五种方法,详解NLP大模型在时间序列中的应用
 发布于2024-12-03 阅读(0)
发布于2024-12-03 阅读(0)
扫一扫,手机访问
最近,加利福尼亚大学发布了一篇综述文章,探讨了将自然语言处理领域的预训练大语言模型应用于时间序列预测的方法。该文章总结了5种不同的NLP大模型在时间序列领域的应用方式。接下来,我们将简要介绍这篇综述中提及的这5种方法。
 图片
图片
论文标题:Large Language Models for Time Series: A Survey
下载地址:https://arxiv.org/pdf/2402.01801.pdf
 图片
图片
1、基于Prompt的方法
通过直接利用prompt的方法,模型可以针对时间序列数据进行预测输出。之前的prompt方法中,基本思路是预训练一个prompt文本,将时间序列数据填充到其中,让模型生成预测结果。例如,在构造描述时间序列任务的文本时,填充时间序列数据,让模型直接输出预测结果。
 图片
图片
在处理时间序列时,数字经常被视为文本的一部分,数字的tokenize问题也备受关注。一些方法特别在数字之间加入空格,以便更清晰地区分数字,避免词典中对数字的不合理区分。
2、离散化
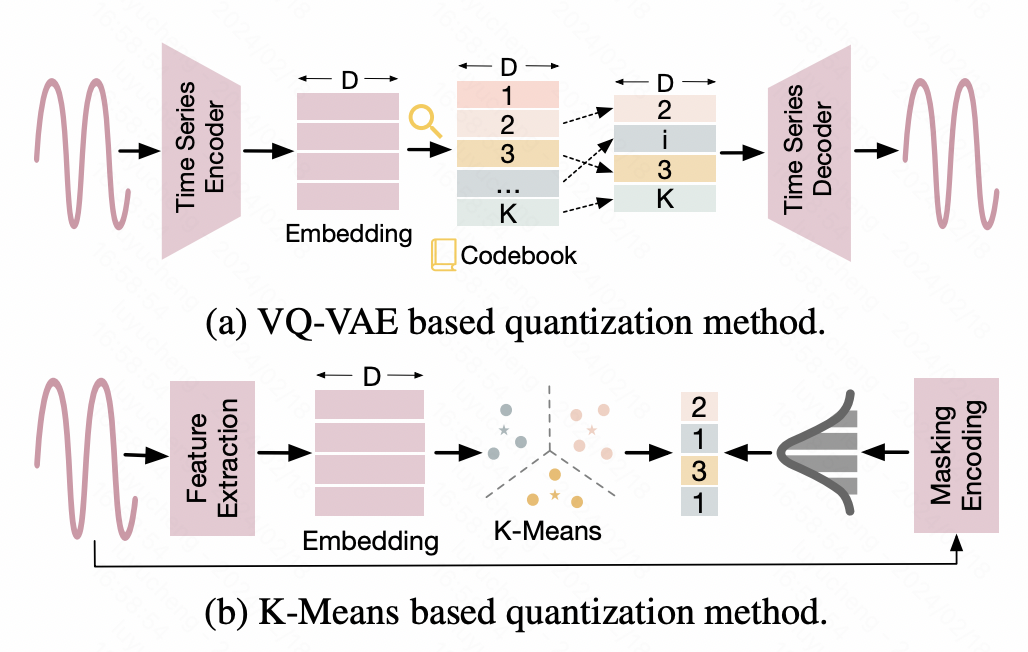
这类方法将时间序列进行离散化处理,将连续的数值转换为离散的id化结果,以适配NLP大模型的输入形式。例如,一种方法是借助Vector Quantized-Variational AutoEncoder(VQ-VAE)技术,将时间序列映射成离散的表征。VQ-VAE是一种VAE基础上的autoencoder结构,VAE通过Encoder将原始输入映射成表征向量,再通过Decoder还原原始数据。而VQ-VAE则保证了中间生成的表征向量是离散化的。根据这个离散化表征向量构造成一个词典,实现时间序列数据离散化的映射。另一种方法是基于K-means的离散化,利用Kmeans生成的质心将原始的时间序列离散化。另外再一些工作中,也将时间序列直接转换成文本,例如在一些金融场景中,将每天的涨价、降价等信息直接转换成相应的字母符号作为NLP大模型的输入。
 图片
图片
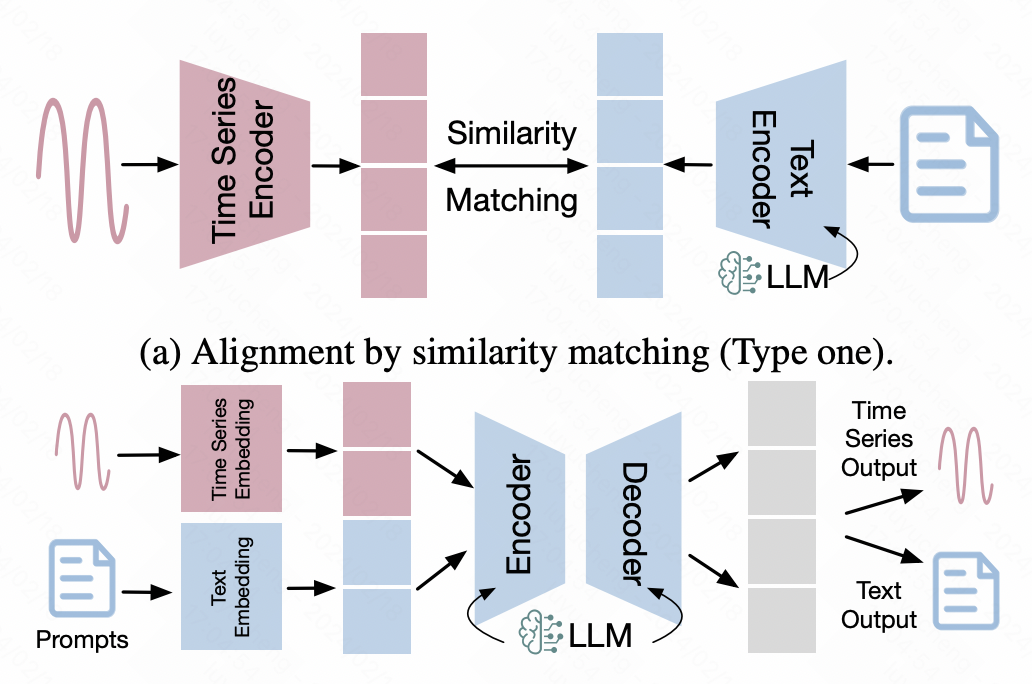
3、时间序列-文本对齐
这类方法借助到多模态领域的对齐技术,将时间序列的表征对齐到文本空间,以此实现时间序列数据直接输入到NLP大模型的目标。
在这类方法中,一些多模态对齐的方法被广泛应用其中。一种最典型的就是基于对比学习的多模态对齐,类似CLIP,使用时间序列编码器和大模型分别输入时间序列和文本的表示向量,然后使用对比学习拉近正样本对之间的距离,在隐空间对齐时间序列数据和文本数据的表征。
另一种方法是基于时间序列数据的finetune,以NLP大模型作为backbone,在此基础上引入额外的网络适配时间序列数据。这其中,LoRA等跨模态finetune的高效方法比较常见,冻结backbone的大部分参数,只对小部分参数进行finetune,或者引入少量的adaptor参数进行finetune,以达到多模态对齐的效果。
 图片
图片
4、引入视觉信息
这种方法比较少见,一般是将时间序列和视觉信息建立联系,再将利用图像和文本已经经过比较深入研究的多模态能力引入进来,为下游任务提取有效的特征。例如ImageBind中对6个模态的数据进行统一的对齐,其中就包括时间序列类型的数据,实现多模态的大模型统一。一些金融领域的模型,将股票的价格转换成图表数据,再配合CLIP进行图文对齐,生成图表相关的特征用于下游的时间序列任务。
5、大模型工具
这类方法不再对NLP大模型进行模型上的改进,或者改造时间序列数据形式进行大模型适配,而是直接将NLP大模型当成一个工具,解决时间序列问题。例如,让大模型生成解决时间序列预测的代码,应用到时间序列预测上;或者是让大模型调用开源的API解决时间序列问题。当然这类方式就比较偏向实际应用了。
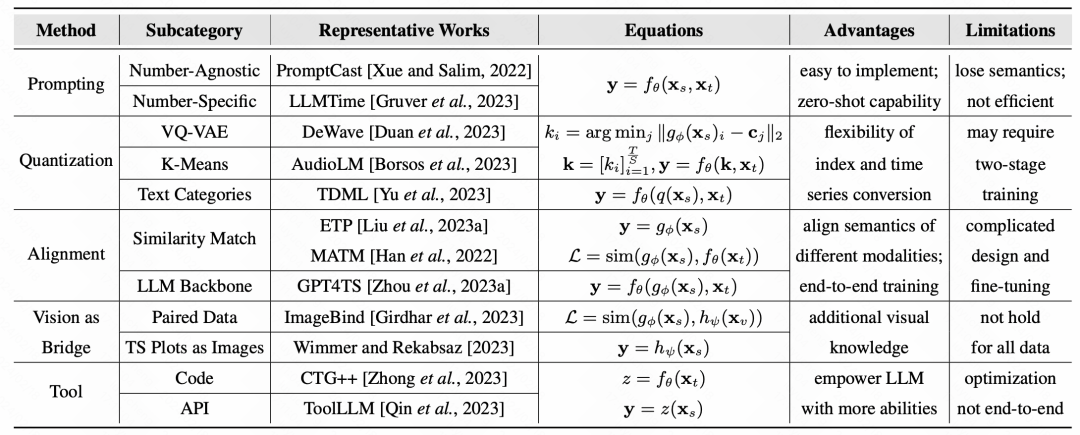
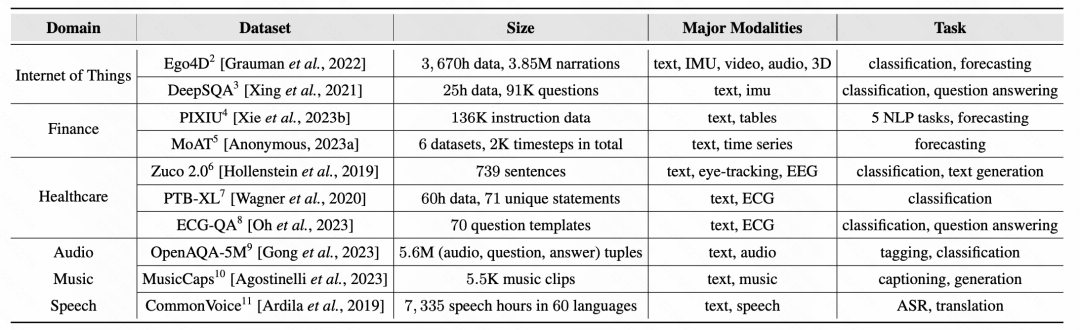
最后,文中总结了各类方法的代表工作以及代表数据集:
 图片
图片
 图片
图片
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 赛力斯牌新款AITO问界M7:插电式增程混动多用途车型
- 7月14日消息,华为旗下新款AITO问界M7已在中国工信部网站上曝光,并公布了一部分配置信息。这款车型的商标为赛力斯,由赛力斯汽车有限公司生产,是一款插电式增程混合动力多用途乘用车。新款AITO问界M7的尺寸为5020×1945×1760mm(长×宽×高),轴距为2820mm,整备质量为2460kg,总质量为2910kg,最高车速可达190km/h。华为常务董事、消费者业务BGCEO、智能汽车解决方案BUCEO余承东此前透露,新款AITO问界M7引入了HUAWEIADS2.0高阶智能驾驶系统,并新增了5座
- 6分钟前 0
-
 正版软件
正版软件
- 动感地平线:英菲尼迪发布全新品牌标识与三维特性
- 6月25日消息,随着电气化趋势的不断加强,许多汽车制造商决定通过更换品牌标识来突出对电气化的重视,并突显其品牌特色。继别克、大众、起亚等厂商之后,近日日本豪华品牌英菲尼迪也宣布升级其品牌标识,并推出全新的标志和三维标识。英菲尼迪的新品牌标识源自于两大设计理念,即"无限之路"和"地平线"。据英菲尼迪官方介绍,新标识首次采用了"动感地平线"的视觉设计,展示了英菲尼迪迈向新曙光的决心和无限创造力的信念。新标识底部的开口更宽,象征着更大的可能性。此外,原有标识内部的尖顶也经过改变,新版本的标志将两条平直的线延伸到
- 21分钟前 地平线 品牌标识 三维特性 0
-
 正版软件
正版软件
- 更好、更安全、更不依赖OpenAI,微软的AI新动向,推出大模型安全工具Azure AI
- 编译丨伊风出品|51CTO技术栈(微信号:blog51cto)生成性人工智能(generativeAI)的需求正不断增长,而对LLM安全和可靠性的担忧也变得比以往任何时候都更加突出。企业希望能确保为内外部使用而开发的大规模语言模型(LLM)能够提供高质量的输出,而不会偏离到未知领域。为了满足这一需求,有几个关键方面需要考虑。首先,应该加强对LLM模型的可解释性,使其能够透明地展示其生成结果的来源和逻辑推理过程。这将有助于用户理解输出的质量,并评估其可信度。其次,需要提供更多的工具和技术来验证和检测LLM输
- 36分钟前 模型 OpenAI API 0
-
 正版软件
正版软件
- vivo Y27 5G手机现身Google Play管理中心,或为Y36 5G的不同地区版本
- 5月31日消息,vivo在本月忙碌不已,相继在中国和国际市场推出了一系列新款智能手机。其中包括vivoS17系列、vivoY36、vivoY35m和vivoY78,同时还有vivoV29系列正在紧锣密鼓地筹备中。最新消息显示,vivoY275G手机已经在GooglePlay管理中心现身。据小编了解,vivoY275G手机的型号为V2248,与最近发布的vivoY365G型号相同,这暗示vivoY27可能只是该款手机在不同地区的另一个命名版本。vivoY275G手机将搭载联发科MT6833芯片,此前被称为天
- 51分钟前 vivo 0
-
 正版软件
正版软件
- 今日清明节:气清景明,万物皆显
- 本月4月4日消息,今天是我国二十四节气中的清明节。“清明”有冰雪消融,草木青青,天气清彻,万物欣欣向荣之意。清明时,气清景明,万物皆显,因此得名。清明,既是节气,又是节日。说到清明节,很多人会想起“清明时节雨纷纷,路上行人欲断魂”的名句。是的,清明一到,气温升高,雨量增多,正是春暖花开的大好时节。清明时节清明节又叫踏青节,是中国传统节日之一,也是最重要的祭祀节日之一,是祭祖和扫墓的日子。在传统社会中,清明节是一个特别盛大的节日,除了扫墓祭奠、怀念离世亲人,它还是踏青嬉游、亲近大自然的节日。4月5日9点12
- 1小时前 20:15 清明节 二十四节气 0













