在识别PDF文档时,我们可能会遇到文档中存在多种语言、多种不同类型文字字符的情况。在ABBYY FineReader 15(Windows系统)OCR文字识别软件的默认语言数据下,可能无法识别PDF文档中的某些字符。为了更好、更准确地识别文档,用户可以创建包含文档识别数据所需的字符语言。
通过创建多个OCR的语言组,用户可在识别PDF文档时指定使用这些语言组,通过多重语言的识别,实现更准确的文本数据识别,下面就让小编来给您详解。
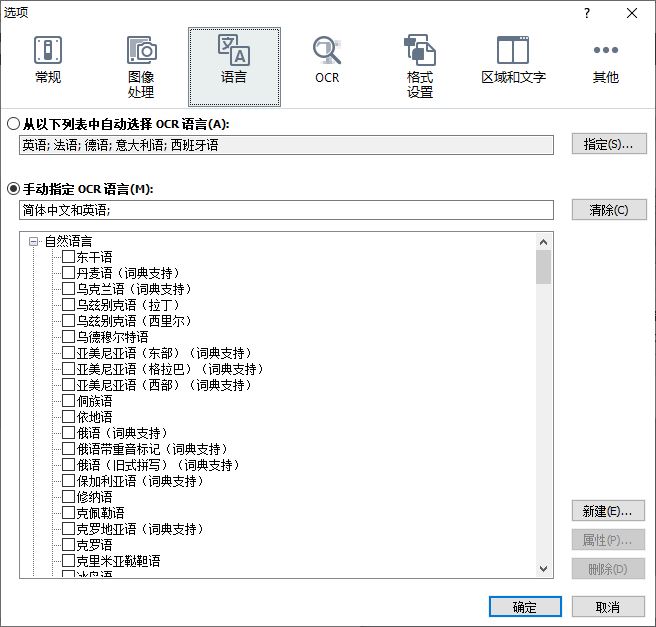
图1:OCR项目
第一、创建用户语言
打开ABBYY FineReader 15 OCR文字识别软件的选项面板(通过单击工具>选项 打开选项面板),并单击其中的“语言”选项卡,用户可在此自动选择OCR语言或者手动指定OCR语言,当然也可以通过“新建”创建用户语言。
图2:语言选项卡
第二、根据现有语言创建
在ABBYY FineReader 15 的语言选项卡,单击“新建”,在“新建语言或组”中选中“根据现有语言创建新语言”选项。由于示例中的图像包含了一些繁体中文字符,在此,我们可以添加一个“繁体中文”的语言。

图3:新建语言
第三、语言属性
在ABBYY FineReader 15 中完成了用户语言创建后,即可打开语言的属性面板。用户在语言的属性面板中,可对语言的源语言、字母、词典的属性进行设置,并可打开高级属性进行更为详细的设置。
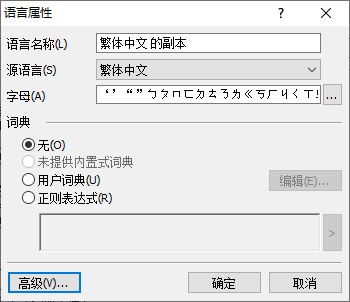
图4:语言属性
第四、创建语言组
除了设置单一的用户语言外,用户还可以创建一个特定的语言组合,并将其保存起来,供长期的文档识别使用。同样地,打开语言选项卡,在“新建”中选中“新建语言或组”,然后再将需要的语言添加进组。
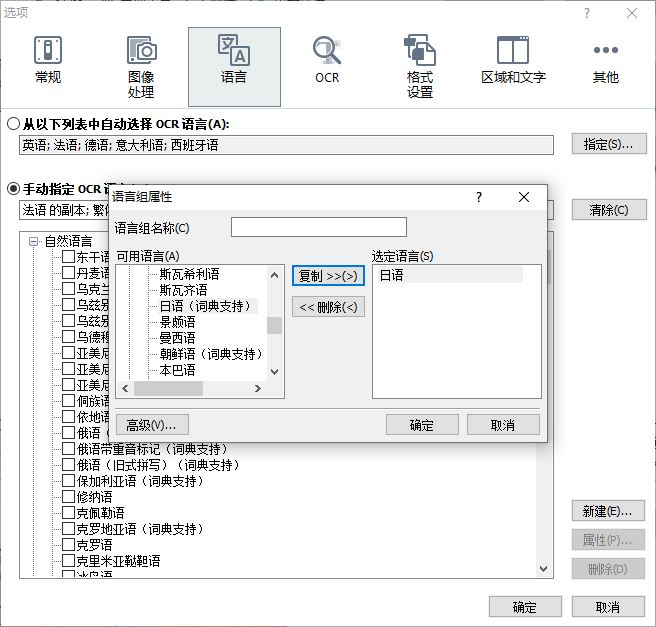
图5:创建语言组
第五、再次识别
在ABBYY FineReader 15 完成用户语言创建后,需再次点击软件中的“识别”按钮,再次识别文档。从示例中可以看到,在第一次文本识别中未被识别的繁体文字已被准确识别。

图6:创建语言后的识别结果
ABBYY FineReader 15 OCR文字识别软件让用户可以通过创建用户语言的方式,识别PDF文档中各种类型的字符文本,确保更加准确的识别结果输出,减少人工修正识别结果的繁琐。


