生成25帧高质量动画的两步方法,使用SVD计算占比为8% | 可在线播放
 发布于2024-12-02 阅读(0)
发布于2024-12-02 阅读(0)
扫一扫,手机访问
耗费的计算资源仅为传统Stable Video Diffusion(SVD)模型的2/25!
AnimateLCM-SVD-xt发布,一改视频扩散模型进行重复去噪,既耗时又需大量计算的问题。
先来看一波生成的动画效果。
赛博朋克风轻松驾驭,男孩头戴耳机,站在霓虹闪烁的都市街道:
 图片
图片
写实风也可以,一对新婚夫妇依偎在一起,手捧精致花束,在古老石墙下见证爱情:
 图片
图片
科幻风,也有了外星人入侵地球的即视感:
 图片
图片
AnimateLCM-SVD-xt由来自香港中文大学MMLab、Avolution AI、上海人工智能实验室、商汤研究院的研究人员共同提出。
 图片
图片
2~8步就能生成25帧分辨率576x1024的高质量动画,并且无需分类器引导,4步生成的视频就能实现高保真,比传统SVD更快、效率更高:
 图片
图片
目前,AnimateLCM代码即将开源,有在线demo可试玩。
上手试玩demo
在demo界面可以看到,AnimateLCM目前有三个版本,AnimateLCM-SVD-xt是通用图像到视频生成;AnimateLCM-t2v倾向个性化文本到视频生成;AnimateLCM-i2v为个性化图像到视频生成。
 图片
图片
下面是一个配置区域,可以选择基础的Dreambooth模型,也可以选择LoRA模型,并通过滑动条调整LoRA alpha值等。
 图片
图片
接下来可以输入Prompt、负面prompt,指导生成的动画内容和质量:
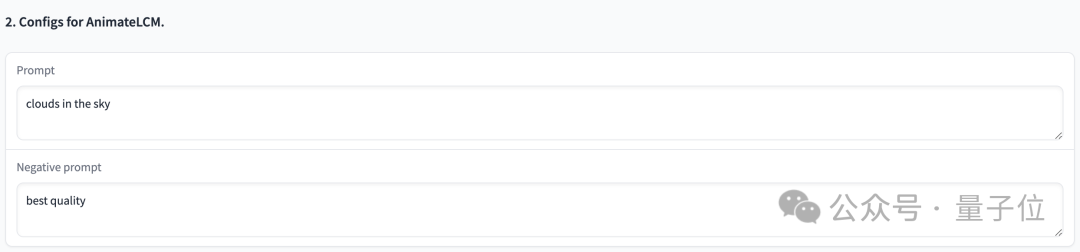 图片
图片
还有一些参数可以调整:
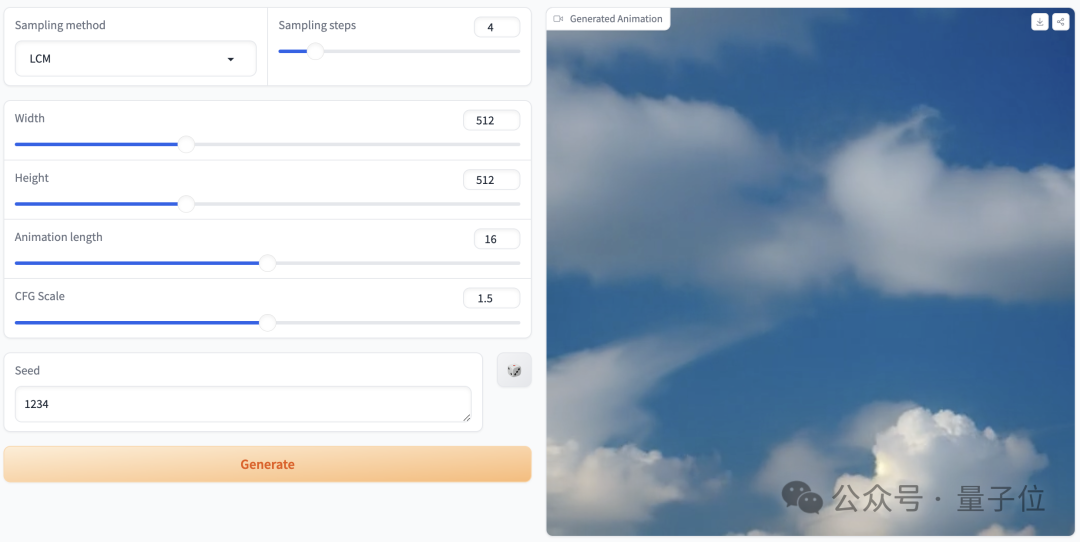 图片
图片
我们上手体验了一把,提示词为“clouds in the sky”,参数设置如上图,采样步骤仅为4步时,生成的效果是这样婶儿的:
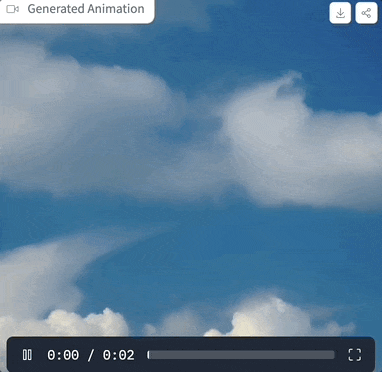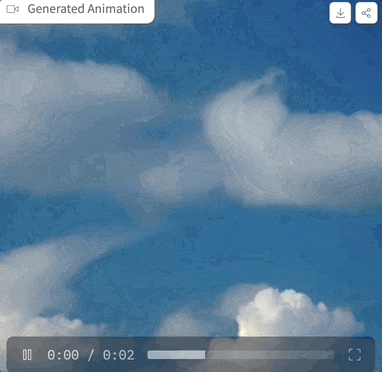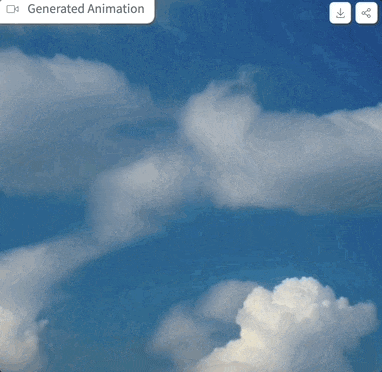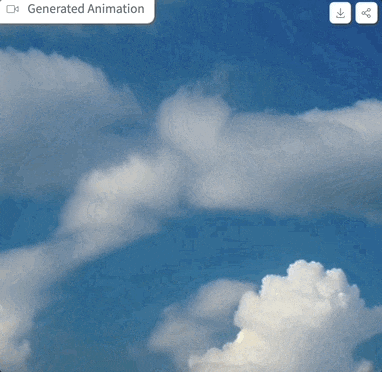 图片
图片
采样步骤为25步时,提示词“a boy holding a rabbit”,效果如下:
 图片
图片
再看看一波官方放出的展示效果。2步、4步、8步效果对比如下:
 图片
图片
步数越多,动画质量越好,仅4步AnimateLCM就能做到高保真:
 图片
图片
各种风格都能实现:
 图片
图片
 图片
图片
怎么做到的?
要知道,虽然视频扩散模型因能生成连贯且高保真度的视频而受到越来越多的关注,但难题之一是迭代去噪过程不仅耗时而且计算密集,这也就限制了它的应用范围。
而在AnimateLCM这项工作中,研究人员受到一致性模型(CM)启发,该模型简化了预训练的图像扩散模型以减少采样所需的步骤,并在条件图像生成上成功扩展了潜在一致性模型(LCM)。
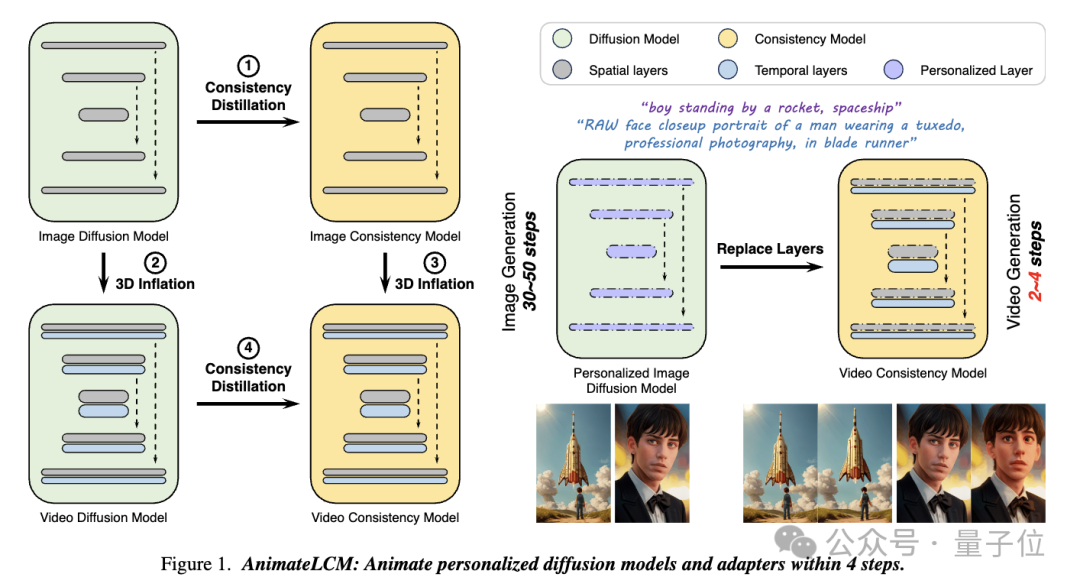 图片
图片
具体来说,研究人员提出了一种解耦的一致性学习(Decoupled Consistency Learning)策略。
首先在高质量的图像-文本数据集上蒸馏稳定扩散模型为图像一致性模型,然后在视频数据上进行一致性蒸馏以获得视频一致性模型。这种策略通过在空间和时间层面上分别训练,提高了训练效率。
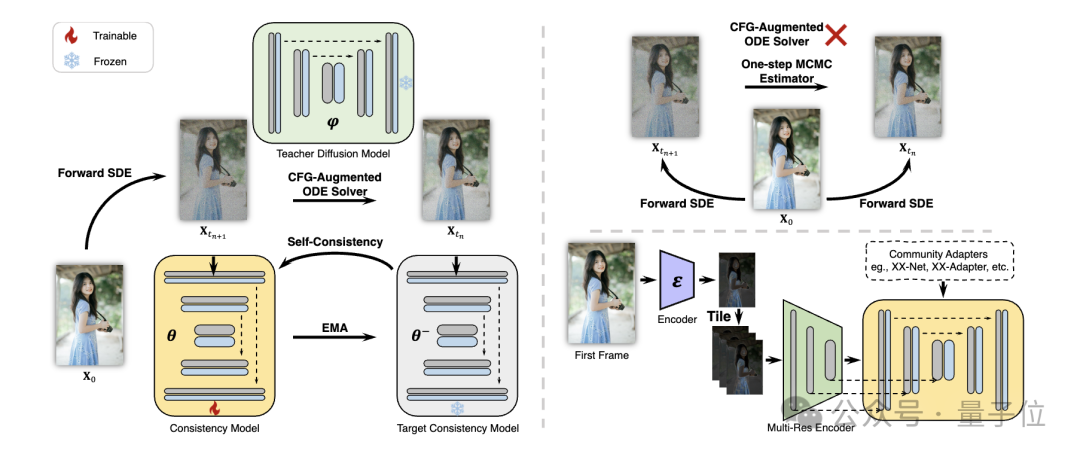 图片
图片
此外,为了能够在Stable Diffusion社区中实现即插即用适配器的各种功能(例如,用ControlNet实现可控生成),研究人员又提出了Teacher-Free自适应(Teacher-Free Adaptation)策略,使现有的控制适配器更符合一致性模型,实现更好的可控视频生成。
 图片
图片
定量和定性实验都证明了方法的有效性。
在UCF-101数据集上的零样本文本到视频生成任务中,AnimateLCM在FVD和CLIPSIM指标上均取得了最佳性能。
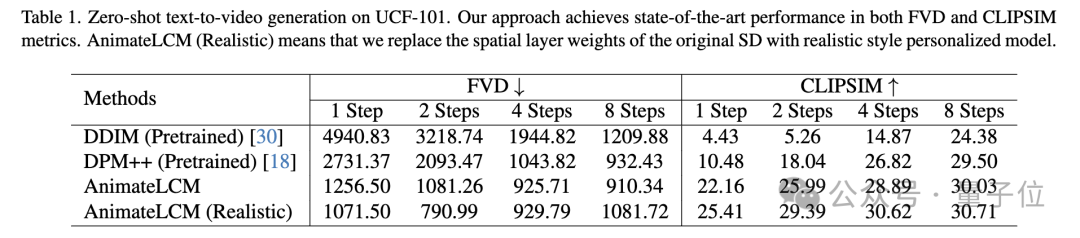 图片
图片
 图片
图片
消融研究验证了解耦一致性学习和特定初始化策略的有效:
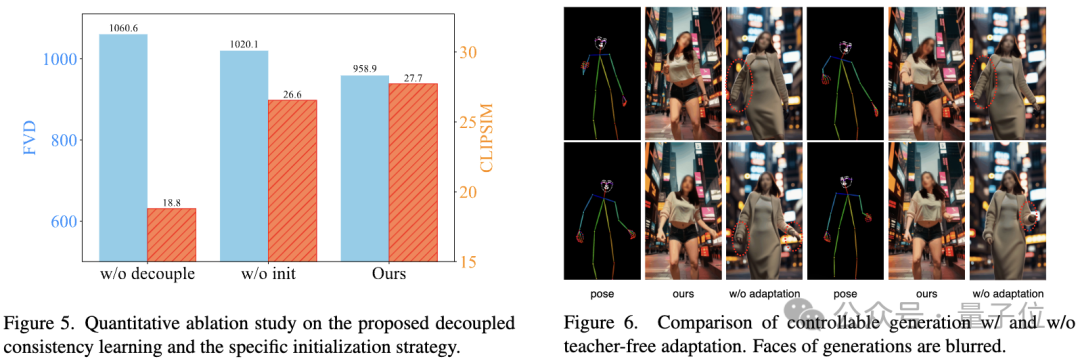 图片
图片
项目链接:
[1]https://animatelcm.github.io/
[2]https://huggingface.co/wangfuyun/AnimateLCM-SVD-xt
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 微软基于AI的新电子结构计算框架在Nature子刊发表
- 编辑|ScienceAI编者按:为了使电子结构方法突破当前广泛应用的密度泛函理论(KSDFT)所能求解的分子体系规模,微软研究院科学智能中心的研究员们基于人工智能技术和无轨道密度泛函理论(OFDFT)开发了一种新的电子结构计算框架M-OFDFT。这一框架不仅保持了与KSDFT相当的计算精度,而且在计算效率上实现了显著提升,并展现了优异的外推性能,为分子科学研究中诸多计算方法的基础——电子结构方法开辟了新的思路。相关研究成果已在国际知名学术期刊《自然-计算科学》(NatureComp
- 11分钟前 理论 0
-
 正版软件
正版软件
- 视频制作公司"生数科技"宣布完成新一轮数亿元融资,旨在继续发展其「清华系」特色
- 近日,北京生数科技有限公司(以下简称“生数科技”)宣布完成新一轮数亿元融资,由启明创投领投,达泰资本、鸿福厚德、智谱AI、老股东BV百度风投和卓源亚洲继续跟投。本轮融资将主要用于多模态基础大模型的迭代研发、应用产品创新及市场拓展。本轮由华兴资本担任独家财务顾问。生数科技成立于2023年3月,是全球领先的多模态大模型公司,致力于图像、3D、视频等原生多模态大模型的研发。生数科技核心团队来自清华大学人工智能研究院,此外还包括来自北京大学和阿里巴巴、腾讯、字节跳动等科技公司的多位技术人才
- 21分钟前 入门 0
-
 正版软件
正版软件
- 小米汽车即将发布!价格是最大关注点,雷军将有何动作?
- 雷军在宣布小米汽车SU7将于3月28日正式发布后,对当前新能源汽车市场的价格竞争发表了看法。小米已做好充分准备,决心在激烈的市场竞争中取得成功。这一行业热点引起了广泛关注,小米将积极应对市场挑战,力争在众多竞争对手中脱颖而出。雷军强调,价格战虽然是市场竞争的一部分,但产品品质和技术创新同样至关重要。小米将不仅仅关注价格竞争,更注重为消费者提供高品质、高性能的雷军强调,小米汽车的发展路径与小米手机有所不同,小米汽车将注重真正的智能科技,以满足大众对新能源车的期待。他表示,小米汽车已经做好了各方面的准备,包括
- 36分钟前 小米汽车 0
-
 正版软件
正版软件
- 微软官方公告:Windows操作系统支持卸载少用的软件
- 3月12日消息,微软近日在官方渠道悄然更新了卸载Windows系统自带软件OneDrive的方法,为用户提供了更多自主选择的权利。过去,Windows系统附带的诸多软件和功能,无论用户是否需要,都只能固定占据电脑C盘的空间,因为微软并未提供卸载或删除的选项。其中,微软推出的个人网盘OneDrive虽然具有一定的实用性,但大部分用户可能并未充分利用。现在,微软终于做出了让步,允许用户卸载OneDrive以释放系统资源。据微软官方介绍,用户只需在设置中打开“应用”选项,搜索“MicrosoftOneDrive
- 51分钟前 微软 0
-
 正版软件
正版软件
- "《三国志・战略版》制作人周炳枢将接任阿里游戏公司“灵犀互娱”CEO一职"
- 据游戏葡萄报道,阿里旗下游戏公司灵犀互娱的业务负责人詹钟晖(叮当)在一封内部邮件中宣布他和陈伟安将在财年末(3月31日)卸任。他还透露,岗位将由《三国志・战略版》制作人周炳枢(饼叔)接替。邮件内容未公开。各位灵犀小伙伴,灵犀互娱成立七年以来,凭借所有团队成员的共同努力和集团的全力支持,通过一系列优秀作品,在玩家心目中树立了相当的品牌影响力,在行业中也逐渐崭露头角。随着人才梯队日渐完善,灵犀的年轻人们成长迅速,已能担当带领灵犀继续发展的重任。到这个财年末,我和老陈、春娇将正式卸任大班委,交给炳枢带领的新班子
- 1小时前 15:35 游戏 阿里 灵犀互娱 0













