鲁汶/清华/牛津等团队合作解决「语义分割的优化和评估」问题,提出全新方法的三篇论文
 发布于2024-11-30 阅读(0)
发布于2024-11-30 阅读(0)
扫一扫,手机访问
常用的优化语义分割模型的损失函数包括Soft Jaccard损失、Soft Dice损失和Soft Tversky损失。然而,这些损失函数与软标签不兼容,因此无法支持一些重要的训练技术,比如标签平滑、知识蒸馏、半监督学习和多标注员等。这些训练技术对于提高语义分割模型的性能和鲁棒性非常重要,因此需要进一步研究和优化损失函数,以支持这些训练技术的应用。
另一方面,常用的语义分割评价指标包括mAcc和mIoU。然而,这些指标会对尺寸较大的物体有偏好,从而严重影响模型的安全性能评估。
为了解决这些问题,研究人员在鲁汶大学和清华首先提出了JDT损失。JDT损失是对原有损失函数的微调,它包括了Jaccard Metric损失、Dice Semimetric损失和Compatible Tversky损失。JDT损失在处理硬标签时与原有的损失函数相等,同时也能完全适用于软标签。这一改进使得模型的训练更加准确和稳定。
研究人员在四个重要场景中成功应用了JDT损失:标签平滑、知识蒸馏、半监督学习和多标注员。这些应用展示了JDT损失对于提高模型准确性和校准性的能力。
 图片
图片
论文链接:https://arxiv.org/pdf/2302.05666.pdf
 图片
图片
论文链接:https://arxiv.org/pdf/2303.16296.pdf
除此之外,研究人员还提出了细粒度的评价指标。这些细粒度的评价指标对大尺寸物体的偏见较小,能提供更丰富的统计信息,并能为模型和数据集审计提供有价值的见解。
并且,研究人员进行了一项广泛的基准研究,强调了不应基于单个指标进行评估的必要性,并发现了神经网络结构和JDT损失对优化细粒度指标的重要作用。
 图片
图片
论文链接:https://arxiv.org/pdf/2310.19252.pdf
代码链接:https://github.com/zifuwanggg/JDTLosses
现有的损失函数
由于Jaccard Index和Dice Score是定义在集合上的,所以并不可导。为了使它们可导,目前常见的做法有两种:一种是利用集合和相应向量的Lp模之间的关系,例如Soft Jaccard损失(SJL),Soft Dice损失(SDL)和Soft Tversky损失(STL)。
它们把集合的大小写成相应向量的L1模,把两个集合的交集写成两个相应向量的内积。另一种则是利用Jaccard Index的submodular性质,在集合函数上做Lovasz拓展,例如Lovasz-Softmax损失(LSL)。
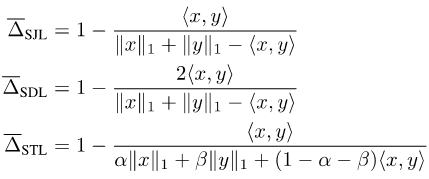 图片
图片
这些损失函数都假定神经网络的输出x是一个连续的向量,而标签y则是一个离散的二值向量。如果标签为软标签,即y不再是一个离散的二值向量,而是一个连续向量时,这些损失函数就不再兼容。
以SJL为例,考虑一个简单的单像素情况:
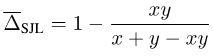 图片
图片
可以发现,对于任意的y > 0,SJL都将在x = 1时最小化,而在x = 0时最大化。因为一个损失函数应该在x = y时最小化,所以这显然是不合理的。
与软标签兼容的损失函数
为了使原有的损失函数与软标签兼容,需要在计算两个集合的交集和并集时,引入两个集合的对称差:
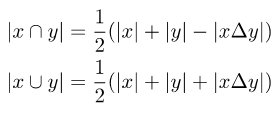 图片
图片
注意两个集合的对称差可以写成两个相应向量的差的L1模:
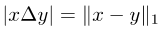 图片
图片
把以上综合起来,我们提出了JDT损失。它们分别是SJL的变体Jaccard Metric损失(JML),SDL的变体Dice Semimetric 损失(DML)以及STL的变体Compatible Tversky损失(CTL)。
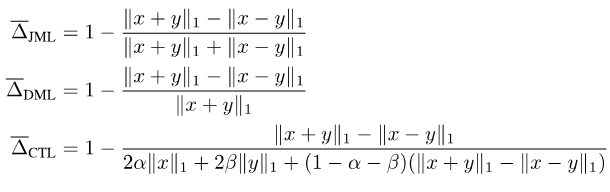 图片
图片
JDT损失的性质
我们证明了JDT损失有着以下的一些性质。
性质1:JML是一个metric,DML是一个semimetric。
性质2:当y为硬标签时,JML与SJL等价,DML与SDL等价,CTL与STL等价。
性质3:当y为软标签时,JML,DML,CTL都与软标签兼容,即x = y ó f(x,y) = 0。
由于性质1,它们也因此被称为Jaccard Metric损失和Dice Semimetric损失。性质2说明在仅用硬标签进行训练的一般场景下,JDT损失可以直接用来替代现有的损失函数,而不会引起任何的改变。
如何使用JDT损失
我们进行了大量的实验,总结出了使用JDT损失的一些注意事项。
注意1:根据评价指标选择相应的损失函数。如果评价指标是Jaccard Index,那么应该选择JML;如果评价指标是Dice Score,那么应该选择DML;如果想给予假阳性和假阴性不同的权重,那么应该选择CTL。其次,在优化细粒度的评价指标时,JDT损失也应做相应的更改。
注意2:结合JDT损失和像素级的损失函数(例如Cross Entropy损失,Focal损失)。本文发现0.25CE + 0.75JDT一般是一个不错的选择。
注意3:最好采用一个较短的epoch来训练。加上JDT损失后,一般只需要Cross Entropy损失训练时一半的epoch。
注意4:在多个GPU上进行分布式训练时,如果GPU之间没有额外的通信,JDT损失会错误的优化细粒度的评价指标,从而导致其在传统的mIoU上效果变差。
注意5:在极端的类别不平衡的数据集上进行训练时,需注意JDL损失是在每个类别上分别求损失再取平均,这可能会使训练变得不稳定。
实验结果
实验证明,与Cross Entropy损失的基准相比,在用硬标签训练时,加上JDT损失可以有效提高模型的准确性。引入软标签后,可以进一步提高模型的准确性和校准性。
 图片
图片
只需在训练时加入JDT损失项,本文取得了语义分割上的知识蒸馏,半监督学习和多标注员的SOTA。
 图片
图片
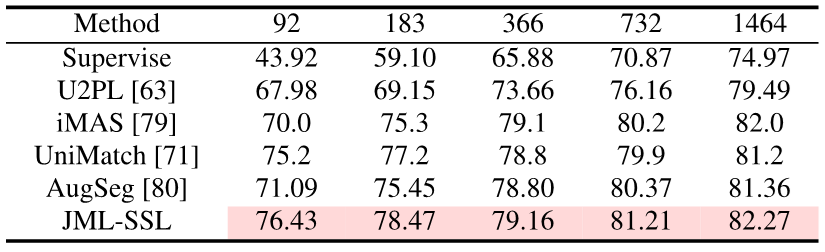 图片
图片
 图片
图片
现有的评价指标
语义分割是一个像素级别的分类任务,因此可以计算每个像素的准确率:overall pixel-wise accuracy(Acc)。但因为Acc会偏向于多数类,所以PASCAL VOC 2007采用了分别计算每个类别的像素准确率再取平均的评价指标:mean pixel-wise accuracy(mAcc)。
但由于mAcc不会考虑假阳性,从PASCAL VOC 2008之后,就一直采用平均交并比(per-dataset mIoU, mIoUD)来作为评价指标。PASCAL VOC是最早的引入了语义分割任务的数据集,它使用的评价指标也因此被之后的各个数据集所广泛采用。
具体来说,IoU可以写成:
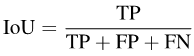 图片
图片
为了计算mIoUD,我们首先需要对每一个类别c统计其在整个数据集上所有I张照片的true positive(真阳性,TP),false positive(假阳性,FP)和false negative(假阴性,FN):
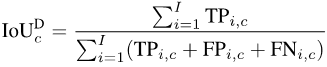 图片
图片
有了每个类别的数值之后,我们按类别取平均,从而消除对多数类的偏好:
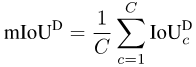 图片
图片
因为mIoUD把整个数据集上所有像素的TP,FP和FN合计在一起,它会不可避免的偏向于那些大尺寸的物体。
在一些对安全要求较高的应用场景中,例如自动驾驶和医疗图像,经常会存在一些尺寸小但是不可忽略的物体。
如下图所示,不同照片上的汽车的大小有着明显的不同。因此,mIoUD对大尺寸物体的偏好会严重的影响其对模型安全性能的评估。

细粒度的评价指标
为了解决mIoUD的问题,我们提出细粒度的评价指标。这些指标在每张照片上分别计算IoU,从而能有效的降低对大尺寸物体的偏好。
mIoUI
对每一个类别c,我们在每一张照片i上分别计算一个IoU:
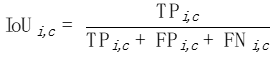 图片
图片
接着,对每一张照片i,我们把这张照片上出现过的所有类别进行平均:
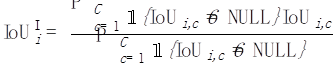 图片
图片
最后,我们把所有照片的数值再进行平均:
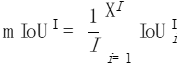 图片
图片
mIoUC
类似的,在计算出每个类别c在每一张照片i上的IoU之后,我们可以把每一个类别c出现过的所有照片进行平均:
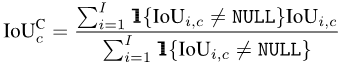
最后,把所有类别的数值再进行平均:
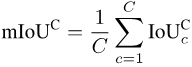
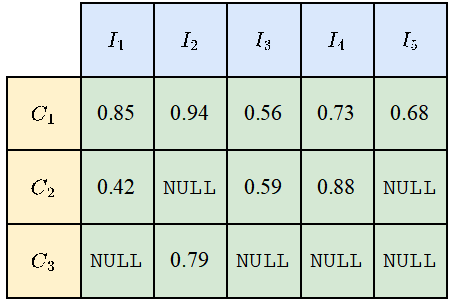
由于不是所有的类别都会出现在所有的照片上,所以对于一些类别和照片的组合,会出现NULL值,如下图所示。计算mIoUI时先对类别取平均再对照片取平均,而计算mIoUC时先对照片取平均再对类别取平均。
这样的结果是mIoUI可能会偏向那些出现得很频繁的类别(例如下图的C1),而这一般是不好的。但另一方面,在计算mIoUI时,因为每张照片都有一个IoU数值,这能帮助我们对模型和数据集进行一些审计和分析。
 图片
图片
最差情况的评价指标
对于一些很注重安全的应用场景,我们很多时候更关心的是最差情况的分割质量,而细粒度指标的一个好处就是能计算相应的最差情况指标。我们以mIoUC为例,类似的方法也可以计算mIoUI相应的最差情况指标。
对于每一个类别c,我们首先把其出现过的所有照片(假设有Ic个这样的照片)的IoU数值进行升序排序。接着,我们设q为一个很小的数字,例如1或者5。然后,我们仅用排序好的前Ic * q%张照片来计算最后的数值:
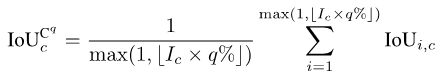 图片
图片
有了每个类c的数值之后,我们可以像之前那样按类别取平均,从而得到mIoUC的最差情况指标。
实验结果
我们在12个数据集上训练了15个模型,发现了如下的一些现象。
现象1:没有一个模型在所有的评价指标上都能取得最好的效果。每个评价指标都有着不同的侧重点,因此我们需要同时考虑多个评价指标来进行综合的评估。
现象2:一些数据集上存在部分照片使得几乎所有的模型都取得一个很低的IoU数值。这一方面是因为这些照片本身就很有挑战性,例如一些很小的物体和强烈的明暗对比,另一方面也是因为这些照片的标签存在问题。因此,细粒度的评价指标能帮助我们进行模型审计(发现模型会犯错的场景)和数据集审计(发现错误的标签)。
现象3:神经网络的结构对优化细粒度的评价指标有着至关重要的作用。一方面,由ASPP(被DeepLabV3和DeepLabV3+采用)等结构所带来的感受野的提升能帮助模型识别出大尺寸的物体,从而能有效提高mIoUD的数值;另一方面,encoder和decoder之间的长连接(被UNet和DeepLabV3+采用)能使模型识别出小尺寸的物体,从而提高细粒度评价指标的数值。
现象4:最差情况指标的数值远远低于相应的平均指标的数值。下表展示了DeepLabV3-ResNet101在多个数据集上的mIoUC和相应的最差情况指标的数值。一个值得以后考虑的问题是,我们应该如何设计神经网络结构和优化方法来提高模型在最差情况指标下的表现?
 图片
图片
现象5:损失函数对优化细粒度的评价指标有着至关重要的作用。与Cross Entropy损失的基准相比,如下表的(0,0,0)所示,当评价指标变得细粒度,使用相应的损失函数能极大的提升模型在细粒度评价指标上的性能。例如,在ADE20K上,JML和Cross Entropy损失的mIoUC的差别会大于7%。
 图片
图片
未来工作
我们只考虑了JDT损失作为语义分割上的损失函数,但它们也可以应用在其他的任务上,例如传统的分类任务。
其次,JDT损失只被用在标签空间中,但我们认为它们能被用于最小化任意两个向量在特征空间上的距离,例如用来替代Lp模和cosine距离。
参考资料:
https://arxiv.org/pdf/2302.05666.pdf
https://arxiv.org/pdf/2303.16296.pdf
https://arxiv.org/pdf/2310.19252.pdf
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 比亚迪城市领航系统即将落地,腾势N7成首款应用车型
- 比亚迪宣布城市领航(城市NOA)系统将于3月30日首批落地,腾势N7将成为首款应用该技术的车型。消息人士透露,深圳等几个重要城市可能成为首批开放城市。该系统将在比亚迪的20余款车型中推出。随着智能驾驶系统的重要性日益突显,比亚迪逐渐减少对外部供应商如Momenta、大疆、东软睿驰、福瑞泰克等的依赖,并加强自主研发高级算法的开发和应用。城市NOA成为当前汽车行业的竞争焦点,吸引了多家领先车企的布局。理想汽车在2023年底宣布,其城市NOA的目标是覆盖110个城市。小鹏汽车在今年1月份宣布其城市NGP已覆盖了
- 7分钟前 比亚迪 0
-
 正版软件
正版软件
- 理想汽车CEO李想:年终奖制度合理,管理高效
- 2月6日,汽车博主@大D有态度在社交媒体上透露,据消息称,理想汽车2023年的年终奖非常丰厚。这一消息引起了广泛关注,理想汽车CEO李想也亲自回应了此事。据该博主分享的截图显示,在脉脉理想社区进行的一项关于年终奖的投票中,有97人表示自己的年终奖达到了5个月以上,而更多的人则表示尚不清楚具体情况。这一数据似乎暗示着理想汽车在年终奖方面的慷慨。李想在接受采访时表示,公司坚持赏罚分明的原则,认为奖罚不分明是组织低效的主要原因。他强调,理想汽车不仅致力于学习先进流程,还注重学习利益分配。根据公司的规定,如果在2
- 17分钟前 李想 0
-
 正版软件
正版软件
- 四年流畅体验超过长期维护:一加总裁阐述系统更新策略
- 在当今智能手机市场中,系统更新服务已成为衡量手机厂商对产品关注度的重要标准。目前,只有三星和谷歌两大巨头承诺为其旗舰机型——GalaxyS24系列和Pixel8系列提供长达七年的Android系统更新。相比之下,一加对其新旗舰一加12的系统更新承诺则较为保守,仅为四年的系统更新,并额外提供一年的安全更新。这一举措可能引发用户对于一加手机的长期支持能力的担忧。然而,需要注意的是,系统更新服务只是衡量手机厂商关注用户体验程度的一个方面,其他因素如硬件性能、软件功能、售后服务等同样重要。用户在选择手机时,应全面
- 32分钟前 一加 0
-
 正版软件
正版软件
- 华为公布 2023 年分红方案:投资高达 770 亿元,使至少 14 万员工受益
- 华为内部已发布董秘1号文件,公布2023年年度分红方案。根据该方案,ESOP每股分红为1.5元,税后收益为15.3%。与去年相比,税后收益有所降低,这可能意味着华为未来的发展将面临一定的资金压力和挑战。根据本站的了解,华为投资控股有限公司是一家由员工持有的民营企业,没有任何政府部门或机构持有股份。员工持股计划是华为的核心制度之一,旨在激励员工的创新和奉献精神。该计划的参与者包括在职员工和退休保留人员,截至2022年底,参与人数已达142,315人。根据最新的分红方案,华为计划向员工发放约770.85亿元的
- 47分钟前 华为 0
-
 正版软件
正版软件
- 未来科技在上海街头大放异彩!机器狗和外骨骼机器人助力2024 GDC势头大增
- 2024全球开发者先锋大会(2024GDC)将于3月23日-24日在上海举行。在这场科技嘉年华即将拉开帷幕之际,昨日上海西岸一场别开生面的活动吸引了众多市民的目光:穿戴外骨骼机器人,牵着机器狗漫步上海街头。这一幕犹如未来科技走进现实,点燃了上海这座城市的科技热情!是的,除了敲代码,我们还可以玩转科技新宠!01外骨骼机器人外骨骼机器人作为科幻元素的"扛把子",是一种能够增强人体肌肉力量和精确控制能力的装置。它通过硬件传感器收集人体信号,实时监测人机交互力矩,识别用户意图,并对步态做出响应。因此,它在重复劳作
- 1小时前 12:40 产业 0













