ABBYY FineReader 15(Windows系统)OCR文字识别软件拥有强大的OCR识别功能,能够对这些竖排排版的文档进行准确的识别,另外对于一些具有反转颜色(白色字符和黑暗背景的图像)的文档,也能有效识别。
对于一些港版、台版的书籍,可能会采用竖排的排版方式,识别这类竖排排版或者反转文本的文档时,用户需使用ABBYY FineReader 15 OCR文字识别软件的OCR编辑器功能,将文档导入到OCR项目中,在OCR识别的过程中,对文本的识别进行相对应的设置。
图1:OCR项目
第一、识别图像
首先将包含竖排文字的图像文件导入到ABBYY FineReader 15的OCR编辑器中。导入图像后,软件将自动开启OCR识别,这个过程花费的时间视乎文档的复杂程度而定。
图2:识别图像
第二、竖排文字的识别
当使用ABBYY FineReader 15默认的识别设置时,图像中的竖排文字会出现识别错误,从下图的示例可以看出,默认识别程序完成后,右边的文字面板出现了乱码。
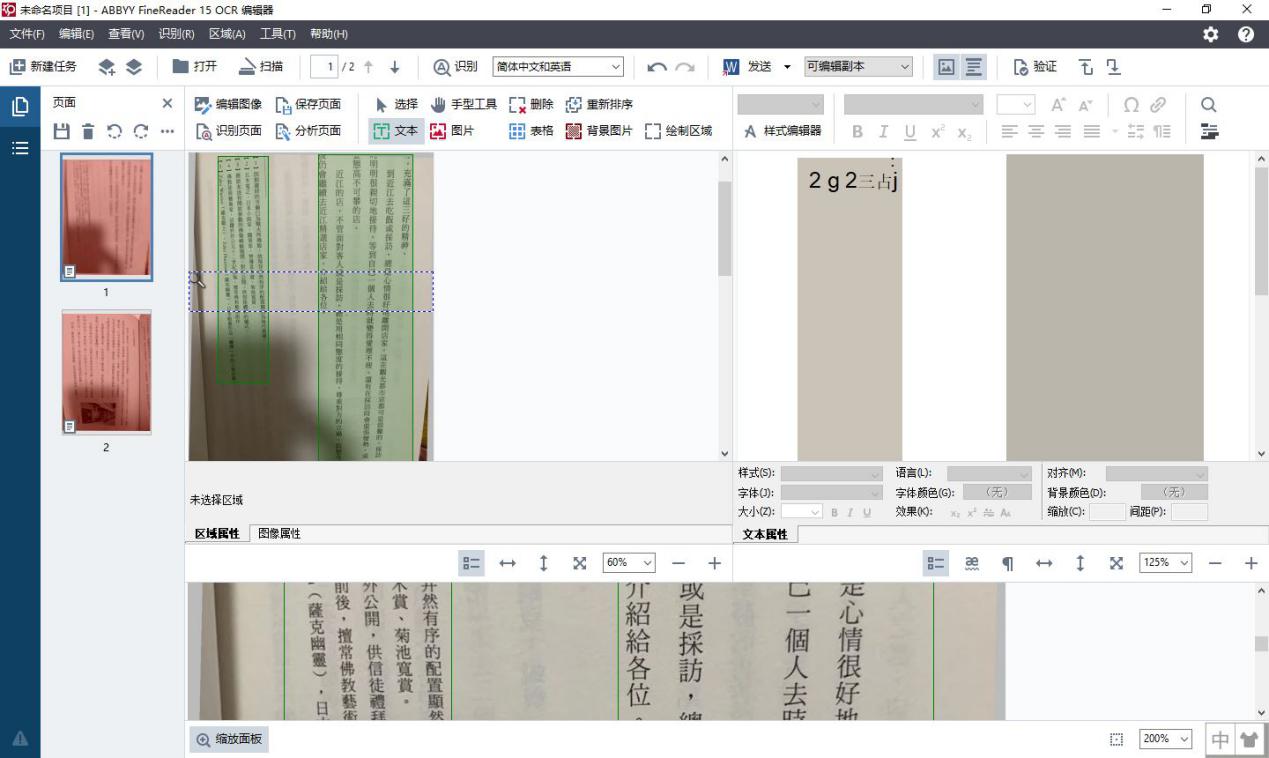
图3:错误识别竖排文字
第三、修正错误识别
为了更准确地修正错误识别竖排文字的结果,用户可以使用识别面板中的属性面板设置识别的文字方向。右击选中的文本区域,并选择其中的“属性”,即可打开该文本区域的属性面板。
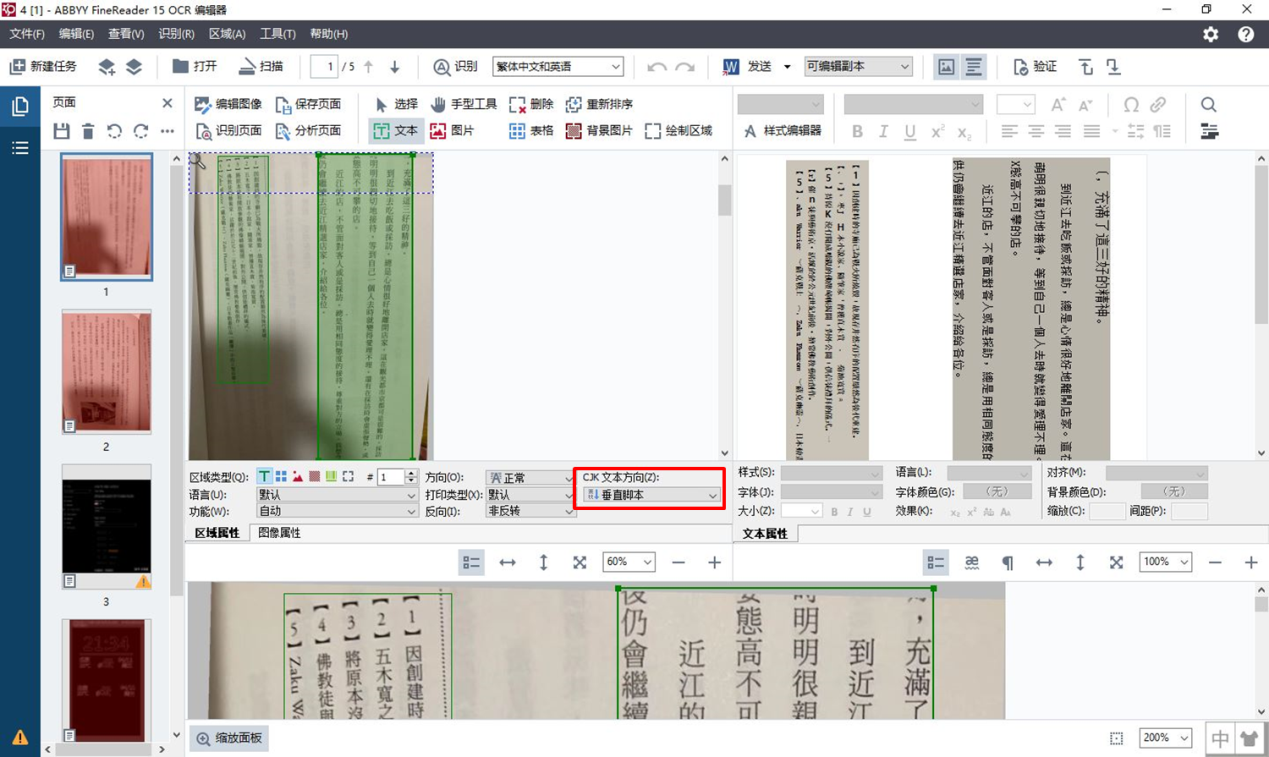
图4:更改文字方向
在区域属性面板的“文本方向”中选择垂直脚本,然后再次单击“识别”按钮,对图像重新识别一次。从下图看到,再次识别后文本已正常显示。
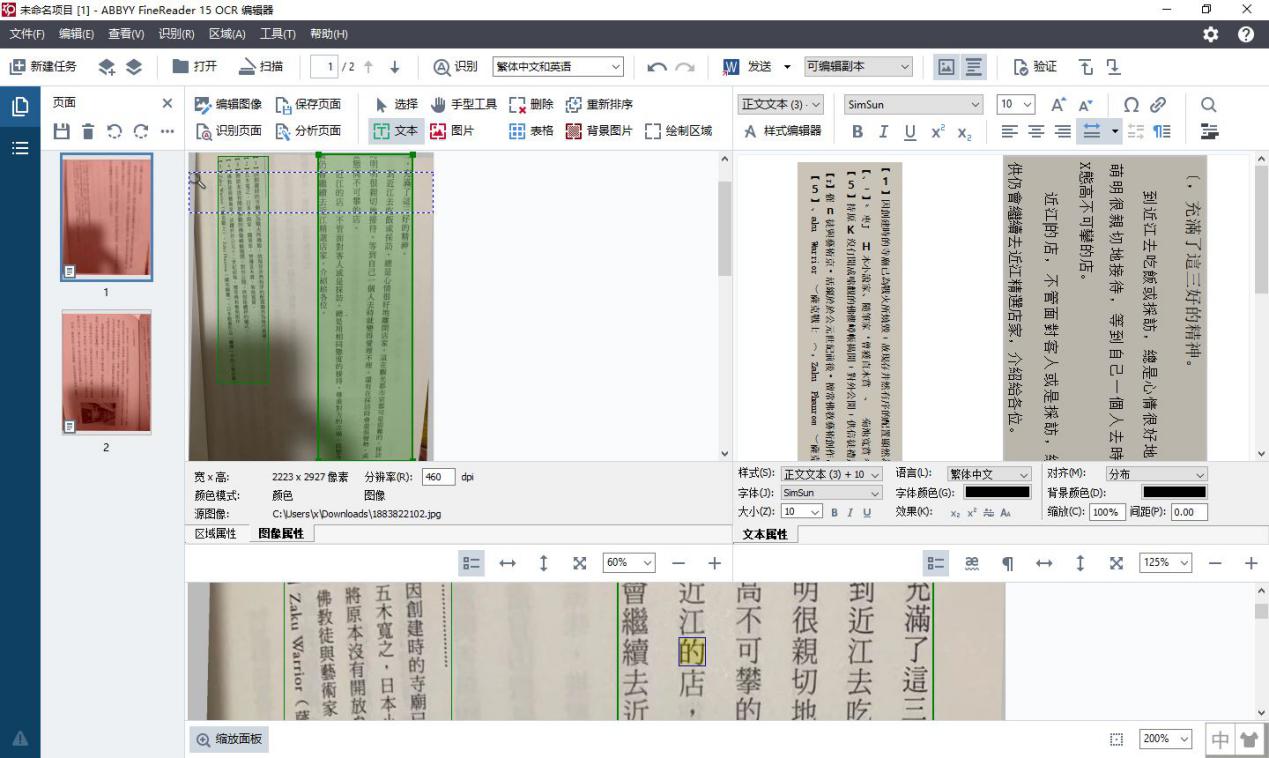
图5:修正文字方向
第四、反转文字的识别
除了竖排文字外,ABBYY FineReader 15还能对反转的文本进行准确识别。下图的示例中,可以看到图像的底色很暗,文字的颜色比较亮,OCR识别后,一些文字出现背灰的错误。
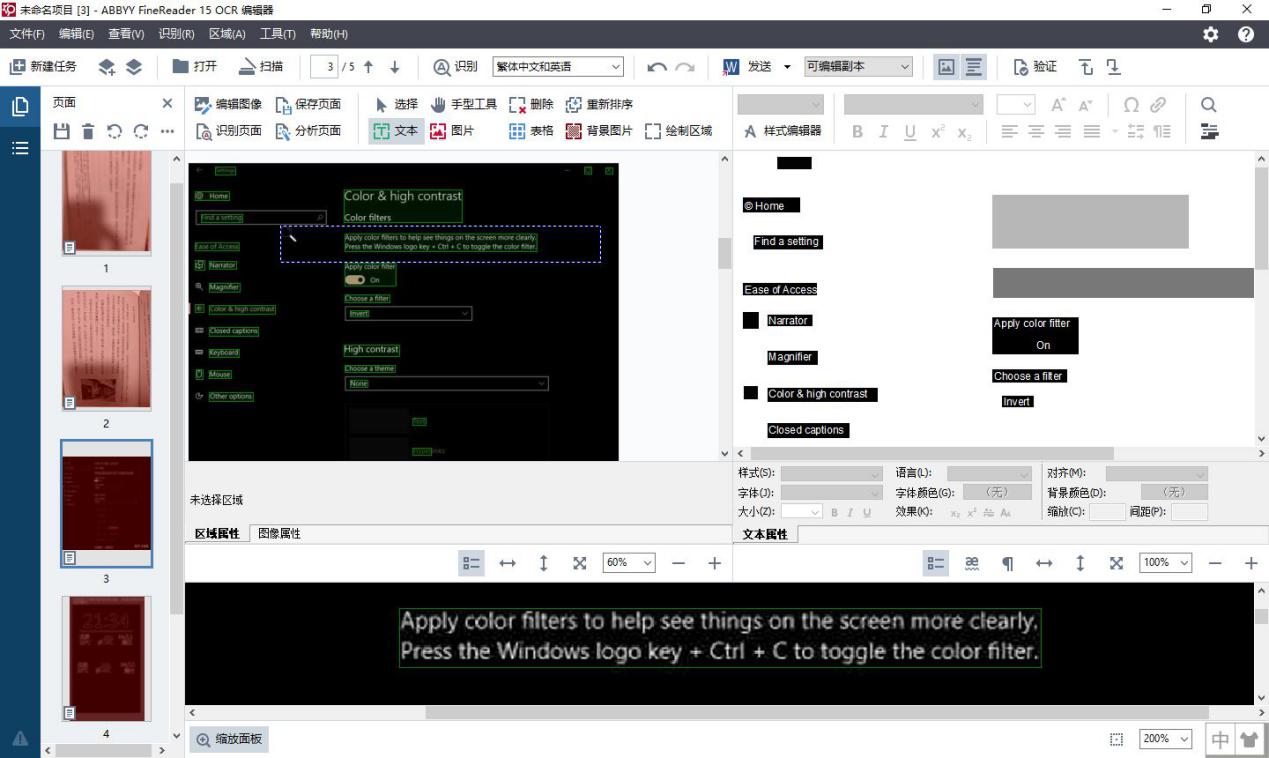
图6:错误识别反转文字
单击所选区域的属性面板,并在其中的“反向”选项卡中选择“反转”,然后再次运行识别程序,即可修正图像的反转文字识别错误。
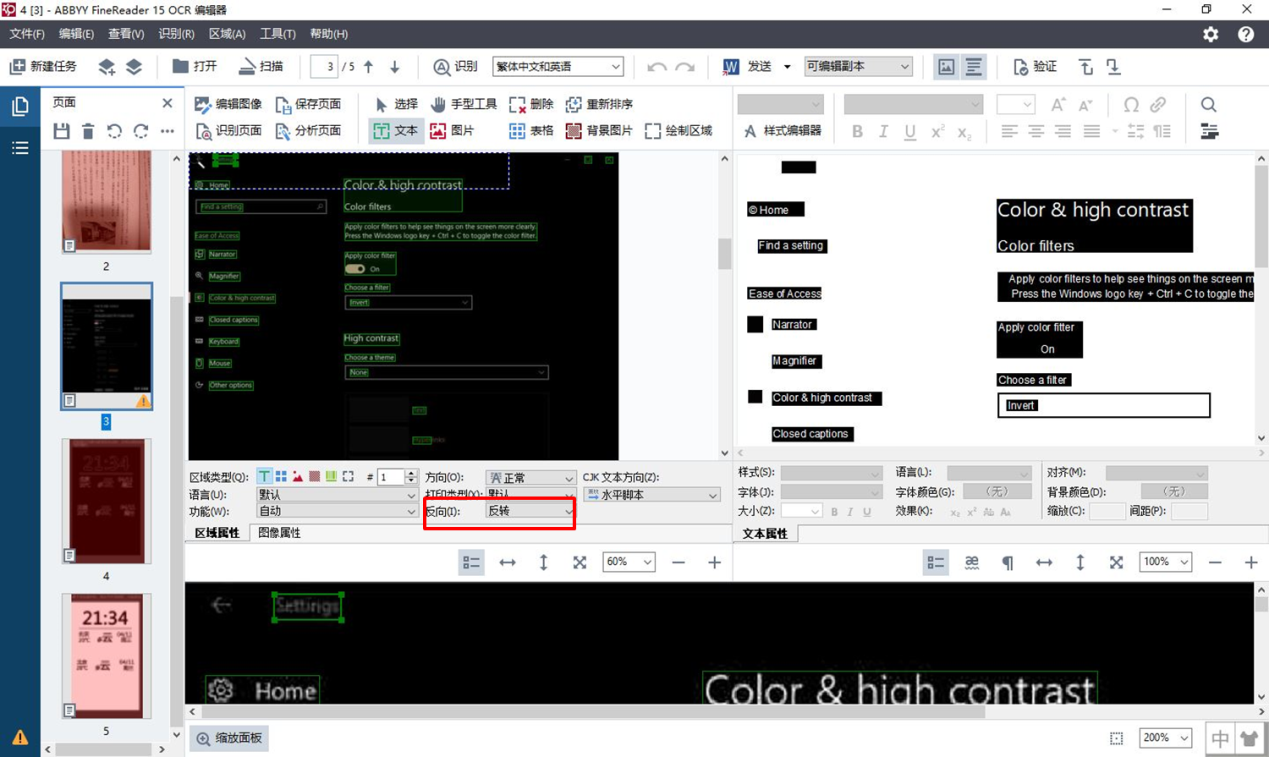
图7:修正反转文字
ABBYY FineReader 15不仅能对包含文本信息的PDF文档进行识别,还能对不包含文本层的图像等进行识别。通过借助OCR编辑器的高级识别功能,更能实现对竖排文字、反转文字的识别。


