Iambic、英伟达和加州理工学院合作开发多尺度深度生成模型,实现状态特异性蛋白质-配体复合物结构预测超越AF2
 发布于2024-12-02 阅读(0)
发布于2024-12-02 阅读(0)
扫一扫,手机访问
蛋白质和小分子配体结合形成的复合物在生命中起着至关重要的作用。尽管科学家在蛋白质结构预测方面取得了一些进展,但目前的算法并不能有效地系统预测配体结合的结构以及其对蛋白质折叠的调节作用。这表明在这一领域仍有许多挑战需要克服,以更深入地理解蛋白质与配体之间的相互作用。
为了弥合蛋白质和配体之间的结构差异,AI 制药公司 Iambic Therapeutics、英伟达(Nvidia Corporation)以及加州理工学院(California Institute of Technology)的研究人员共同开发了一种名为 NeuralPLexer 的计算方法。这一方法能够仅通过蛋白质序列和配体分子的结构图输入,直接预测蛋白质-配体复合物的结构。NeuralPLexer 的研发代表着在药物设计领域取得的一项重大突破,为新药研发提供了更加高效、精准的工具和方法。这一技术的推出,有望加速药物研究和开发的进程,为生物医药领域带来更多突破性的创新。
NeuralPLexer 采用深度生成模型以原子分辨率对结合复合物的三维结构及其构象变化进行采样。该模型基于扩散过程,该过程结合了基本的生物物理约束和多尺度几何深度学习系统,以分层方式迭代采样残留级接触图和所有重原子坐标。
NeuralPLexer 在预测酶工程和药物发现中关键靶点的结构测定实验方面表现一致,并且在加速功能蛋白和小分子设计的蛋白组学范围内展现出巨大的潜力。
该研究以「State-specific protein–ligand complex structure prediction with a multiscale deep generative model」为题,于 2024 年 2 月 12 日发布在《Nature Machine Intelligence》。

静态蛋白质结构预测不足以支持药物设计
深度学习在从一维氨基酸序列预测蛋白质结构方面取得了巨大进步。最先进的蛋白质结构预测网络,例如 AlphaFold2 (AF2),采用基于蛋白质结构的进化、物理和几何约束的预测管线。具体来说,从多重序列比对(MSA)或蛋白质语言模型(PLM)和专门的神经网络中提取的进化约束,与基于序列的信息和几何表示系统地结合,从而实现端到端的三维(3D)结构预测 。
尽管在预测蛋白质的静态结构方面取得了显著进展,但对蛋白质折叠问题的单一结构公式提供的信息有限,无法充分了解蛋白质的功能。此外,这种结构公式还被发现不适用于基于结构的药物设计。
生成式深度学习是一种替代范式
然而,与受体构象的实质性变化相结合的蛋白质-配体复合物的计算模型,受到模拟缓慢蛋白质状态转变的高昂成本的阻碍。生成式深度学习的最新发展提供了一种替代范式,并且在理解复杂视觉和语言领域方面取得了实质性进展。
生成建模的两个值得注意的策略包括(1)自回归模型,在序列数据(例如自然语言和基因组学)的 Transformer 网络中广泛采用,基于顺序过程;(2) 基于扩散的生成模型,利用随机过程通过从先验分布中采样并使用神经网络逐步逆转噪声过程来生成数据。
科学家已经证明,深度生成模型能够产生具有经过实验验证的功能的从头设计的蛋白质,包括用于蛋白质序列设计的语言模型和用于蛋白质主链生成的扩散模型。扩散模型可以有效地模拟蛋白质骨架之外的分子结构,特别是在分子对接和基于结构的药物设计方面。
然而,目前为止,还没有团队开发出能够以原子分辨率直接预测结合复杂结构且精度可与结构测定实验相媲美的生成模型。
深度生成模型预测蛋白质-配体复杂结构
在最新的研究中,Iambic、英伟达、加州理工学院团队介绍了 NeuralPLexer,这是一种计算系统,它使用由生物物理归纳偏差提供的深度生成模型来预测蛋白质-配体复杂结构。该方法可以以从 PLM 获得的辅助特征和从实验解析的同源物或计算模型检索的模板蛋白质结构为条件,直接生成给定蛋白质序列和配体分子图输入的结合复合物的结构集合。
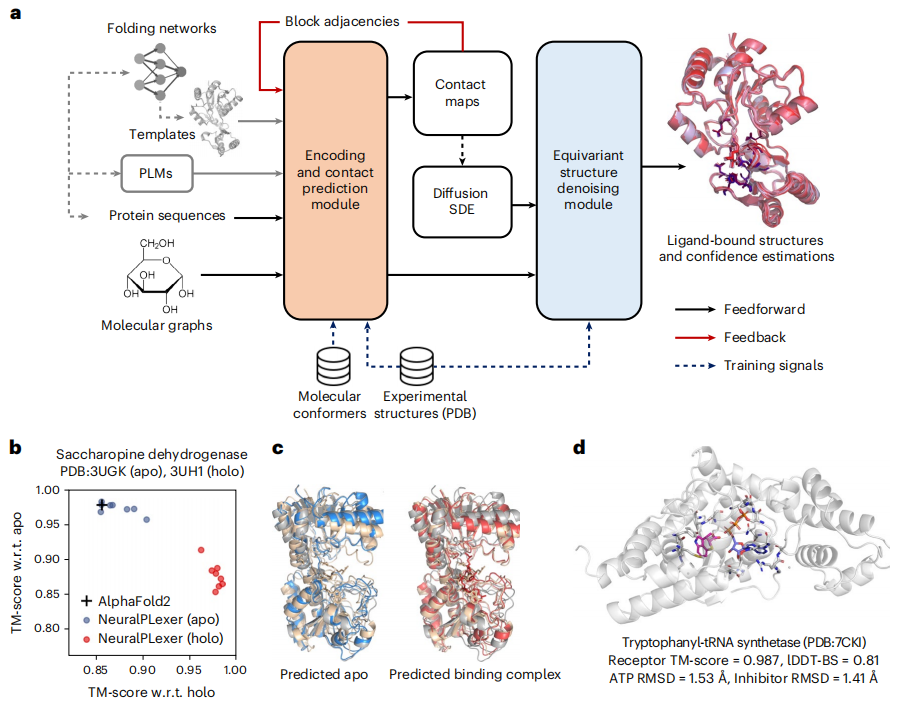
预测管线和底层神经网络架构都旨在反映生物分子复合物的多尺度层次结构。具体而言,NeuralPLexer 包括:
(1)基于图的网络,将单个小分子和氨基酸图的原子级化学和几何特征编码为张量表示,通过受物理启发的网络架构实现,该网络架构经过百万级分子构象和生物活性数据库的训练;
(2)接触预测模块(CPM),在最近的视觉语言模型和折叠预测网络的推动下,使用基于注意力的网络生成残留尺度的分子间距离分布、粗粒度接触图和相关的配对表示;
(3)等变结构去噪模块 (ESDM),用于生成以原子尺度和残留尺度网络的输出为条件的结合复杂原子结构,使用等变的结构化去噪扩散过程,并保留蛋白质和配体分子的手性约束。
在对蛋白质-配体盲对接进行评估时,与 PDBBind2020 基准上性能最佳的现有方法相比,NeuralPLexer 将预测成功率提高了高达 78%。在针对挑战性目标的配体结合位点设计中,NeuralPLexer 仅使用计算生成的截短支架即可有效恢复高达 45% 的结合位点结构。
与现有的基于物理的方法相比,这代表了成功率的质的提高。此外,NeuralPLexer 在选择性预测受诱导拟合结合或构象选择影响的蛋白质结构方面比现有方法表现出系统优势;在两个具有大结构可塑性的配体结合蛋白基准数据集上,NeuralPLexer 优于最先进的蛋白质结构预测算法 AF2,最高的模板建模得分 (TM-score)(平均 0.906)以及配体结合后发生重大构象变化的结构域的准确性提高了 11-13%。
NeuralPLexer 模拟配体结合和蛋白质结构变化的多功能能力可以快速表征构象景观,从而促进更好地理解控制蛋白质功能的分子机制,从而有助于在蛋白质组规模上识别治疗干预和蛋白质工程的非常规靶点。
结语
作为一种数据驱动的方法,NeuralPLexer 具有通用性,并且可以通过整合更好的实验和生物信息数据来持续改进。来自更广泛社区的训练和基准数据集的管理的改进,可能能够对没有实验确定的同源物蛋白质家族进行更系统的分析,并将该方法扩展到更具挑战性的系统,例如翻译后修饰和多态大型异聚蛋白质复合物。
该研究为探索这些方向提供了通用的计算框架,为快速准确的蛋白质-配体复合物结构预测铺平了道路,从而促进结构生物学、药物发现和蛋白质工程领域的进步。
论文链接:https://www.nature.com/articles/s42256-024-00792-z
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 长城汽车城市真无图NOA智能驾驶新进展视频曝光引发热议
- 近日,一段长城汽车内部会议的视频意外曝光,引发了网络热议。视频展示了长城汽车在智能驾驶领域取得的最新进展,让人们窥见了智能驾驶技术可能的未来。长城汽车CTO王远力在日前对此事进行了回应。他表示,这段视频是几个月前拍摄的智驾内部展示资料,既然已经受到了大家的关注,那就索性公开分享。他还透露,目前智驾团队正在全力以赴,全场景、真无图的智能驾驶技术是他们的目标,而且不久后就会有更强大的城市NOA与大家见面。据小编了解,从这段流出的视频来看,长城汽车的真无图智能驾驶方案具有显著的技术优势。该方案不依赖于高精度地图
- 11分钟前 长城汽车 0
-
 正版软件
正版软件
- 长安深蓝G318硬派越野车型将在成都亮相,预计二季度上市!
- 深蓝汽车表示,他们将于3月18日在成都举办一场盛大的发布会,展示备受期待的首款硬派越野车G318。这次活动被称为“深蓝超级增程进化日暨G318亮相发布会”,吸引了众多关注者的目光。深蓝汽车旗下的这款越野车备受瞩目,人们期待着在活动上与它正式相遇。这次发布会将为观众提供一个近距离了解G318的机会,展示其强大的性能和设计特色。深蓝汽车致力于推出高品质的汽车产品,G方盒子硬派越野车市场正因市场上方程豹豹5和坦克400Hi4-T等车型的热销而备受关注。随着越来越多的车企加入竞争,该市场正在变得更加激烈。深蓝汽车
- 26分钟前 深蓝汽车 0
-
 正版软件
正版软件
- 长安深蓝G318即将亮相,新一代科技硬派SUV即将问世
- 长安汽车旗下的深蓝汽车即将在3月18日在成都举行“深蓝超级增程进化日暨G318亮相发布会”。备受瞩目的全新SUV车型G318,被誉为“科技新硬派”,将在活动中引人注目。这款车型采用先进的1.5T发动机与电机组成的增程系统,为驾驶者提供更强劲的动力和更长的续航里程。四驱版本的G318将配备前后双电机,总功率高达316kW,带来出色的加速和越野性能。此外,该车还创新地支持原地掉头功能,通过后轮反转实现更小的转弯半径,与比亚迪方程豹豹5的“豹式掉头”有异曲同工之妙,这无疑将大大增强其在复杂路况下的操控灵活性。据
- 41分钟前 深蓝汽车 0
-
 正版软件
正版软件
- 我国成功获得高纯度镱-176 同位素并制备镥-177,纯度超过 99.9%
- 据3月9日消息,中核集团旗下的核工业理化工程研究院/有限公司在去年12月成功采用先进工艺生产高丰度克量级镱-176同位素产品,这标志着该公司首次在国际上实现了这一重要里程碑。这一成就不仅为我国摆脱了对镱-176同位素产品长期依赖进口的局面,也展示了中国在核工业领域的技术实力和创新能力。这一进展将有望推动我国核工业的发展,为国内同位素产品的生产提供了更加可靠的保障,为我国核技术研究根据中核集团的最新消息,中国工程物理研究院核物理与化学研究所中国绵阳研究堆(CMRR)经辐照成功制备出1.59Ci的无载体镥-1
- 56分钟前 镱 176 镥 177 0
-
 正版软件
正版软件
- 美国发布 UFO 调查报告:未发现外星技术证据,大多数目击事件解释为误解
- 根据美国国防部全域异常解决办公室(AARO)发布的研究报告,经过近80年的调查,他们没有发现任何证据表明存在外星技术。该报告涉及不明飞行物、外星人和外星智慧生物等相关议题。“所有分类级别的所有调查工作都得出一个结论:大多数目击事件都是普通物体和现象,是误认。”作为2023财年国防授权法的一部分,这份长达63页的报告是AARO调查结果的第一卷,涵盖了1945年至2023年10月期间的事件。第二卷报告预计将在今年晚些时候发布,将包括对2023年11月至2024年4月期间所完成研究结果的详细分析。一份报告指出,
- 1小时前 09:35 不明飞行物 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1830天前
-
 2
2
- Overture设置踏板标记的方法
- 1667天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1657天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1855天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1821天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1817天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1832天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1853天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00