决大部分问题。
 图片
图片
英伟达高级科学家Jim Fan在研究了最新一批论文后得出结论,他认为将合成数据与传统游戏和图像生成技术相结合,可以让LLM实现巨大的自我进化。
 图片
图片
而正式提出这个方法的论文,是由来自UCLA的华人团队。
 图片
图片
论文地址:https://arxiv.org/abs/2401.01335v1
他们使用自我对弈机制(SPIN)生成合成数据,并通过自我微调的方法,不依赖新的数据集,将性能较弱的LLM在Open LLM Leaderboard Benchmark上的平均分从58.14提升至63.16。
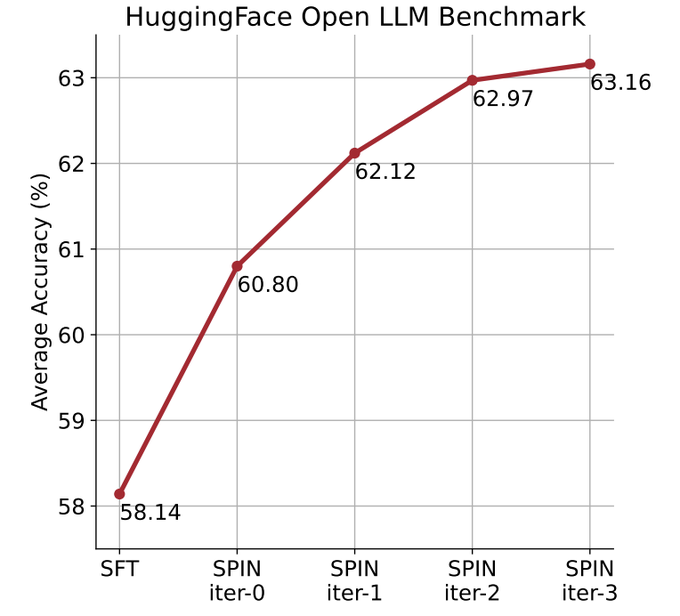
研究人员提出了一种名为SPIN的自我微调的方法,通过自我对弈的方式——LLM与其前一轮迭代版本进行对抗,从而逐步提升语言模型的性能。
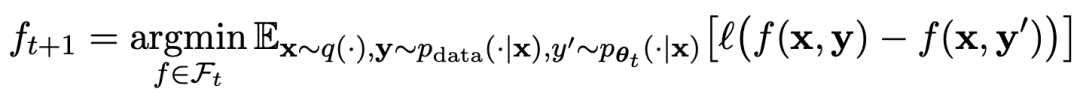 图片
图片
这样就无需额外的人类标注数据或更高级语言模型的反馈,也能完成模型的自我进化。
主模型和对手模型的参数完全一致。用两个不同的版本进行自我对弈。
对弈过程用公式可以概括为:
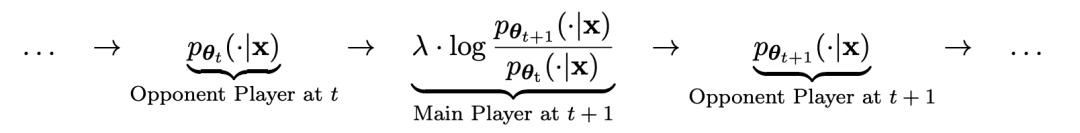 图片
图片
自我对弈的训练方式,总结起来思路大概是这样:
通过训练主模型来区分对手模型生成的响应和人类目标响应,对手模型是轮迭代获得的语言模型,目标是生成尽可能难以区分的响应。
假设第t轮迭代得到的语言模型参数为θt,则在第t+1轮迭代中,使用θt作为对手玩家,针对监督微调数据集中每个prompt x,使用θt生成响应y'。
然后优化新语言模型参数θt+1,使其可以区分y'和监督微调数据集中人类响应y。如此可以形成一个渐进的过程,逐步逼近目标响应分布。
这里,主模型的损失函数采用对数损失,考虑y和y'的函数值差。
对手模型加入KL散度正则化,防止模型参数偏离太多。
具体的对抗博弈训练目标如公式4.7所示。从理论分析可以看出,当语言模型的响应分布等于目标响应分布时,优化过程收敛。
如果使用对弈之后生成的合成数据进行训练,再使用SPIN进行自我微调,能有效提高LLM的性能。
 图片
图片
但之后在初始的微调数据上再次简单地微调却又会导致性能下降。
而SPIN仅需要初始模型本身和现有的微调数据集,就能使得LLM通过SPIN获得自我提升。
特别是,SPIN甚至超越了通过DPO使用额外的GPT-4偏好数据训练的模型。
 图片
图片
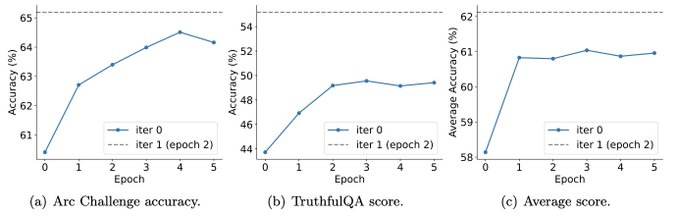
而且实验还表明,迭代训练比更多epoch的训练能更加有效地提升模型性能。
 图片
图片
延长单次迭代的训练持续时间不会降低SPIN的性能,但会达到极限。
迭代次数越多,SPIN的效果的就越明显。
网友在看完这篇论文之后感叹:
合成数据将主宰大语言模型的发展,对于大语言模型的研究者来说将会是非常好的消息!
 图片
图片
自我对弈让LLM能不断提高
具体来说,研究人员开发的SPIN系统,是由两个相互影响的模型相互促进的系统。
用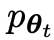 表示的前一次迭代t的LLM,研究人员使用它来生成对人工注释的SFT数据集中的提示x的响应y。
表示的前一次迭代t的LLM,研究人员使用它来生成对人工注释的SFT数据集中的提示x的响应y。
接下来的目标是找到一个新的LLM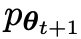 ,能够区分
,能够区分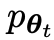 生成的响应y和人类生成的响应y'。
生成的响应y和人类生成的响应y'。
这个过程可以看作是一个两人游戏:
主要玩家或新的LLM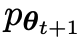 试图辨别对手玩家的响应和人类生成的响应,而对手或旧的LLM
试图辨别对手玩家的响应和人类生成的响应,而对手或旧的LLM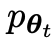 生成响应与人工注释的SFT数据集中的数据尽可能相似。
生成响应与人工注释的SFT数据集中的数据尽可能相似。
通过对旧的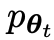 进行微调而获得的新LLM
进行微调而获得的新LLM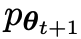 更喜欢
更喜欢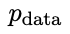 的响应,从而产生与
的响应,从而产生与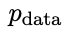 更一致的分布
更一致的分布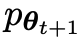 。
。
在下一次迭代中,新获得的LLM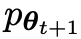 成为响应生成的对手,自我对弈过程的目标是LLM最终收敛到
成为响应生成的对手,自我对弈过程的目标是LLM最终收敛到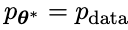 ,使得最强的LLM不再能够区分其先前生成的响应版本和人类生成的版本。
,使得最强的LLM不再能够区分其先前生成的响应版本和人类生成的版本。
如何使用SPIN提升模型性能
研究人员设计了个两人游戏,其中主要模型的目标是区分LLM生成的响应和人类生成的响应。与此同时,对手的作用是产生与人类的反应无法区分的反应。研究人员的方法的核心是训练主要模型。
首先说明如何训练主要模型来区分LLM的回复和人类的回复。
研究人员方法的核心是自我博弈机制,其中主玩家和对手都是相同的LLM,但来自不同的迭代。
更具体地说,对手是上一次迭代中的旧LLM,而主玩家是当前迭代中要学习的新LLM。在迭代t+1时包括以下两个步骤:(1)训练主模型,(2)更新对手模型。
训练主模型
首先,研究人员将说明如何训练主玩家区分LLM反应和人类反应。受积分概率度量(IPM)的启发,研究人员制定了目标函数:
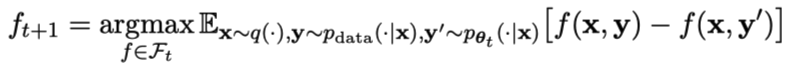 图片
图片
更新对手模型
对手模型的目标是找到更好的LLM,使其产生的响应与主模型的p数据无异。
实验
SPIN有效提升基准性能
研究人员使用HuggingFace Open LLM Leaderboard作为广泛的评估来证明 SPIN的有效性。
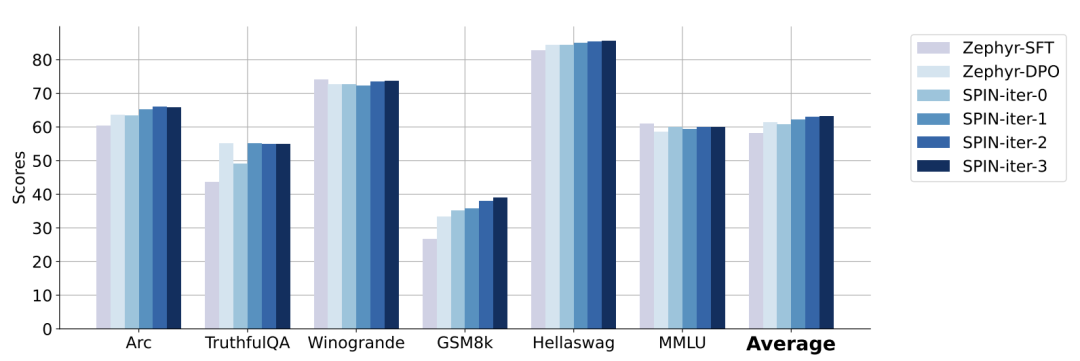
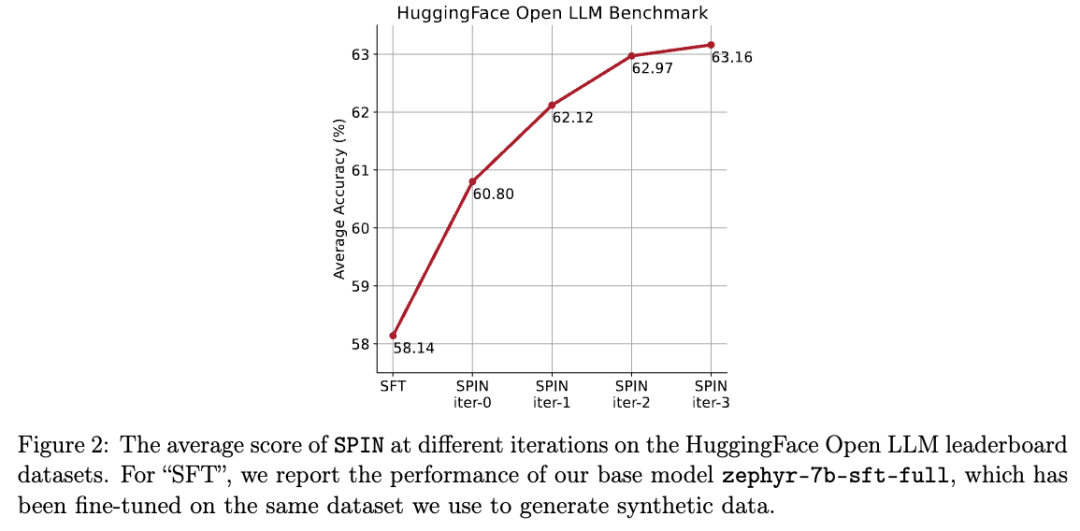
在下图中,研究人员将经过0到3次迭代后通过SPIN微调的模型与基本模型zephyr-7b-sft-full的性能进行了比较。
研究人员可以观察到,SPIN通过进一步利用SFT数据集,在提高模型性能方面表现出了显着的效果,而基础模型已经在该数据集上进行了充分的微调。
在第0次迭代中,模型响应是从zephyr-7b-sft-full生成的,研究人员观察到平均得分总体提高了2.66%。
在TruthfulQA和GSM8k基准测试中,这一改进尤其显着,分别提高了超过5%和10%。
在迭代1中,研究人员采用迭代0中的LLM模型来生成SPIN的新响应,遵循算法1中概述的过程。
此迭代平均产生1.32%的进一步增强,在Arc Challenge和TruthfulQA基准测试中尤其显着。
随后的迭代延续了各种任务增量改进的趋势。同时,迭代t+1时的改进自然更小
 图片
图片
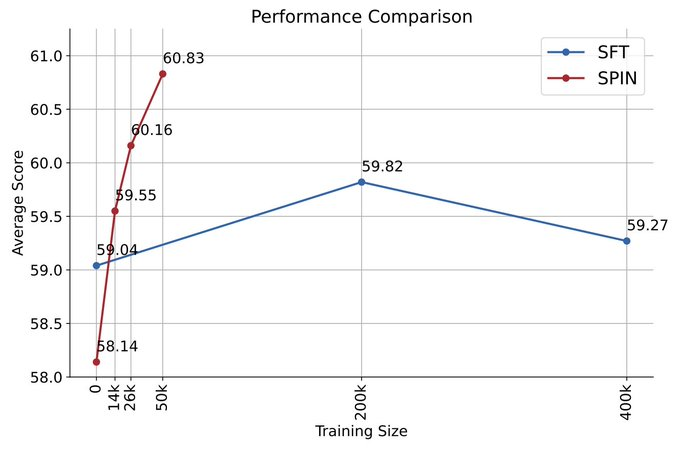
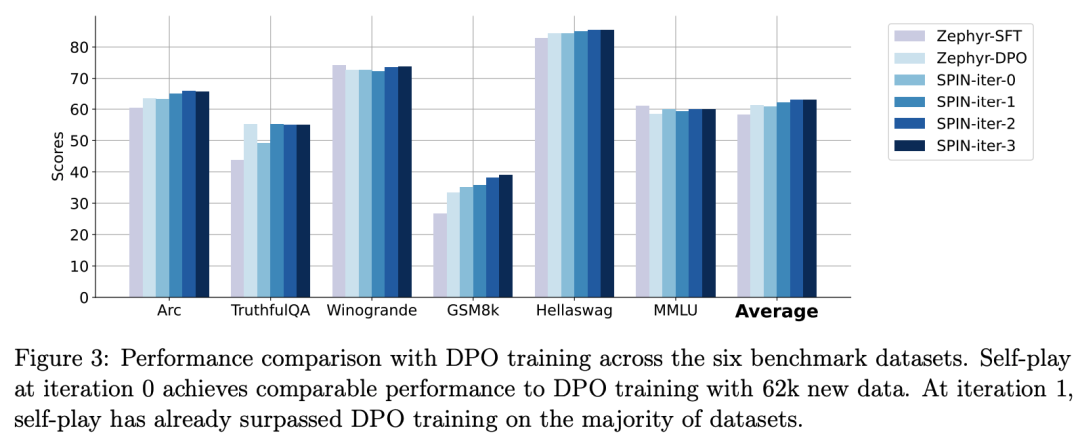
zephyr-7b-beta是从zephyr-7b-sft-full衍生出来的模型,使用DPO在大约62k个偏好数据上训练而成。
研究人员注意到,DPO需要人工输入或高级语言模型反馈来确定偏好,因此数据生成是一个相当昂贵的过程。
相比之下,研究人员的SPIN只需要初始模型本身就可以。
此外,与需要新数据源的DPO不同,研究人员的方法完全利用现有的SFT数据集。
下图显示了SPIN在迭代0和1(采用50k SFT数据)与DPO训练的性能比较。
 图片
图片
研究人员可以观察到,虽然DPO利用了更多新来源的数据,但基于现有SFT数据的SPIN从迭代1开始,SPIN甚至超过了DPO的性能、SPIN在排行榜基准测试中的表现甚至超过了DPO。
参考资料:
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 苹果Vision Pro高级VR头显遭遇丢失难题:无法定位跟踪,远程锁定成唯一解决方案
- 根据最新的苹果官方支持文档更新,有关其高端头显设备VisionPro在“FindMy”功能上的支持存在一些不完善之处。这款售价高达3499美元的设备,如果不慎丢失,用户将无法通过“FindMy”服务进行定位追踪,从而增加了设备丢失后无法找回的风险。尽管VisionPro拥有许多令人印象深刻的功能和性能,但这一点确实值得用户注意。因此,苹果可能在未来通过软件更新来改进这一问题,以提供更完善的设备定位和追踪功能。根据苹果官方文档描述,当用户不慎遗失VisionPro头显时,可以远程启动“FindMy”中的保护
- 6分钟前 苹果 0
-
 正版软件
正版软件
- 威联通推出全新企业级NAS TS-h3077AFU:强大性能,满足多种存储需求
- 威联通(QNAP)近日发布了一款新的企业级NAS,型号为TS-h3077AFU。这款NAS具备30个盘位,并可选配AMD嵌入式锐龙7Ryzen7000系列处理器,为企业用户提供强大的存储和数据处理能力。TS-h3077AFU系列提供了两个配置选项,分别是TS-h3077AFU-R7-64G和TS-h3077AFU-R5-32G。前者的售价为5699美元,配置了一颗8核16线程的AMD锐龙77000系列处理器,最高睿频可达5.3GHz,并搭配了64GBUDIMMDDR5内存(支持ECC内存)。后者的售价为4
- 16分钟前 威联通 0
-
 正版软件
正版软件
- 完整指南:苹果Vision Pro头显的旅行和存储策略
- 苹果公司今日更新了VisionPro头显设备的支持文档,提供了详尽的使用细节。文档包含了头显的携带方式、旅行模式的启用以及长期存储的实用指南等多个方面。苹果公司为那些希望携带VisionPro出行的用户提供了一些具体的建议。在携带过程中,用户应该避免将可能产生划痕的物品如钥匙、硬币等与头显放在一起,以防止内部显示屏受损。此外,苹果建议用户使用专用的AppleVisionPro旅行箱或类似的保护装置,确保头显在旅途中不会受到撞击和过度振动的损害。如果长时间不使用VisionPro,用户应将其与电池断开连接,
- 31分钟前 苹果 0
-
 正版软件
正版软件
- 上海网信办约谈“半天妖烤鱼”要求其不得限制消费者注册会员才能点餐
- 本站2月2日消息,据上海网信办官方消息,根据网民举报并经核实,餐饮连锁企业“半天妖烤鱼”在消费者扫码点餐过程中,微信小程序存在误导消费者认为必须先注册会员才能点餐、索取非必要的手机号且首次使用未主动弹窗告知消费者收集使用个人信息规则等违法违规行为。▲图源网信上海公众号2月2日下午,上海市网信办依法约谈了“半天妖烤鱼”运营企业上海半天妖餐饮管理有限公司的负责人。约谈的目的是要求企业立即进行整改,并要求企业对照问题进行举一反三的自查和自纠,将个人信息保护放在企业运营的重要位置上。对此,企业负责人表示将认真履行
- 46分钟前 网信办 0
-
 正版软件
正版软件
- 中石油正式加入昊铂免费充电联盟,昊铂全系车主将永久受益
- 2月2日消息,昊铂品牌官方今日宣布喜讯,中石油正式加入昊铂免费充电联盟,为昊铂所有车主提供终身免费充电服务。春节期间,许多新能源车主在高速公路上再次陷入里程焦虑和充电焦虑困扰。中石油的加入将有效解决这一问题,为车主们提供更便捷的充电服务,为他们的回家过年之旅带来更多的便利和安心。为了解决这一问题,昊铂一直致力于成为新能源补能无忧的领军品牌。他们的目标是推动新能源汽车行业进入“补能0焦虑”时代。为了实现这一目标,中石油正式加入昊铂免费充电联盟。从现在开始,昊铂的全系车主可以在中石油旗下的充电站内享受终身免费
- 1小时前 17:50 昊铂 0













