通过批评学习,1317条评语帮助LLaMA2大幅提高胜率
 发布于2024-11-29 阅读(0)
发布于2024-11-29 阅读(0)
扫一扫,手机访问
现有的大模型对齐方法包括基于示例的监督微调(SFT)和基于分数反馈的强化学习(RLHF)。然而,分数只能反应当前回复的好坏程度,并不能明确指出模型的不足之处。相较之下,我们人类通常是从语言反馈中学习并调整自己的行为模式。就像审稿意见不仅仅是一个分数,还包括许多接受或者拒绝的理由。
那么,大语言模型能否也像人类一样利用语言反馈来改善自身呢?
香港中文大学和腾讯AI Lab的研究者们最近提出了一项名为对比式非似然训练(Contrastive Unlikelihood Learning,CUT)的创新研究。该研究利用语言反馈来调整语言模型,使其能够像人类一样从不同的批评意见中学习和进步。这项研究旨在提高语言模型的质量和准确性,使其更符合人类思维方式。通过对比非似然训练,研究者们希望能够让语言模型更好地理解和适应多样化的语言使用情境,从而提高其在自然语言处理任务中的性能。这一创新研究有望为语言模型
CUT是一种简单而有效的方法。仅通过使用1317条语言反馈数据,CUT能够大幅提升LLaMA2-13b在AlpacaEval上的胜率,从1.87%飙升至62.56%,并成功击败了175B的DaVinci003。令人兴奋的是,CUT还能像其他强化学习与强化学习强化反馈(RLHF)框架一样进行探索、批评和改进的循环迭代。在这一过程中,批评阶段可以由自动评价模型完成,实现整个系统的自我评估和提升。
作者对 LLaMA2-chat-13b 进行了四轮迭代,将模型在 AlpacaEval 上的性能从 81.09% 逐步提升至 91.36%。相较于基于分数反馈的对齐技术(DPO),CUT 在同等数据规模下表现更佳。研究结果揭示了语言反馈在对齐领域具有巨大的发展潜力,为未来的对齐研究开辟了新的可能性。这一发现对于提高对齐技术的精确性和效率具有重要意义,并为实现更好的自然语言处理任务提供了指导。

- 论文标题:Reasons to Reject? Aligning Language Models with Judgments
- 论文链接:https://arxiv.org/abs/2312.14591
- Github 链接:https://github.com/wwxu21/CUT
大模型的对齐
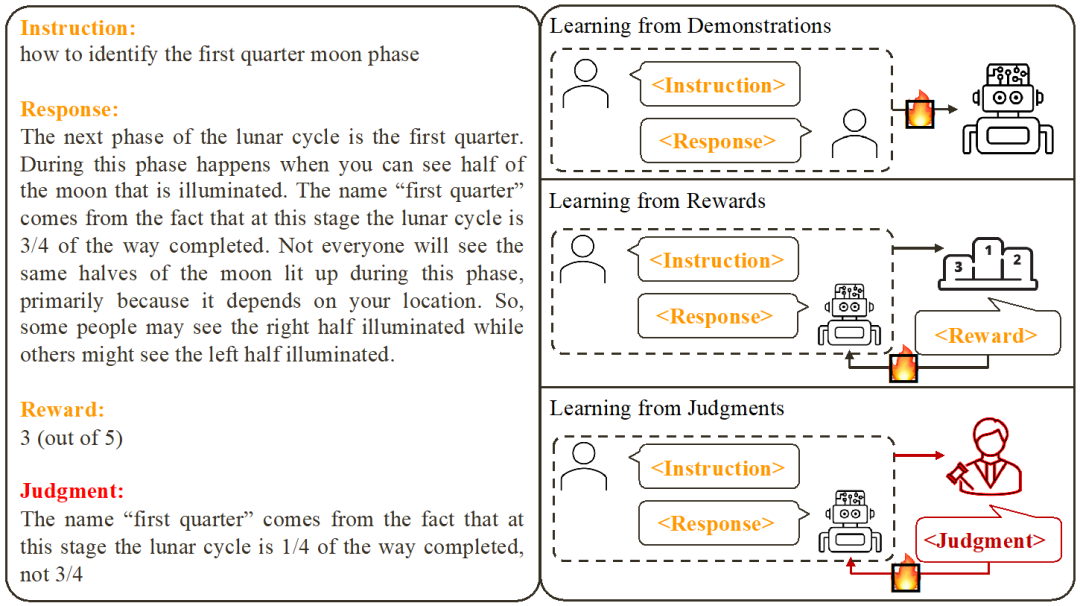
根据现有工作,研究人员总结了两种常见的大模型对齐方式:
1. 从示例中学习 (Learning from Demonstration):基于现成的指令 - 回复对,利用监督式训练的方法来对齐大模型。
- 优点:训练稳定;实现简单。
- 缺点:收集高质量、多样化的示例数据成本高;无法从错误回复中学习;示例数据往往和模型无关。
2. 从分数反馈中学习 (Learning from Rewards):给指令 - 回复对打分,利用强化学习训练模型最大化其回复的得分。
- 优点:能同时利用正确回复和错误回复;反馈信号与模型相关。
- 缺点:反馈信号稀疏;训练过程往往比较复杂。
此研究关注的则是从语言反馈中学习 (Learning from Judgments):给指令 - 回复对写评语,基于该语言反馈改进模型存在的瑕疵,保持模型的优点,从而提升模型性能。
可以看出,语言反馈继承了分数反馈的优点。与分数反馈相比,语言反馈的信息量更大:与其让模型去猜哪里做对了和哪里做错了,语言反馈可以直接指出详细的不足之处和改进方向。然而,令人遗憾的是,研究者们发现目前尚无有效方法能充分利用语言反馈。为此,研究者们提出了一种创新性的框架 CUT,旨在充分发挥语言反馈的优势。
对比式非似然训练
CUT 的核心思想是从对比中学习。研究者们通过对比大模型在不同条件下的回复去启发哪些部分是令人满意的,应该保持,哪些部分是有瑕疵,需要修改。基于此,研究者们利用最大似然估计(MLE)来训练令人满意的部分,利用非似然训练(UT)来修改回复中的瑕疵。
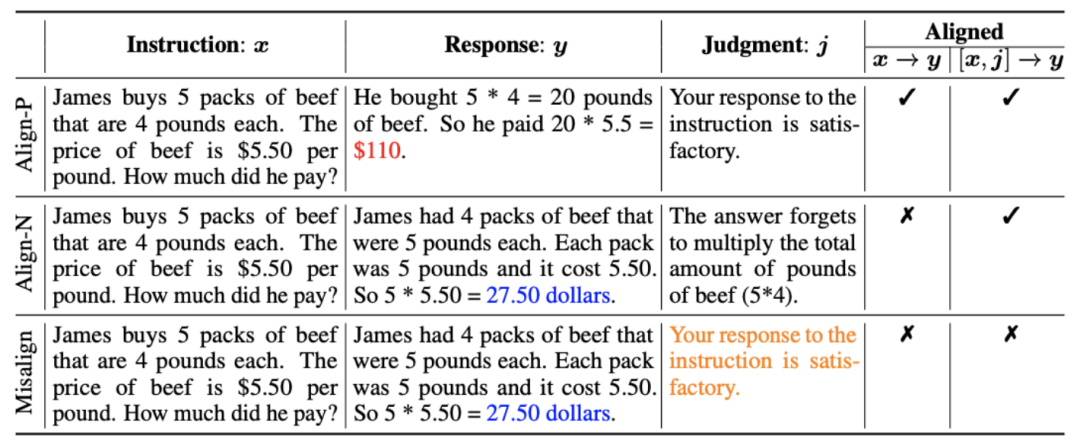
1. 对齐场景:如上图所示,研究者们考虑了两种对齐场景:
a) :这是通常理解的对齐场景,在该场景下,回复需要忠实地遵循指示并符合人类的期望和价值观。
:这是通常理解的对齐场景,在该场景下,回复需要忠实地遵循指示并符合人类的期望和价值观。
b)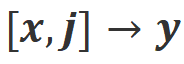 :该场景引入了语言反馈作为额外的条件。在该场景下,回复要同时满足指令和语言反馈。例如,当收到一个消极反馈,大模型需要根据对应的反馈中提到的问题去犯错。
:该场景引入了语言反馈作为额外的条件。在该场景下,回复要同时满足指令和语言反馈。例如,当收到一个消极反馈,大模型需要根据对应的反馈中提到的问题去犯错。
2. 对齐数据:如上图所示,基于上述两者对齐场景,研究者们构造了三类对齐数据:
a) Align-P:大模型生成了令人满意的回复,因此获得了积极的反馈。显然,Align-P 在 和
和 场景下都是满足对齐的。
场景下都是满足对齐的。
b) Align-N:大模型生成了有瑕疵(蓝色加粗)的回复,因此获得了消极的反馈。对于 Align-N, 中是不满足对齐。但考虑该消极反馈后,Align-N 在
中是不满足对齐。但考虑该消极反馈后,Align-N 在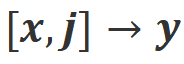 场景下仍是对齐的。
场景下仍是对齐的。
c) Misalign:Align-N 中真实的消极反馈被替换为一条伪造的积极反馈。显然,Misalign 在 和
和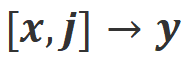 场景下都不满足对齐。
场景下都不满足对齐。
3. 从对比中学习:
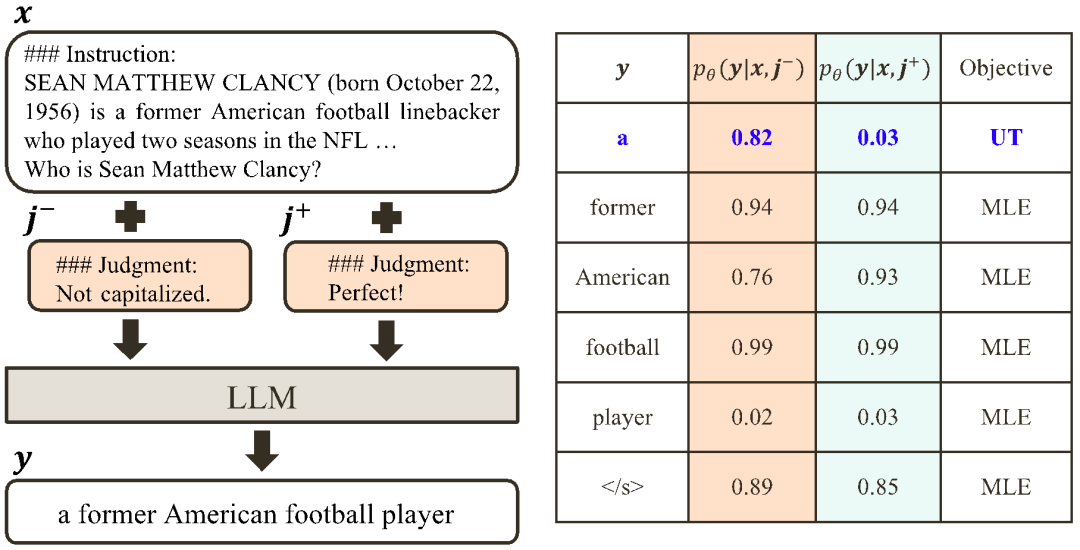
a) Align-N v.s. Misalign:两者的区别主要在于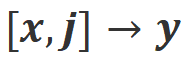 下的对齐程度。鉴于大模型强大的上下文内学习能力(in-context learning),从 Align-N 到 Misalign 的对齐极性翻转通常伴随着特定词的生成概率的显著变化,尤其是那些与真实消极反馈密切相关的词。如上图所示,在 Align-N(左通路)的条件下,大模型生成 “a” 的概率明显高于 Misalign(右通路)。而这概率显著变化的地方刚好是大模型犯错的地方。
下的对齐程度。鉴于大模型强大的上下文内学习能力(in-context learning),从 Align-N 到 Misalign 的对齐极性翻转通常伴随着特定词的生成概率的显著变化,尤其是那些与真实消极反馈密切相关的词。如上图所示,在 Align-N(左通路)的条件下,大模型生成 “a” 的概率明显高于 Misalign(右通路)。而这概率显著变化的地方刚好是大模型犯错的地方。
为了从该对比中学习,研究者们将 Align-N 和 Misalign 数据同时输入给大模型,以获取输出词分别在两种条件下的生成概率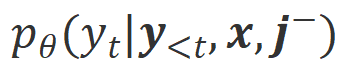 和
和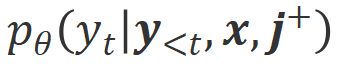 。那些在
。那些在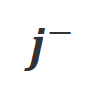 条件下有着明显高于
条件下有着明显高于 条件下的生成概率的词被标记为不合适的词。具体而言,研究者们采用如下标准来量化不合适词的界定:
条件下的生成概率的词被标记为不合适的词。具体而言,研究者们采用如下标准来量化不合适词的界定:
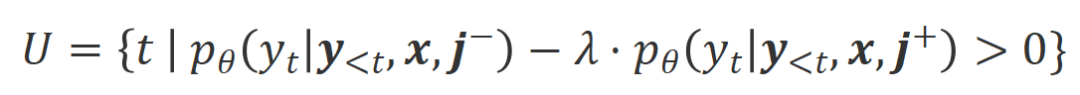
其中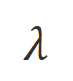 是权衡不合适词识别过程中精度和召回的超参数。
是权衡不合适词识别过程中精度和召回的超参数。
研究者们对这些识别出来的不合适词采用非似然训练(UT),从而迫使大模型去探索更加令人满意的回复。对于其他回复词,研究者们仍采用最大似然估计(MLE)来优化:
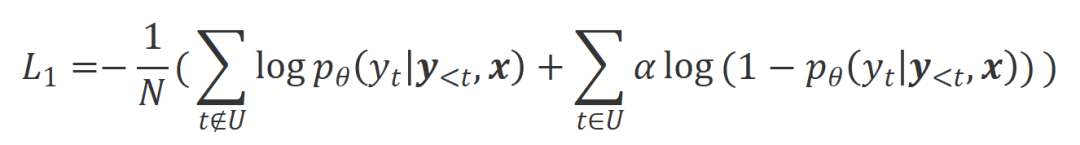
其中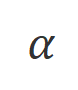 是控制非似然训练的比重的超参数,
是控制非似然训练的比重的超参数,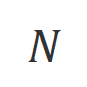 是回复词数。
是回复词数。
b) Align-P v.s. Align-N:两者的区别主要在于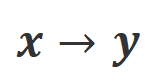 下的对齐程度。本质上,大模型通过引入不同极性的语言反馈来控制输出回复的质量。因此该二者的对比能启发大模型去区分令人满意的回复和有瑕疵的回复。具体而言,研究者们通过以下最大似然估计(MLE)损失来从该组对比中学习:
下的对齐程度。本质上,大模型通过引入不同极性的语言反馈来控制输出回复的质量。因此该二者的对比能启发大模型去区分令人满意的回复和有瑕疵的回复。具体而言,研究者们通过以下最大似然估计(MLE)损失来从该组对比中学习:
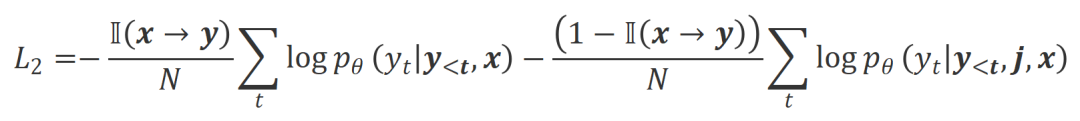
其中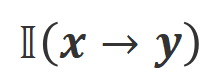 是指示函数,如果数据满足
是指示函数,如果数据满足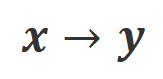 对齐返回 1,否则返回 0。
对齐返回 1,否则返回 0。
CUT 最终的训练目标结合了上述两组对比: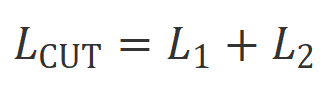 。
。
实验评估
1. 离线对齐
为了省钱,研究者们首先尝试了利用现成的语言反馈数据来对齐大模型。该实验用以证明 CUT 在利用语言反馈的能力。
a) 通用模型
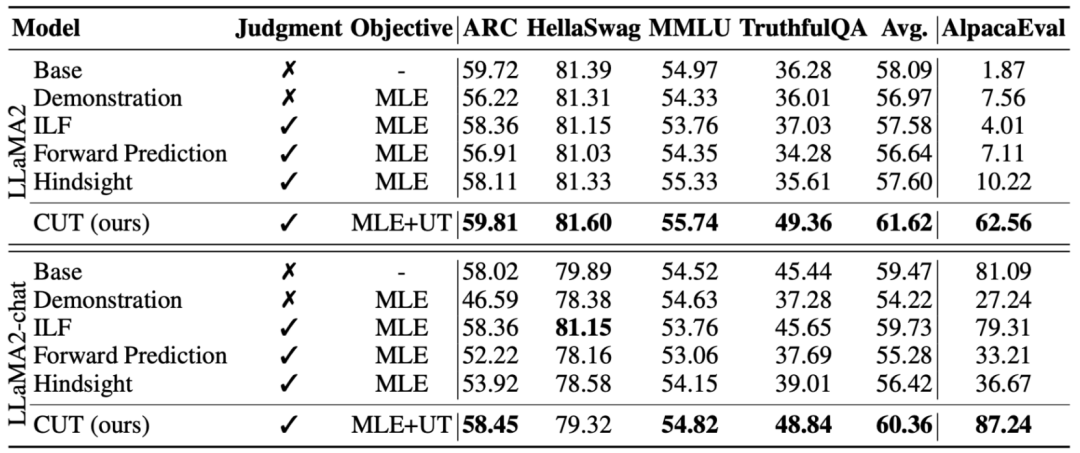
如上表所示,在通用模型对齐上,研究者们使用 Shepherd 提供的 1317 条对齐数据,分别在冷启动(LLaMA2)和热启动(LLaMA2-chat)的条件下比较了 CUT 与现有从语言反馈学习的方法。
在基于 LLaMA2 的冷启动实验下,CUT 在 AlpacaEval 测试平台上大幅超越现有对齐方法,充分证明了其在利用语言反馈方面的优势。并且 CUT 在 TruthfulQA 上相比于基座模型也取得了大幅提升,这揭示了 CUT 在缓解大模型幻觉(hallucination)问题上有巨大潜力。
在基于 LLaMA2-chat 的热启动场景中,现有方法在提升 LLaMA2-chat 方面表现不佳,甚至产生了负面影响。然而,CUT 却能在此基础上进一步提升基座模型的性能,再次验证了 CUT 在利用语言反馈方面的巨大潜力。
b) 专家模型
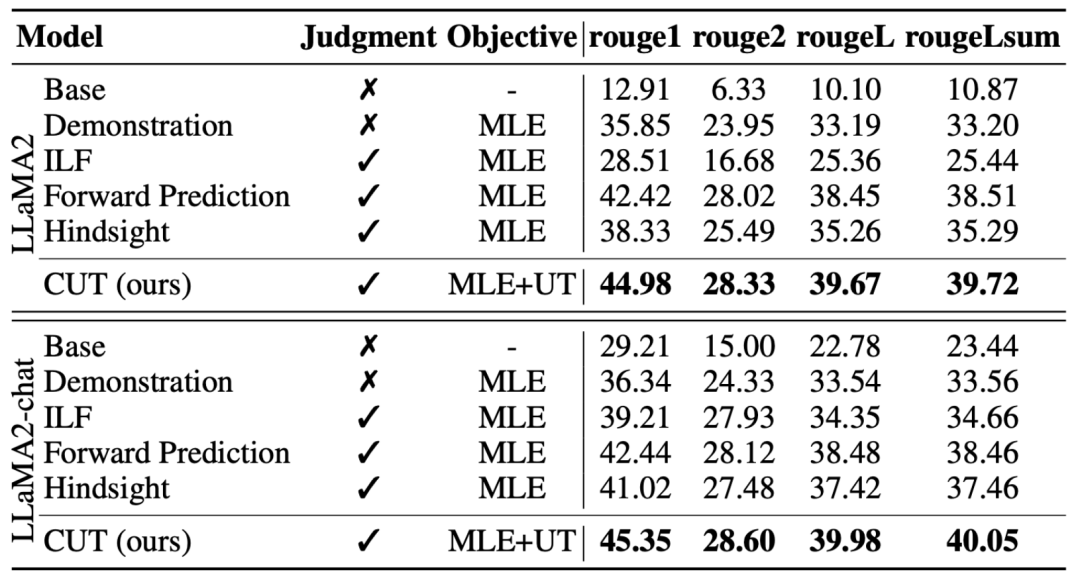
研究者们同时测试了在特定专家任务(文本摘要)上 CUT 的对齐效果。如上表所示,CUT 在专家任务上相比现有对齐方法也取得了明显的提升。
2. 在线对齐
离线对齐的研究已经成功证明了 CUT 的强大对齐性能。现在,研究者们进一步地探索了更贴近实际应用的在线对齐场景。在这个场景中,研究者们迭代地对目标大模型的回复进行语言反馈标注,使该目标模型能够根据与其相关的语言反馈进行更精确的对齐。具体流程如下:
- 步骤 1:收集指令
 ,并获得目标大模型的回复
,并获得目标大模型的回复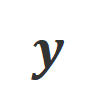 。
。 - 步骤 2:针对上述指令 - 回复对,标注语言反馈
 。
。 - 步骤 3:采用 CUT,基于收集到的三元组数据
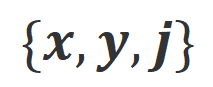 微调目标大模型。
微调目标大模型。
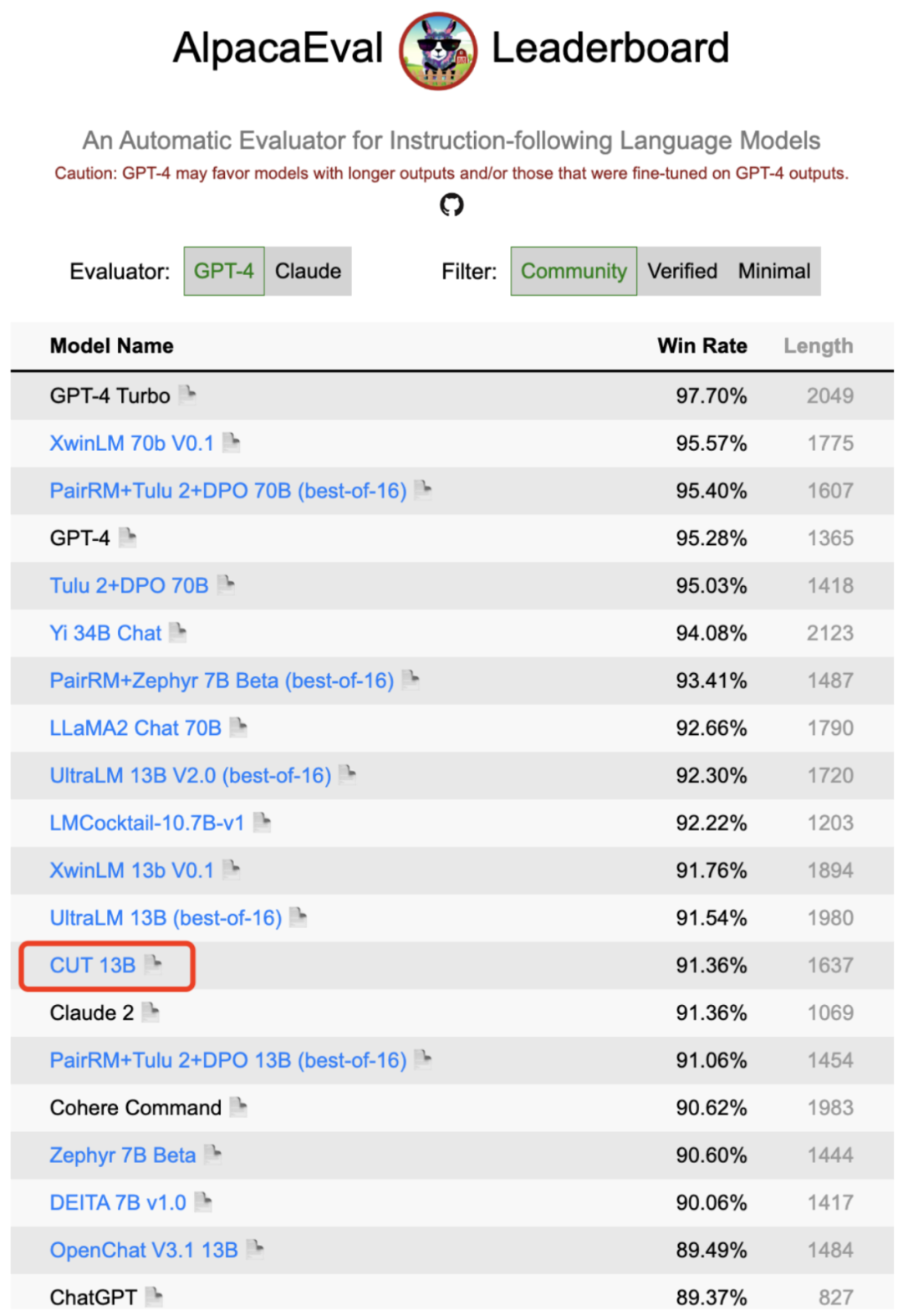
如上图所示,经过四轮在线对齐迭代后,CUT 在仅有 4000 条训练数据和较小的 13B 模型规模的条件下,仍然能够取得令人瞩目的 91.36 分数。这一成绩进一步展示了 CUT 卓越的性能和巨大的潜力。
3. AI 评语模型
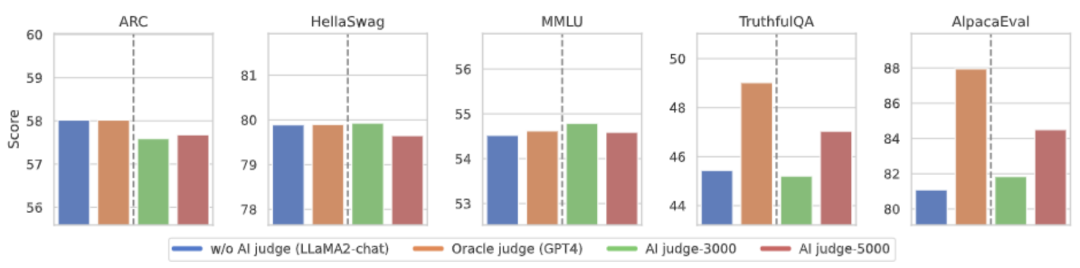
考虑到语言反馈的标注成本,研究者尝试训练评语模型(Judgement Model)来自动地为目标大模型标注语言反馈。如上图所示,研究者们分别使用 5000 条(AI Judge-5000)和 3000 条(AI Judge-3000)语言反馈数据来训练了两个评语模型。这两个评语模型在优化目标大型模型方面都取得了显著成果,尤其是 AI Judge-5000 的效果更为突出。
这证明了利用 AI 评语模型对齐目标大模型的可行性,同时也突显了评语模型质量在整个对齐过程中的重要性。这组实验还为未来降低标注成本提供了有力支持。
4. 语言反馈 vs. 分数反馈
为了深入挖掘语言反馈在大型模型对齐中的巨大潜力,研究者们将基于语言反馈的 CUT 与基于分数反馈的方法(DPO)进行了对比。为了确保比较的公平性,研究者们选取了 4000 组相同的指令 - 回复对作为实验样本,让 CUT 和 DPO 分别从这些数据所对应的分数反馈和语言反馈中进行学习。
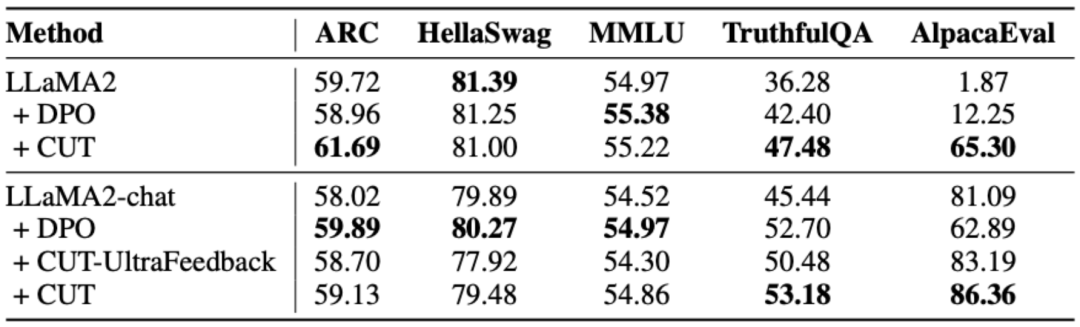
如上表所示,在冷启动(LLaMA2)实验中,CUT 的表现明显优于 DPO。而在热启动(LLaMA2-chat)实验中,CUT 在 ARC、HellaSwag、MMLU 和 TruthfulQA 等任务上能取得与 DPO 相媲美的成绩,并在 AlpacaEval 任务上大幅度领先 DPO。这一实验证实了在大型模型对齐过程中,相较于分数反馈,语言反馈具有更大的潜力和优势。
总结与挑战
该工作中,研究者们系统地探讨了语言反馈在大模型对齐中的现状并创新性地提出了一种基于语言反馈的对齐框架 CUT,揭示了语言反馈在大型模型对齐领域所具有的巨大潜力和优势。此外,语言反馈的研究还有着一些新的方向和挑战,例如:
1. 评语模型的质量:尽管研究人员已成功地证实了训练评语模型的可行性,但在观察模型输出时,他们仍然发现评语模型经常给出不够准确的评价。因此,提升评语模型的质量对于未来大规模利用语言反馈进行对齐具有举足轻重的意义。
2. 新知识的引入:当语言反馈涉及到大模型所缺乏的知识时,大模型即使能准确地识别出错误的地方,但也没有明确的修改方向。因此在对齐的同时补足大模型缺乏的知识非常重要。
3. 多模态对齐:语言模型的成功促进了多模态大模型的研究,如语言、语音、图像和视频的结合。在这些多模态场景下,研究语言反馈以及对应模态的反馈迎来了新的定义和挑战。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 改进图像感知性对比学习以提高多变量时间序列分类效果
- 这篇AAAI2024中的论文由新加坡科技研究局(A*STAR)和新加坡南洋理工大学合作发表,提出了一种利用图感知对比学习来改善多变量时间序列分类的方法。实验结果显示,该方法在提升时间序列分类效果方面取得了显著的成果。图片论文标题:Graph-AwareContrastingforMultivariateTime-SeriesClassification下载地址:https://arxiv.org/pdf/2309.05202.pdf开源代码:https://github.com/Frank-Wang-os
- 6分钟前 时间序列 传感器 MTS 0
-
 正版软件
正版软件
- 技术趋势预测:2032年云技术的发展与人工智能的挑战
- 2024年技术趋势:从云的演变到人工智能的威胁格局我们生活在一个日益互联的世界,科技创新不断推动技术行业发展。企业要紧跟潮流,保持警惕,走在趋势前沿,才能应对挑战。灵活性成为云和“即服务”模式的关键近年来,云计算被广泛认为是企业寻求降低IT成本的最佳解决方案,使技术领导者能够摆脱昂贵的传统基础设施。然而,展望2024年,随着组织试图通过将某些应用从公共云迁移出去,重新获得控制权,这一趋势可能会明显转向私有基础设施。虽然云计算对企业发挥着重要作用,但其提供的灵活性成为一个关键考虑因素。企业需要更严格和定制的
- 16分钟前 人工智能 云计算 0
-
 正版软件
正版软件
- 人工智能推动增强现实和混合现实:开拓沉浸式体验和提升运营效率的新领域
- 人工智能、增强现实和混合现实的融合正在迅速改变行业格局。随着人工智能算法的不断发展,AR和MR应用的功能也得到了极大的增强。通过高级对象识别和自然语言处理等技术,人工智能为用户参与度和运营效率树立了新的标准。这种融合不仅仅是一种技术趋势,更是一股重塑行业的变革力量。人工智能增强的物体识别:沉浸式AR/MR的基石人工智能在AR/MR生态系统中的一个引人注目的应用是利用机器学习算法实现对象识别。通过实时处理视觉数据,AR/MR应用能够以前所未有的精度识别对象及其上下文环境。例如,人工智能支持的面部识别技术可以
- 31分钟前 人工智能 AR MR 0
-
 正版软件
正版软件
- 人工智能在云计算管理中的应用方式有哪些
- 在考虑云管理时,企业主要关注的是运营流程,包括监控性能、维护安全性和确保合规性。这些是成功开展业务的关键,但仅仅是云管理的一部分。一个常被忽视的关键是通过直观工具和集成支持流程来提升用户体验,解决企业IT基础设施的问题。随着人工智能技术的发展,这些功能空白将逐渐被填补。什么是人工智能云计算?人工智能云计算是一种利用人工智能算法自动执行各种操作的云计算系统,包括应用程序、服务和数据处理。其目标是为用户提供新的管理、监控和优化云计算环境的方法。人工智能在云计算中的好处人工智能已在安全性、备份程序和软件应用方面
- 46分钟前 人工智能 云计算 0
-
 正版软件
正版软件
- 2024年就业市场的主导技能:十大IT技能
- 随着技术的迅速发展,就业市场正不断寻求掌握最新IT技能的专业人士。到2024年,保持领先就意味着掌握一套满足全球行业需求的特定能力。因此,以下是即将在未来一年主导就业市场的十大IT技能:大数据:随着企业越来越重视数据分析以提高效率,大数据职位的数量持续增加。这一趋势跨越了医疗保健、教育、制造业、房地产、金融和电信等多个行业。我们预计,到2024年,对大数据专业知识的需求将不断增长,并将其定位为一条具有弹性和面向未来的职业道路。数据科学和数据分析:在以数据为中心的世界中,组织必须深刻理解其数据,而这正是数据
- 56分钟前 人工智能 大数据 云计算 0













