智能体通过全新的自主进化策略,提升取经能力-清华、港大研究新方法
 发布于2024-11-30 阅读(0)
发布于2024-11-30 阅读(0)
扫一扫,手机访问
「以史为鉴,可以知兴替。」人类的进步史是一个不断吸取过去经验、推进能力边界的自我演化过程。我们从过去的失败中吸取教训,纠正错误;借鉴成功经验,提升效率和效果。这种自我进化贯穿生活方方面面:总结经验解决工作问题,利用规律预测天气,我们持续从过去学习和进化。
成功从过去的经验中提取知识并将其应用于未来的挑战,这是人类进化之路上重要的里程碑。那么在人工智能时代,AI 智能体是否也可以做到同样的事情呢?
近年来,GPT和LLaMA等语言模型展示了在解决复杂任务时的惊人能力。然而,虽然它们可以利用工具解决具体任务,但本质上缺乏对过去成功和失败经历的洞见和汲取。这就像一个只能完成特定任务的机器人,虽然在当前任务中表现出色,但面对新的挑战时却无法调用过去的经验提供帮助。因此,我们需要进一步发展这些模型,使其能够积累知识和经验,并将其应用于新的情境中。通过引入记忆和学习机制,我们可以使这些模型具备更全面的智能,能够在不同任务和情境中灵活应对,并从过去的经验中获得启示。这将使得语言模型更加强大和可靠,并有助于推动人工智能的发展。
针对这一难题,近期来自清华大学、香港大学、人民大学以及面壁智能的联合团队提出了一种全新的智能体自我演化策略:探索 - 固化 - 利用(Investigate-Consolidate-Exploit,ICE)。它旨在通过跨任务的自我进化来提升 AI 智能体的适应性和灵活性。其不仅能提升智能体处理新任务时的效率和效果,还能显著降低对智能体基座模型能力的需求。
这个策略的出现,确实开启了智能体自我进化的新篇章,也标志着我们朝着实现完全自主的智能体又迈进了一步。

- 论文标题:Investigate-Consolidate-Exploit: A General Strategy for Inter-Task Agent Self-Evolution
- 论文链接:https://arxiv.org/abs/2401.13996
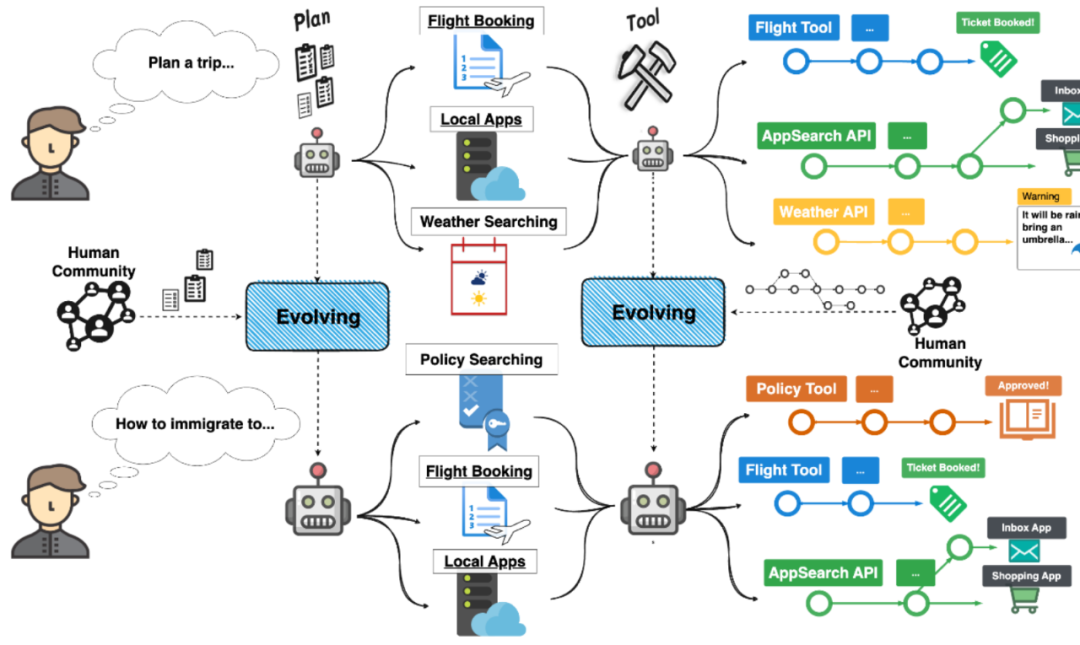 智能体任务间经验迁移以实现自我进化概览图
智能体任务间经验迁移以实现自我进化概览图
智能体自我进化的两个方面:规划与执行
当前的复杂智能体主要可分为任务规划和任务执行两个方面。在任务规划方面,智能体通过逻辑推理将用户需求分解并制定详细的目标策略。而在任务执行方面,智能体利用各种工具与环境进行交互,以完成相应的子目标。
为了更好地促进以往经验的重复利用,作者在该论文中首先将进化策略解耦为两个方面。具体地,作者以XAgent智能体架构中的树状任务规划结构和ReACT链式工具执行为例,分别详细介绍了ICE策略的实现方法。
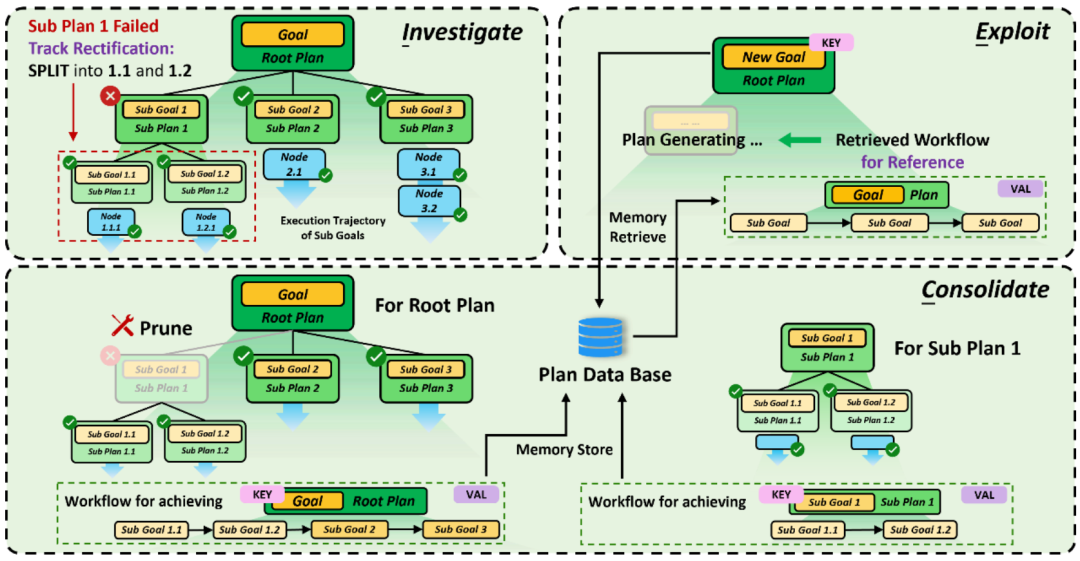 智能体任务规划的 ICE 自我演化策略
智能体任务规划的 ICE 自我演化策略
对于任务规划,自我进化依照 ICE 被分为以下三个阶段:
- 在探索阶段,智能体记录下整个树状任务规划结构,并同时动态检测各个子目标的执行状态;
- 在固化阶段,智能体首先剔除所有失败的目标结点,之后对于每个成功完成的目标,智能体将以该目标为子树的所有叶子结点依次排开形成一条规划链(Workflow);
- 在利用阶段,这些规划链将被作为新任务目标分解细化的参考依据,以利用过往的这些成功经验。
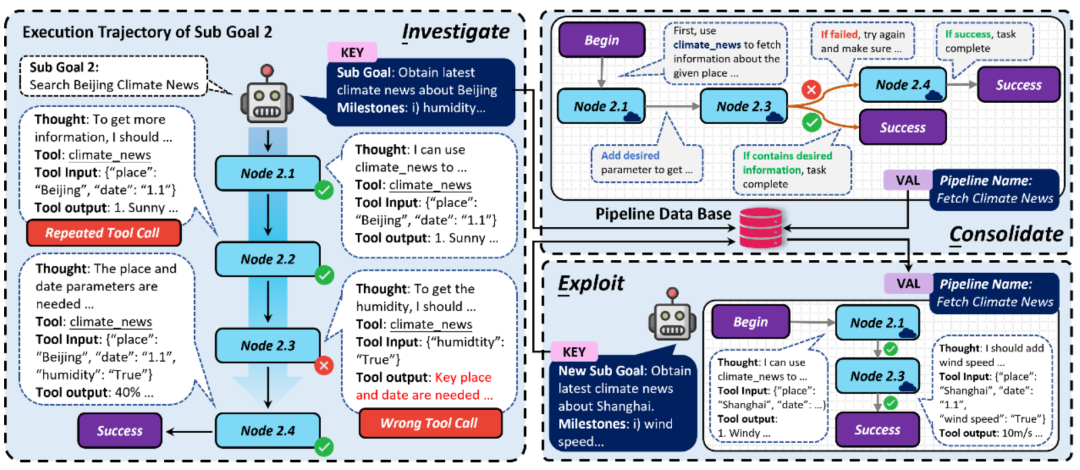 智能体任务执行的 ICE 自我演化策略
智能体任务执行的 ICE 自我演化策略
任务执行的自我演化策略依然分为 ICE 三个阶段,其中:
- 在探索阶段,智能体动态记录每个目标执行的工具调用链,并对工具调用中出现的可能问题进行简单的检测归类;
- 在固化阶段,工具调用链将被转化为类似自动机的流水线(Pipeline)结构,工具调用顺序与调用之间的转移关系将被固定,同时还会去掉重复调用,增加分支逻辑等等让自动机自动化执行流程更加鲁棒;
- 在利用阶段,对于相似的目标,智能体将直接自动化执行流水线,从而提升任务完成效率。
XAgent 框架下的自我进化实验
作者在 XAgent 框架中对提出的 ICE 自我演化策略进行了测试,并总结了以下四点发现:
- ICE 策略能够显著降低模型的调用次数,从而提升效率,减少开销。
- 存储的经验在 ICE 策略下有着较高的复用率,这证明了 ICE 的有效性。
- ICE 策略能够提升子任务完成率同时减少规划返修的次数。
- 通过以往经验的加持,任务执行对模型能力的要求显著下降。具体来看,使用 GPT-3.5 搭配上之前的任务规划与执行经验,效果可以直接媲美 GPT-4。
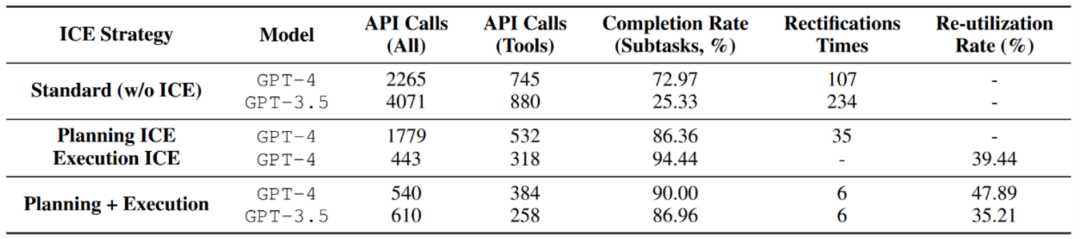 在探索 - 固化进行经验存储后,测试集任务在不同智能体 ICE 策略下的表现
在探索 - 固化进行经验存储后,测试集任务在不同智能体 ICE 策略下的表现
同时,作者还进行了额外的消融实验:在存储经验逐渐增加的情况下,智能体的表现是否越来越好?答案是肯定的。从零经验,半经验,到满经验,基座模型的调用次数逐渐减少,而子任务完成度逐渐提升,同时复用率也有升高。这表明更多的过往经验能够更好地促进智能体执行,实现规模效应。
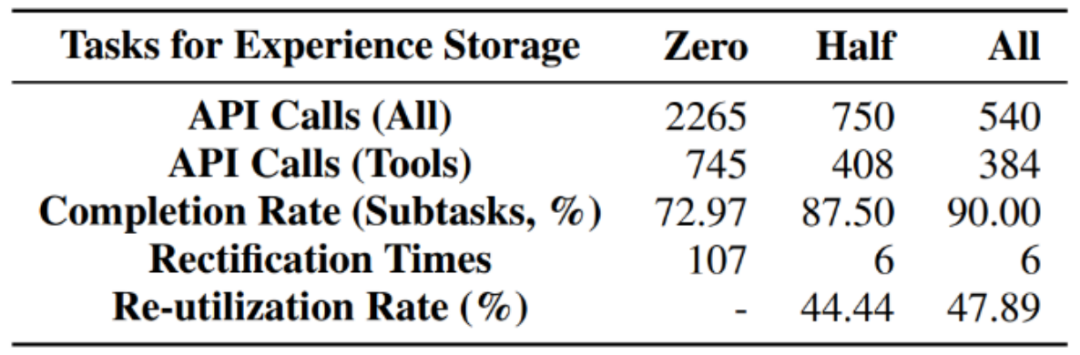 在不同经验存储量下,测试集任务表现的消融实验结果统计
在不同经验存储量下,测试集任务表现的消融实验结果统计
结语
畅想一下,在人人都能够部署智能体的世界中,成功经验的数量会随着智能体个体任务执行不断累积,而用户也可以将这些经验在云端中、社区里进行分享。这些经验将促使智能体不断汲取能力,自我进化,逐渐达到完全自主。我们向这样的时代又迈进了一步。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 三星Galaxy S24系列电池保护升级:智能贴心模式提升至三种
- 据消息,三星最新推出的GalaxyS24系列手机对电池保护功能进行了重要的改进,为用户提供了更多选择,延长手机电池的使用寿命。尤其对于夜间充电的用户来说,这一新功能无疑是一项重大的福音。用户现在可以根据自己的需要选择合适的充电模式,以更好地保护电池健康。这将有效地减少过度充电和过度放电对电池寿命的影响,让用户享受更长久的电池续航时间。三星的这一创新将进一步提升用户体验,满足用户对手机电池寿命的需求。在此前的OneUI6.1更新以及GalaxyS24系列发布之前,三星的“电池保护”功能相对简单,只有一个开关
- 7分钟前 三星 0
-
 正版软件
正版软件
- Rivian颠覆行业,在美国车主心中称霸,特斯拉略显失色
- 2月6日消息,最新的调查结果显示,美国消费者报告(ConsumerReports)公布了一项令人意外的发现。新兴电动汽车制造商Rivian竟然成功登顶,成为美国车主最喜欢的汽车品牌。这一荣誉甚至超越了享有盛誉的Mini、宝马、保时捷以及特斯拉等品牌。这个结果对于Rivian来说无疑是一个巨大的成就,也反映了消费者对于电动汽车的兴趣和需求的持续增长。Rivian的成功不仅仅在于其出色的性能和设计,更在于其对环境可持续性的承诺和创新的技术。这个调查结果对于整个汽车行业来说都具有重要的参考价值,将会对未来的市场
- 22分钟前 Rivian 0
-
 正版软件
正版软件
- 三星与伦敦地铁合作,推出Galaxy S24系列创新宣传活动,展示“即刻识别,即刻搜索”功能
- 三星与伦敦交通局合作,在伦敦地铁系统展开推广活动,以促销最新款GalaxyS24手机及其独特的AI功能“即圈即搜”。根据报道,GalaxyS24系列的主打AI功能是“即圈即搜”,它为用户提供了在任何屏幕上轻松圈选内容并通过谷歌搜索获取相关信息的便利。这一功能不仅适用于网络浏览器和相册等应用程序,甚至还可以在相机应用的实时取景画面中使用。举个例子,当用户在旅途中遇到未知的地标时,只需使用“即圈即搜”功能,就可以快速获得相关信息。这项功能的引入使用户能够更加方便地获取所需信息,提升了用户体验。为了进一步凸显创
- 37分钟前 三星 0
-
 正版软件
正版软件
- 比亚迪汽车首艘滚装运输船“开拓者1号”成功航行穿越大西洋,驶向欧洲
- 据知名博主“小迪快报”透露,比亚迪的首艘汽车滚装运输船“开拓者1号”已成功穿越好望角,目前正在向欧洲方向航行。这艘船在今年1月初分别在山东烟台港和深汕小漠国际物流港举行了盛大的交船和首航仪式。"开拓者1号"不仅是比亚迪的首艘汽车滚装运输船,更是国内首艘由本土船厂打造、专为中国汽车出口设计的运输船。这一重要事件标志着中国汽车海运自主时代的全新篇章已经开启。据了解,“开拓者1号”船长近200米,拥有7000个标准车位,采用LNG双燃料动力技术,适应多种航线需求,并能装载各类新能源车辆。该船充分融入比亚迪的绿色
- 47分钟前 比亚迪 0
-
 正版软件
正版软件
- 强劲开局!长城汽车旗下坦克品牌2024年1月销量突破2万辆
- 长城汽车旗下坦克品牌在最近公布的销售数据中表现出色,开启了2024年的良好开端。据该品牌执行副总经理谷玉坤在社交媒体上透露,截至1月份,坦克品牌销量达到了20067辆,实现了同比和环比双向增长,并成功夺得了中国越野SUV销量、越野新能源销量以及越野车出口量的多项冠军。这一成绩再次证明了坦克品牌在市场上的竞争力和消费者对其产品的认可。坦克品牌在未来可期,为长城汽车集团带来了更多的增长潜力。根据详细数据显示,坦克品牌在1月份的销量同比增长了239.26%。其中,坦克300的销量达到了9340辆,环比增长了20
- 1小时前 11:30 长城汽车 0













