Qwen1.5开源版推出六种体量模型,超越GPT3.5性能巅峰
 发布于2024-11-30 阅读(0)
发布于2024-11-30 阅读(0)
扫一扫,手机访问
赶在春节前,通义千问大模型(Qwen)的 1.5 版上线了。今天上午,新版本的消息引发了 AI 社区关注。
新版大模型包括六个型号尺寸:0.5B、1.8B、4B、7B、14B和72B。其中,最强版本的性能超越了GPT 3.5和Mistral-Medium。该版本包含Base模型和Chat模型,并提供多语言支持。
阿里通义千问团队表示,相关技术也已经上线到了通义千问官网和通义千问 App。
除此以外,今天 Qwen 1.5 的发布还有如下一些重点:
- 支持 32K 上下文长度;
- 开放了 Base + Chat 模型的 checkpoint;
- 可与 Transformers 一起本地运行;
- 同时发布了 GPTQ Int-4 / Int8、AWQ 和 GGUF 权重。
通过使用更先进的大型模型作为评委,通义千问团队对Qwen1.5在两个广泛使用的基准MT-Bench和Alpaca-Eval上进行了初步评估。评估结果如下:
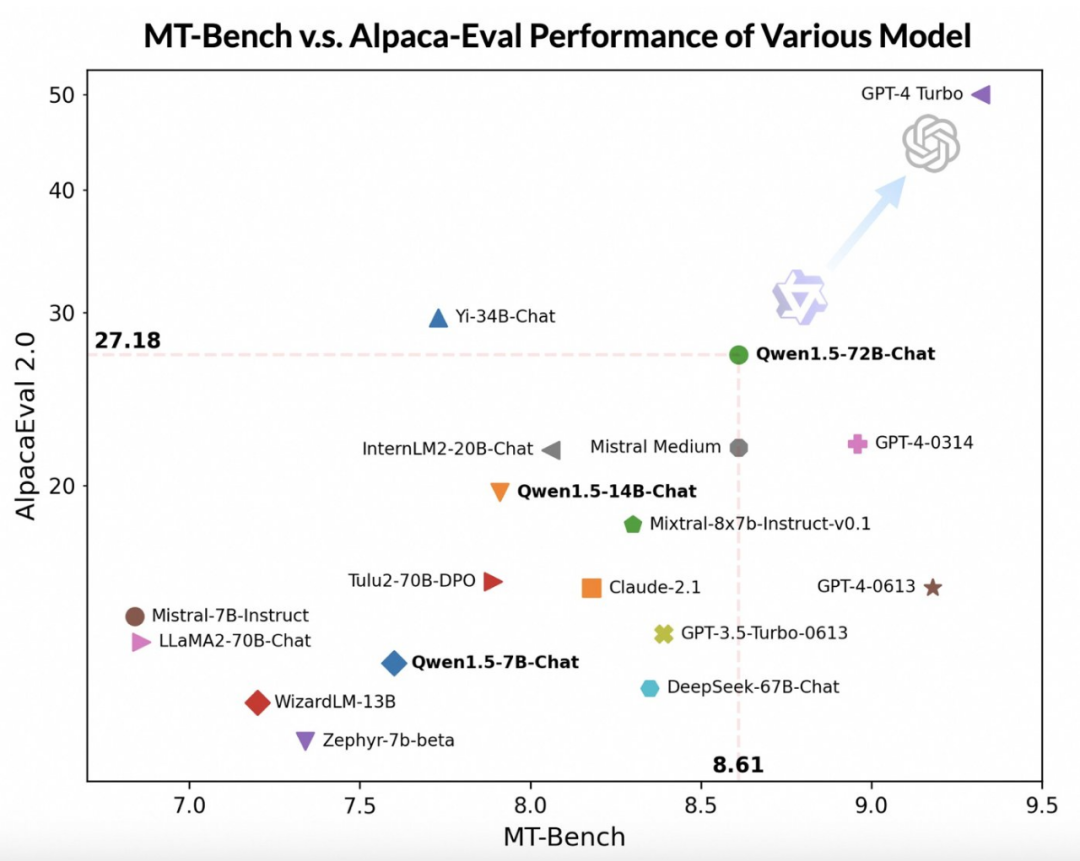
尽管 Qwen1.5-72B-Chat 模型相对于 GPT-4-Turbo 有些落后,但在 MT-Bench 和 Alpaca-Eval v2 上的测试中,它展现出了令人瞩目的性能。实际上,Qwen1.5-72B-Chat 在性能上超过了 Claude-2.1、GPT-3.5-Turbo-0613、Mixtral-8x7b-instruct 和 TULU 2 DPO 70B 这些模型,与最近备受关注的 Mistral Medium 模型相媲美。这表明 Qwen1.5-72B-Chat 模型在自然语言处理方面具备了相当的实力。
通义千问团队指出,尽管大模型的评分可能与回答的长度有关,但人类的观察结果表明,Qwen1.5并没有因为产生过长的回答而影响评分。根据AlpacaEval 2.0的数据,Qwen1.5-Chat的平均长度为1618,与GPT-4的长度相同,比GPT-4-Turbo要短。
通义千问的开发者表示,近几个月以来,他们一直致力于构建一个卓越的模型,并不断提升开发者的使用体验。

相较于以往版本,本次更新着重提升了 Chat 模型与人类偏好的对齐程度,并且显著增强了模型的多语言处理能力。在序列长度方面,所有规模模型均已实现 32768 个 tokens 的上下文长度范围支持。同时,预训练 Base 模型的质量也有关键优化,有望在微调过程中为人们带来更佳体验。
基础能力
关于模型基础能力的评测,通义千问团队在 MMLU(5-shot)、C-Eval、Humaneval、GS8K、BBH 等基准数据集上对 Qwen1.5 进行了评估。
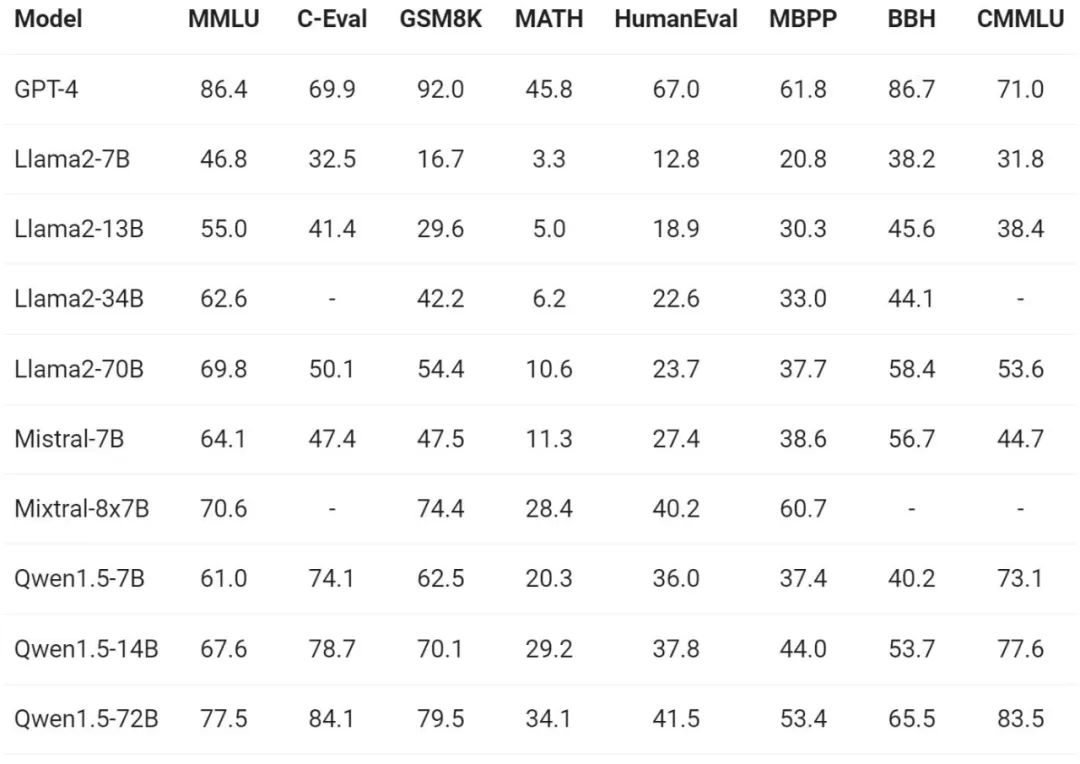
在不同模型尺寸下,Qwen1.5 都在评估基准中表现出强大的性能,72B 的版本在所有基准测试中都超越了 Llama2-70B,展示了其在语言理解、推理和数学方面的能力。
最近一段时间,小型模型的构建是业内热点之一,通义千问团队将模型参数小于 70 亿的 Qwen1.5 模型与社区中重要的小型模型进行了比较:
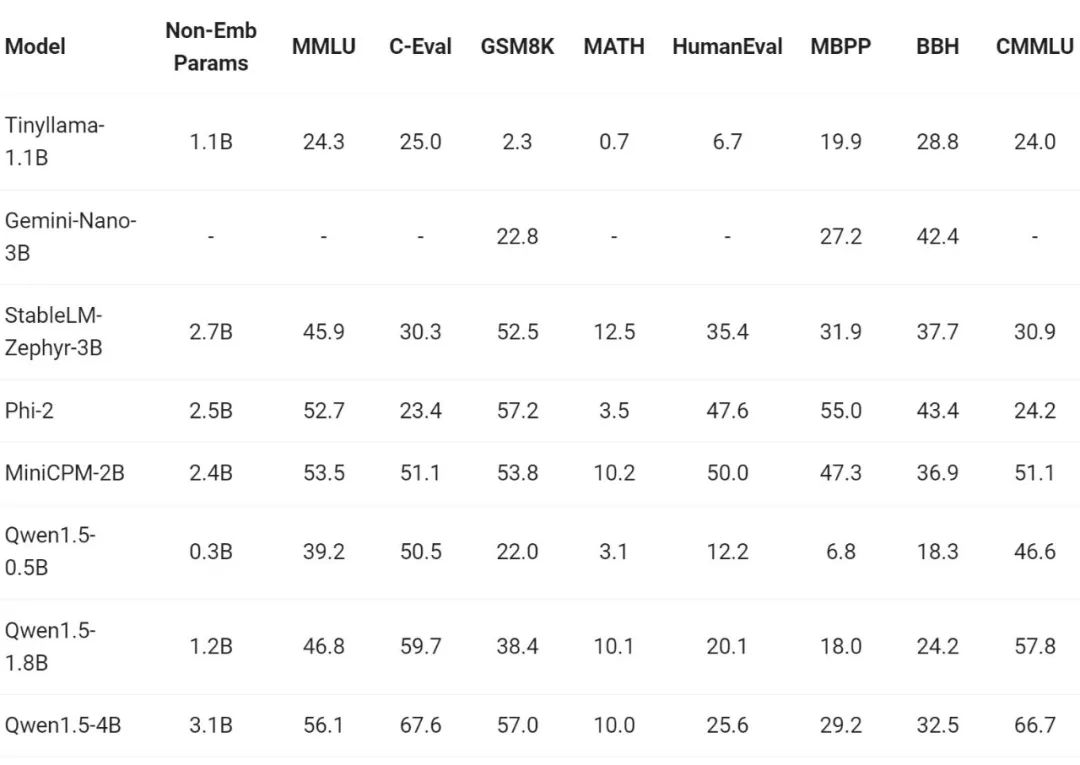
在参数规模低于 70 亿的范围内 Qwen1.5 与业界领先的小型模型相比具有很强的竞争力。
多语言能力
在来自欧洲、东亚和东南亚的 12 种不同语言上,通义千问团队评估了 Base 模型的多语言能力。从开源社区的公开数据集中,阿里研究者构建了如下表所示的评测集合,共涵盖四个不同的维度:考试、理解、翻译、数学。下表提供了每个测试集的详细信息,包括其评测配置、评价指标以及所涉及的具体语言种类。
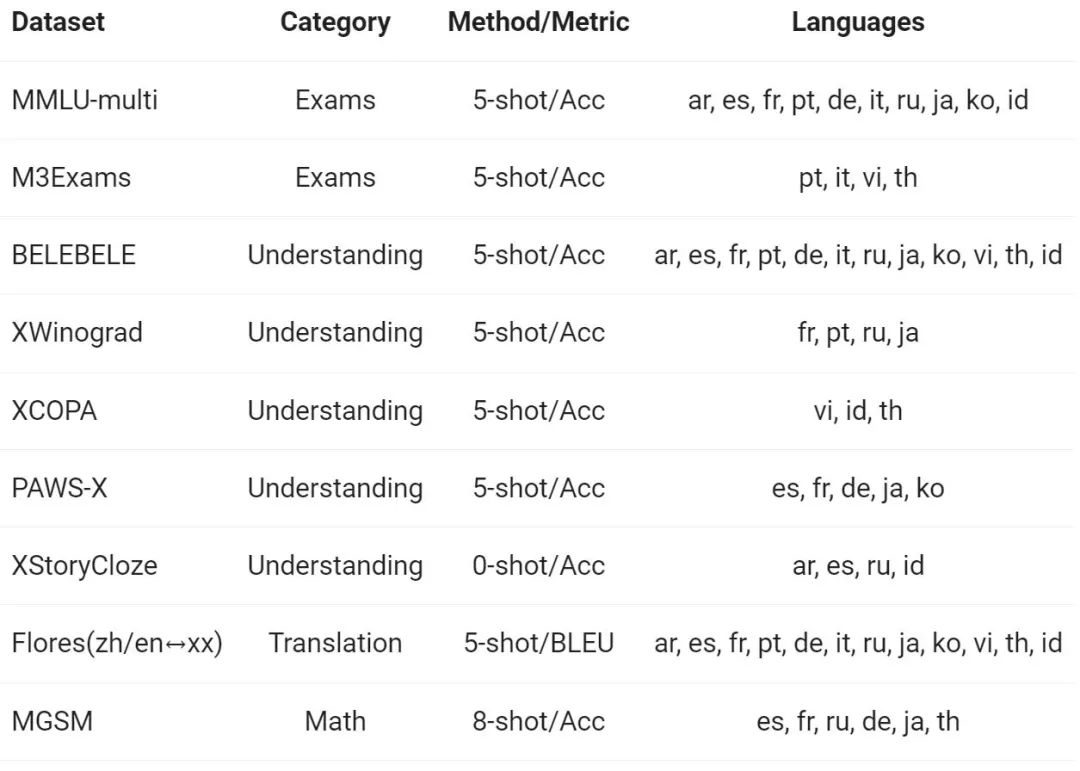
详细的结果如下:
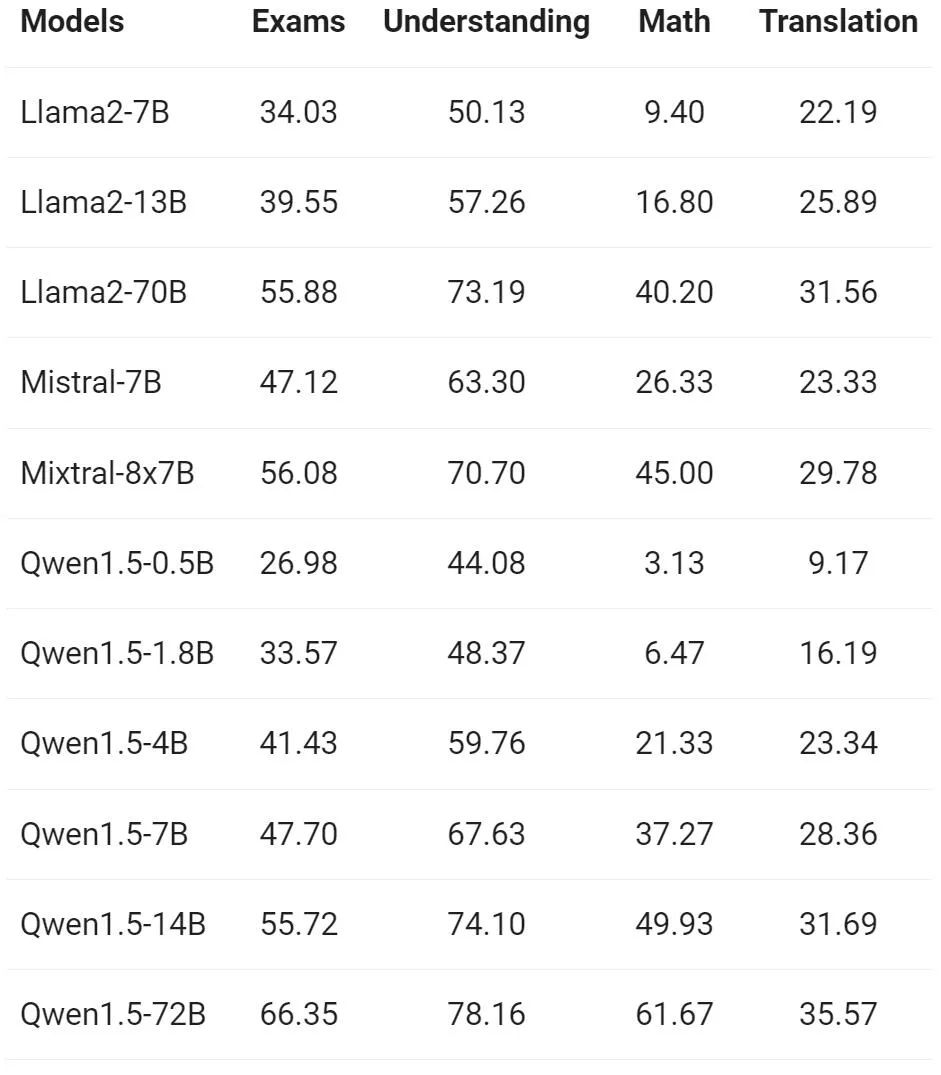
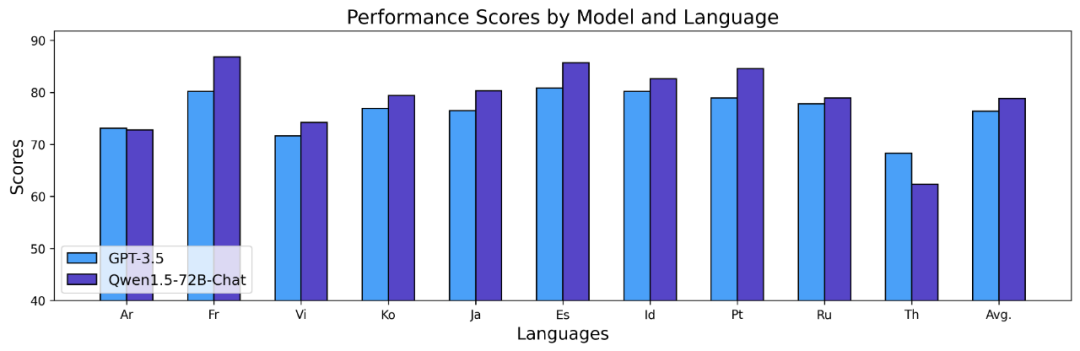
上述结果表明,Qwen1.5 Base 模型在 12 种不同语言的多语言能力方面表现出色,在学科知识、语言理解、翻译、数学等各个维度的评估中,均展现了不错的结果。更进一步地,在 Chat 模型的多语言能力上,可以观察到如下结果:
长序列
随着长序列理解的需求不断增加,阿里在新版本上提升了千问模型的相应能力,全系列 Qwen1.5 模型支持 32K tokens 的上下文。通义千问团队在 L-Eval 基准上评估了 Qwen1.5 模型的性能,该基准衡量了模型根据长上下文生成响应的能力。结果如下:
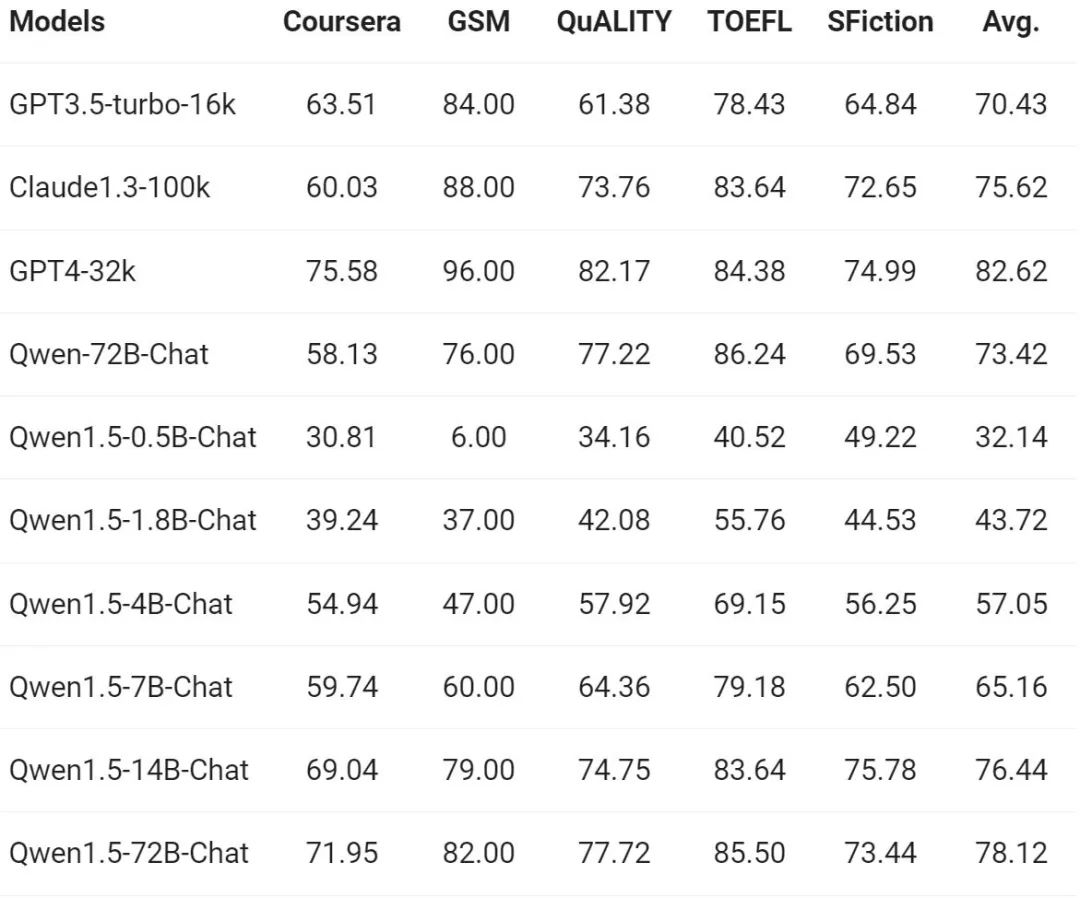
从结果来看,即使像 Qwen1.5-7B-Chat 这样的小规模模型,也能表现出与 GPT-3.5 可比较的性能,而最大的模型 Qwen1.5-72B-Chat 仅略微落后于 GPT4-32k。
值得一提的是,以上结果仅展示了 Qwen 1.5 在 32K tokens 长度下的效果,并不代表模型最大只能支持 32K 长度。开发者可以在 config.json 中,将 max_position_embedding 尝试修改为更大的值,观察模型在更长上下文理解场景下,是否可以实现令人满意的效果。
链接外部系统
如今,通用语言模型的一大魅力在于其与外部系统对接的潜在能力。RAG 作为一种在社区中快速兴起的任务,有效应对了大语言模型面临的一些典型挑战,如幻觉、无法获取实时更新或私有数据等问题。此外,语言模型在使用 API 和根据指令及示例编写代码方面,展现出了强大的能力。大模型能够使用代码解释器或扮演 AI 智能体,发挥出更为广阔的价值。
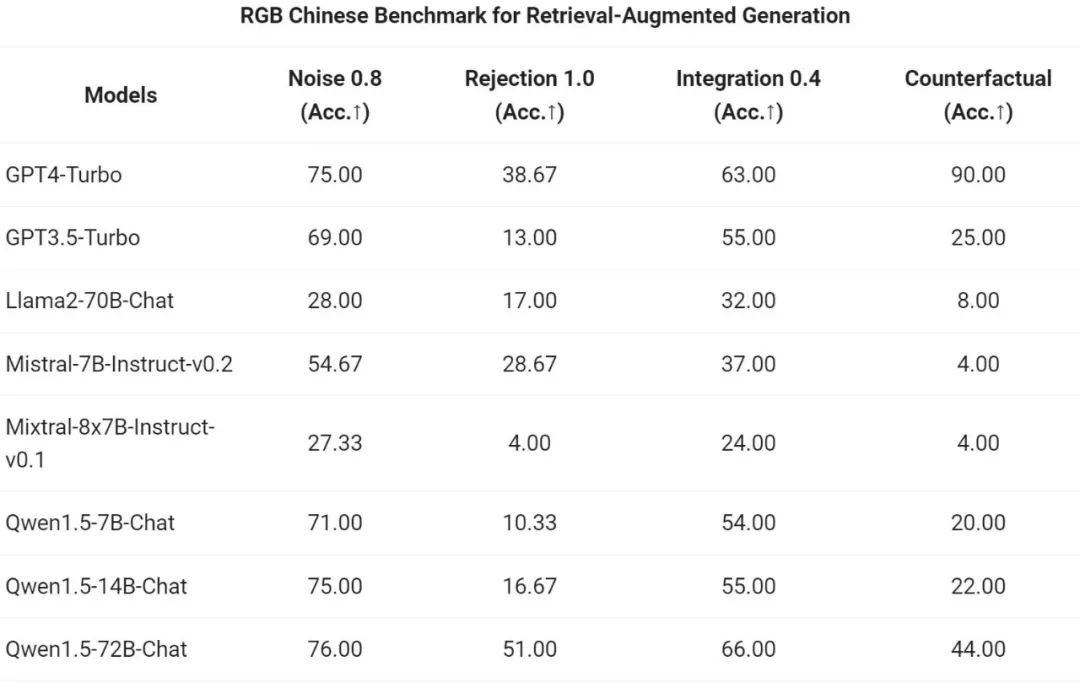
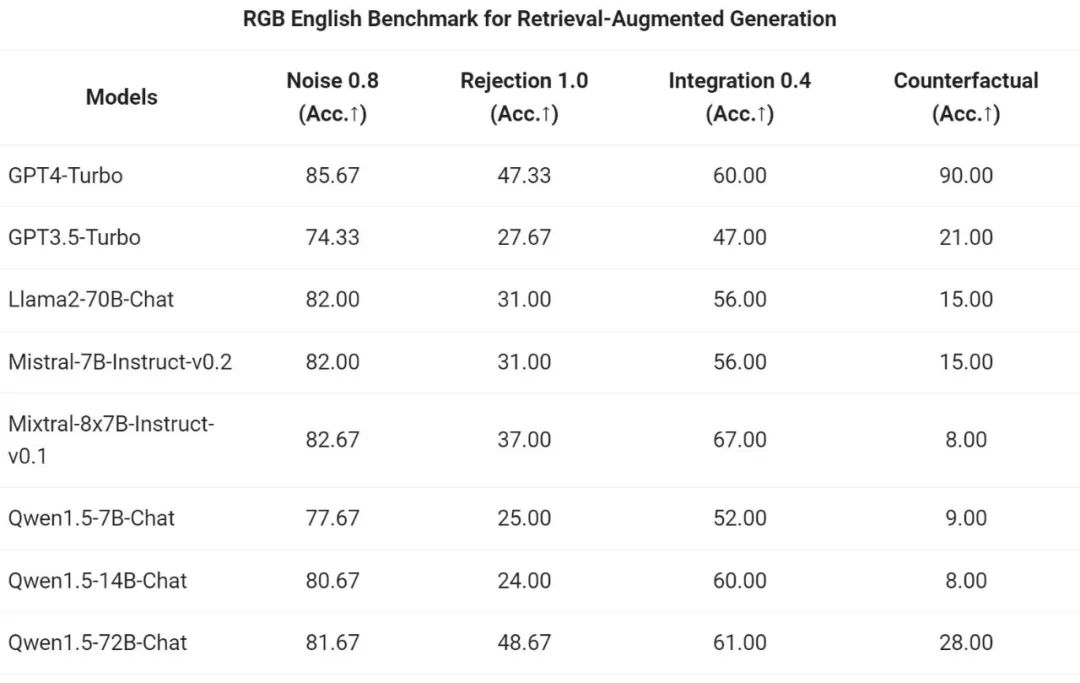
通义千问团队对 Qwen1.5 系列 Chat 模型在 RAG 任务上的端到端效果进行了评估。评测基于 RGB 测试集,是一个用于中英文 RAG 评估的集合:
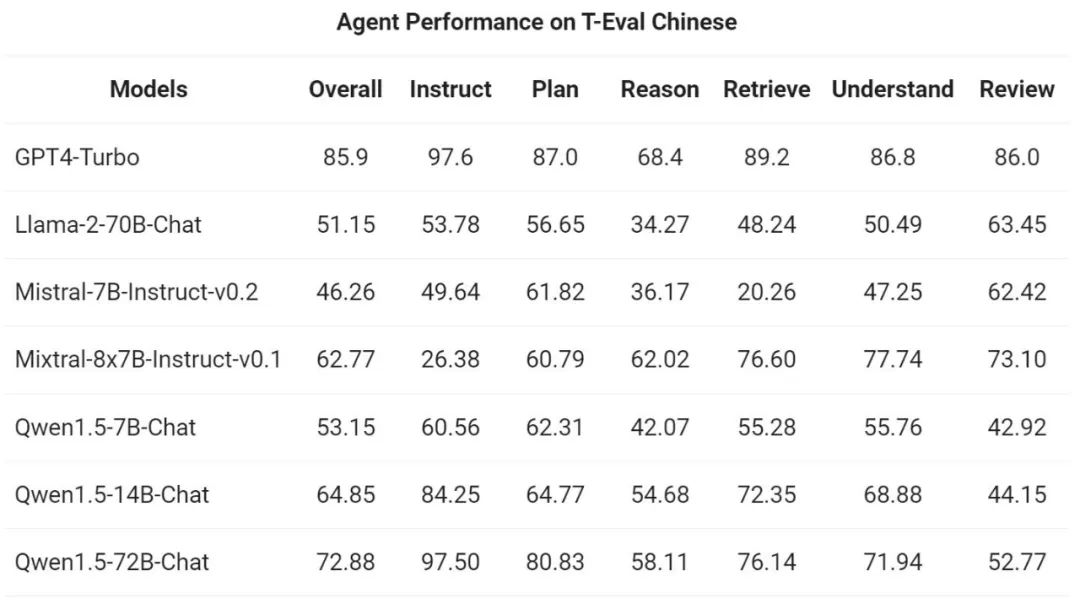
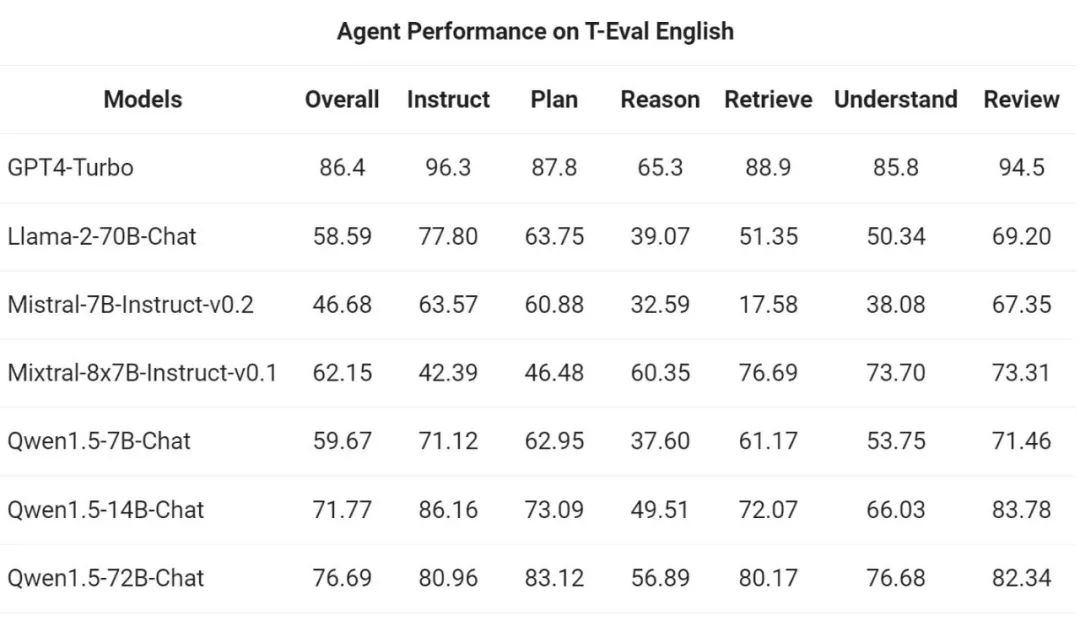
然后,通义千问团队在 T-Eval 基准测试中评估了 Qwen1.5 作为通用智能体运行的能力。所有 Qwen1.5 模型都没有专门面向基准进行优化:
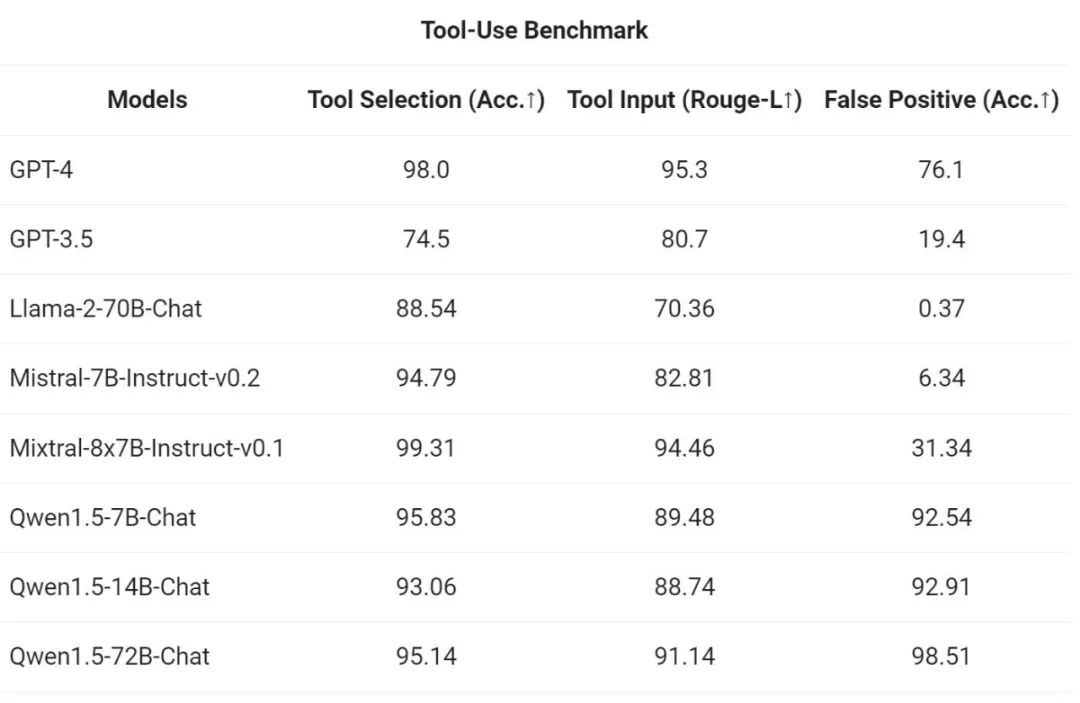
为了测试工具调用能力,阿里使用自身开源的评估基准测试模型正确选择、调用工具的能力,结果如下:
最后,由于 Python 代码解释器已成为高级 LLM 越来越强大的工具,通义千问团队还在之前开源的评估基准上评估了新模型利用这一工具的能力:
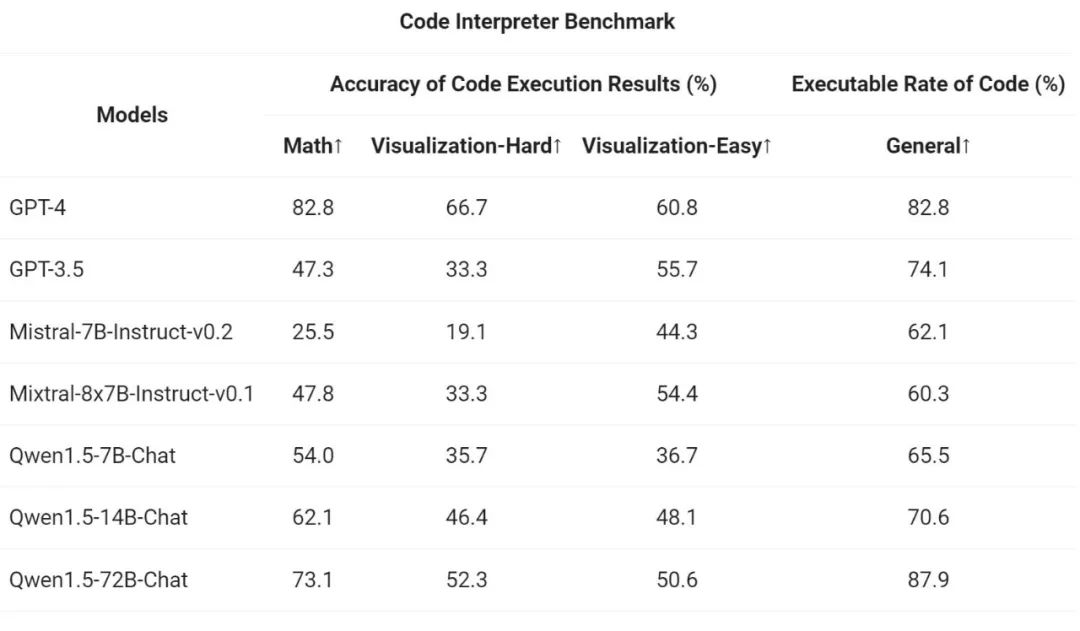
结果表明,较大的 Qwen1.5-Chat 模型通常优于较小的模型,其中 Qwen1.5-72B-Chat 接近 GPT-4 的工具使用性能。不过,在数学解题和可视化等代码解释器任务中,即使是最大的 Qwen1.5-72B-Chat 模型也会因编码能力而明显落后于 GPT-4。阿里表示,会在未来的版本中,在预训练和对齐过程中提高所有 Qwen 模型的编码能力。
Qwen1.5 与 HuggingFace transformers 代码库进行了集成。从 4.37.0 版本开始,开发者可以直接使用 transformers 库原生代码,而不加载任何自定义代码(指定 trust_remote_code 选项)来使用 Qwen1.5。
在开源生态上,阿里已经与 vLLM、SGLang(用于部署)、AutoAWQ、AutoGPTQ(用于量化)、Axolotl、LLaMA-Factory(用于微调)以及 llama.cpp(用于本地 LLM 推理)等框架合作,所有这些框架现在都支持 Qwen1.5。Qwen1.5 系列目前也可以在 Ollama 和 LMStudio 等平台上使用。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 未来科技在上海街头大放异彩!机器狗和外骨骼机器人助力2024 GDC势头大增
- 2024全球开发者先锋大会(2024GDC)将于3月23日-24日在上海举行。在这场科技嘉年华即将拉开帷幕之际,昨日上海西岸一场别开生面的活动吸引了众多市民的目光:穿戴外骨骼机器人,牵着机器狗漫步上海街头。这一幕犹如未来科技走进现实,点燃了上海这座城市的科技热情!是的,除了敲代码,我们还可以玩转科技新宠!01外骨骼机器人外骨骼机器人作为科幻元素的"扛把子",是一种能够增强人体肌肉力量和精确控制能力的装置。它通过硬件传感器收集人体信号,实时监测人机交互力矩,识别用户意图,并对步态做出响应。因此,它在重复劳作
- 10分钟前 产业 0
-
 正版软件
正版软件
- 三星Galaxy S24系列电池保护升级:智能贴心模式提升至三种
- 据消息,三星最新推出的GalaxyS24系列手机对电池保护功能进行了重要的改进,为用户提供了更多选择,延长手机电池的使用寿命。尤其对于夜间充电的用户来说,这一新功能无疑是一项重大的福音。用户现在可以根据自己的需要选择合适的充电模式,以更好地保护电池健康。这将有效地减少过度充电和过度放电对电池寿命的影响,让用户享受更长久的电池续航时间。三星的这一创新将进一步提升用户体验,满足用户对手机电池寿命的需求。在此前的OneUI6.1更新以及GalaxyS24系列发布之前,三星的“电池保护”功能相对简单,只有一个开关
- 20分钟前 三星 0
-
 正版软件
正版软件
- Rivian颠覆行业,在美国车主心中称霸,特斯拉略显失色
- 2月6日消息,最新的调查结果显示,美国消费者报告(ConsumerReports)公布了一项令人意外的发现。新兴电动汽车制造商Rivian竟然成功登顶,成为美国车主最喜欢的汽车品牌。这一荣誉甚至超越了享有盛誉的Mini、宝马、保时捷以及特斯拉等品牌。这个结果对于Rivian来说无疑是一个巨大的成就,也反映了消费者对于电动汽车的兴趣和需求的持续增长。Rivian的成功不仅仅在于其出色的性能和设计,更在于其对环境可持续性的承诺和创新的技术。这个调查结果对于整个汽车行业来说都具有重要的参考价值,将会对未来的市场
- 35分钟前 Rivian 0
-
 正版软件
正版软件
- 三星与伦敦地铁合作,推出Galaxy S24系列创新宣传活动,展示“即刻识别,即刻搜索”功能
- 三星与伦敦交通局合作,在伦敦地铁系统展开推广活动,以促销最新款GalaxyS24手机及其独特的AI功能“即圈即搜”。根据报道,GalaxyS24系列的主打AI功能是“即圈即搜”,它为用户提供了在任何屏幕上轻松圈选内容并通过谷歌搜索获取相关信息的便利。这一功能不仅适用于网络浏览器和相册等应用程序,甚至还可以在相机应用的实时取景画面中使用。举个例子,当用户在旅途中遇到未知的地标时,只需使用“即圈即搜”功能,就可以快速获得相关信息。这项功能的引入使用户能够更加方便地获取所需信息,提升了用户体验。为了进一步凸显创
- 50分钟前 三星 0
-
 正版软件
正版软件
- 比亚迪汽车首艘滚装运输船“开拓者1号”成功航行穿越大西洋,驶向欧洲
- 据知名博主“小迪快报”透露,比亚迪的首艘汽车滚装运输船“开拓者1号”已成功穿越好望角,目前正在向欧洲方向航行。这艘船在今年1月初分别在山东烟台港和深汕小漠国际物流港举行了盛大的交船和首航仪式。"开拓者1号"不仅是比亚迪的首艘汽车滚装运输船,更是国内首艘由本土船厂打造、专为中国汽车出口设计的运输船。这一重要事件标志着中国汽车海运自主时代的全新篇章已经开启。据了解,“开拓者1号”船长近200米,拥有7000个标准车位,采用LNG双燃料动力技术,适应多种航线需求,并能装载各类新能源车辆。该船充分融入比亚迪的绿色
- 1小时前 11:45 比亚迪 0













