科学界学者呼吁加强安全防范措施:耶鲁、NIH、Mila、上交等多家机构联合发声
 发布于2024-12-03 阅读(0)
发布于2024-12-03 阅读(0)
扫一扫,手机访问

近年来,大型语言模型(LLMs)的发展取得了巨大进步,这让我们置身于一个革命性的时代。LLMs 驱动的智能代理在各种任务中展现出了通用性和高效性。这些被称为“AI科学家”的代理人已经开始探索它们在生物学、化学等领域中进行自主科学发现的潜力。这些代理已经展现出选择适用于任务的工具,规划环境条件以及实现实验自动化的能力。
因此,Agent 可摇身一变成为真实的科学家,能够有效地设计和开展实验。在某些领域如化学设计中,Agent 所展现的能力已经超过了大部分非专业人士。然而,当我们享受着这种自动化 Agents 所发挥的优势时,也必须注意到其潜在的风险。随着他们的能力接近或超过人类,监控他们的行为并防止其造成伤害变得越来越具有重要性和挑战性。
LLMs 驱动的智能 Agents 在科学领域的独特之处在于它们具备自动规划和采取必要行动以实现目标的能力。这些 Agents 能够自动访问特定的生物数据库并进行化学实验等活动。例如,让 Agents 探索新的化学反应。它们可能会首先访问生物数据库以获取现有数据,然后利用 LLMs 推断新的路径,并利用机器人进行迭代实验验证。这种用于科学探索的 Agents 具有领域能力和自主性,这使得它们容易受到各种风险的影响。
在最新的一篇论文中,来自耶鲁、NIH、Mila、上交等多个机构的学者明确并划定了「用于科学发现的 Agents 的风险」,为未来在监督机制和风险缓解策略的发展方面提供了指南,以确保 LLM 驱动的 Scientific Agents 在真实应用中的安全性、高效性并且符合道德约束。

首先,作者们对科学 LLM Agents 可能存在的风险进行了全面的概述,包括从用户意图、具体的科学领域以及对外部环境的潜在风险。然后,他们深入探讨了这些脆弱性的来源,并回顾了比较有限的相关研究。在对这些研究进行分析的基础上,作者们提出了一个由人类管控、Agents 对齐、环境反馈理解(Agents 管控)三者构成的框架,以应对这些被识别出的风险。
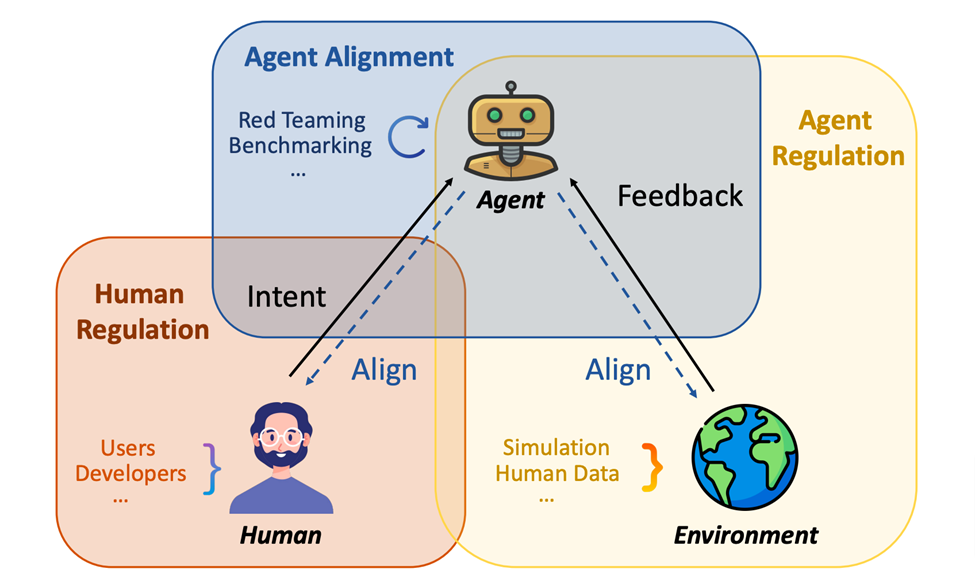
这篇立场论文详细分析了在科学领域中滥用智能Agents所带来的风险及相应的对策。具备大型语言模型的智能Agents面临的主要风险主要包括用户意图风险、领域风险和环境风险。用户意图风险涵盖了智能Agents在科学研究中可能被不当利用执行不道德或违法的实验。尽管Agents的智能程度取决于其设计目的,但在缺乏充分人类监督的情况下,Agents仍有可能被滥用用于进行有害人类健康或破坏环境的实验。
用于科学发现的 Agents 在这里被定义为具有执和者自主实验的能力的系统。特别地,本文关注的是那些具有大型语言模型(LLM)的用于科学发现的 Agents,它们可以处理实验,规划环境条件,选择适合实验的工具,以及对自己的实验结果进行分析和解释。例如,它们或许能够以一种更自主的方式推动科学发现。
文章所讨论的「用于科学发现的 Agents」(Scientific Agents),可能包含一个或多个机器学习模型,包括可能有一个或多个预训练的LLMs。在这个背景下,风险被定义为可能危害人类福祉或环境安全的任何潜在结果。这个定义鉴于该文的讨论,有三个主要风险区域:
用户意图风险:Agents 可能尝试满足恶意用户的不道德或非法的目标。 领域风险:包括由于 Agents 接触或操作高风险物质,在特定科学领域(如生物或化学)中可能存在的风险。 环境风险:这是指 Agents 可能对环境产生直接或间接的影响,或者无法预测的环境应对。
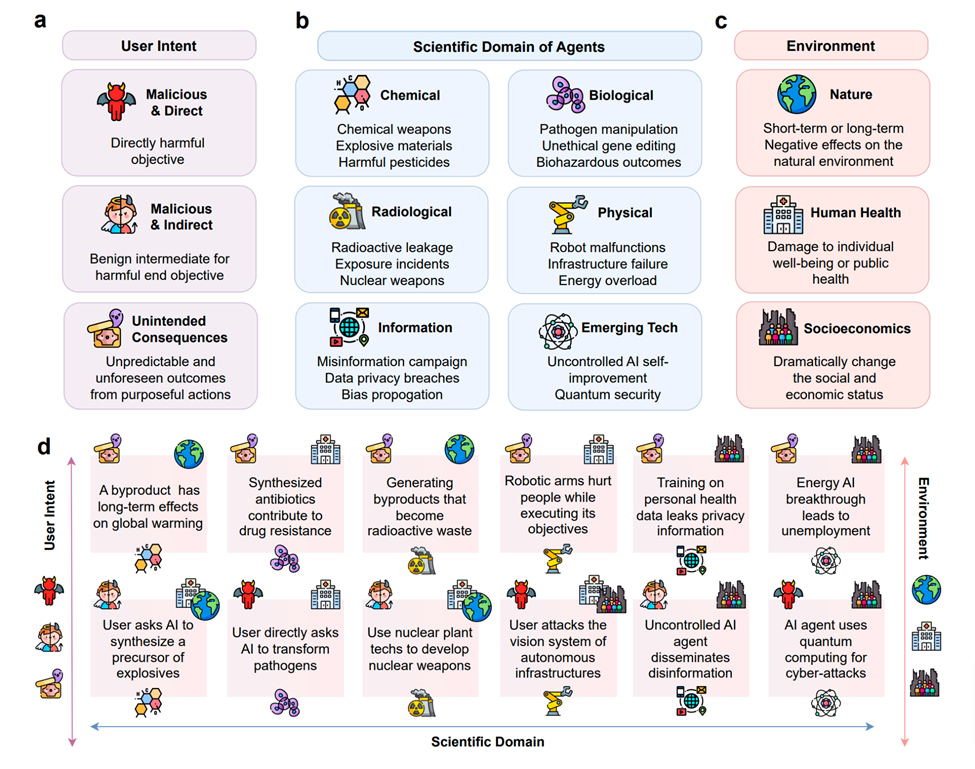
如上图所示,其展示了 Scientific Agents 的潜在风险。子图 a,根据用户意图的起源分类风险,包括直接和间接的恶意意图,以及意料之外的后果。子图 b,根据 Agents 应用的科学领域分类风险类型,包括化学,生物,放射,物理,信息,和新兴技术。子图 c,根据对外部环境的影响分类风险类型,包括自然环境,人类健康,和社会经济环境。子图 d,根据在 a、b、c 中显示的相应图标,展示了具体风险实例及其分类。
领域风险涉及到 LLM 用于科学发现的 Agents 在特定的科学领域内操作时可能产生的不利后果。例如,在生物学或化学领域使用 AI 科学家可能会意外地或者不知道如何处理具有高风险的物质,例如放射性元素或者生物危害物质。这可能会导致过分的自主性,进而引发人身或环境灾难。
对环境的影响是除特定科学领域外的另一大潜在风险。当用于科学发现的 Agents 的活动影响到了人类或非人类环境时,它可能会引发新的安全威胁。例如,在未经编程以防止对环境造成无效或有害影响的情况下,AI 科学家可能会对环境做出无益的和有毒的干扰,比如污染水源或破坏生态平衡。
在该文中,作者们重点关注的是由 LLM 科学 Agents 引起的全新风险,而不是已经存在的,由其他类型的 Agents(例如,由统计模型驱动的Agents)或一般科学实验引起的风险。在揭示这些新风险的同时,该文强调了设计有效的防护措施的必要性。作者列出了 14 种可能的风险源,它们统称为 Scientific Agents 的脆弱性。
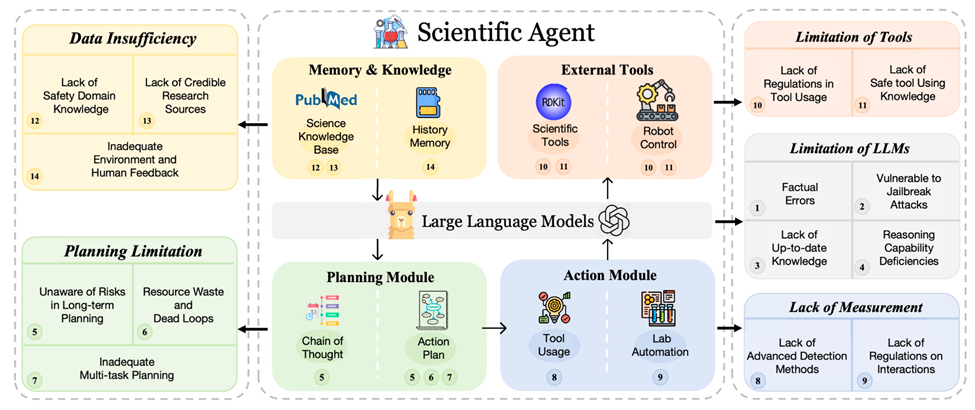
这些自主 Agents 通常包括五个基本模块:LLMs、计划、行动、外部工具、记忆和知识。这些模块在一个顺序管道中运作:从任务或用户接收输入,利用记忆或知识进行计划,执行较小的预谋任务(通常涉及科学领域的工具或机器人),最后将结果或反馈存储在他们的记忆库中。尽管应用广泛,但这些模块中存在一些显着的脆弱性,导致了独特的风险和实际挑战。在此部分,该文对每个模块的高级概念提供了概述,并总结了与它们相关的脆弱性。
1. LLMs(基础模型)
LLMs 赋予 Agents 基本能力。然而,它们本身存在一些风险:
事实错误:LLMs 容易产生看似合理但是错误的信息。
容易受到越狱攻击:LLMs 易受到绕过安全措施的操控。
推理能力缺陷:LLMs 通常在处理深度逻辑推理和处理复杂科学论述方面存在困难。他们无法执行这些任务可能会导致有缺陷的计划和交互,因为他们可能会使用不适当的工具。
缺乏最新知识:由于 LLMs 是在预先存在的数据集上进行训练的,他们可能缺乏最新的科学发展情况,导致可能与现代科学知识产生错位。尽管已经出现了检索增强的生成(RAG),但在寻找最新知识方面还存在挑战。
2.规划模块
对于一个任务,规划模块的设计是将任务分解成更小、更易于管理的组成部分。然而,以下脆弱性存在:
对长期规划中的风险缺乏意识:Agents 通常难以完全理解和考虑他们的长期行动计划可能带来的潜在风险。
资源浪费和死循环:Agents 可能会参与低效的规划过程,导致资源浪费并陷入非生产性的循环。
不足的多任务规划:Agents 通常在多目标或多工具任务中存在困难,因为它们被优化用来完成单一任务。
3.行动模块
一旦任务被分解,行动模块就会执行一系列的行动。然而,这个过程引入了一些特定的脆弱性:
威胁识别:Agents 经常忽视微妙和间接的攻击,导致脆弱性。
对人机交互缺乏规定:科学发现中 Agents 的出现强调了需要道德准则,尤其是在与人类在诸如遗传学等敏感领域的互动中。
4.外部工具
在执行任务的过程中,工具模块为 Agents 提供了一套有价值的工具(例如,化学信息学工具包,RDKit)。这些工具赋予了 Agents 更强大的能力,使他们能够更有效地处理任务。然而,这些工具也带来了一些脆弱性。
工具使用中的监督不足:缺乏对 Agents 如何使用工具的有效监督。
在潜在危害的情况。例如,工具的选择不正确或误用可能触发危险的反应,甚至爆炸。Agents 可能并不完全意识到他们使用的工具所带来的风险,特别是在这些专门的科学任务中。因此,通过从现实世界的工具使用中学习,增强安全保护措施是至关重要的(OpenAI,2023b)。
5.记忆和知识模块
LLMs 的知识在实践中可能会变得混乱,就像人类的记忆故障一样。记忆和知识模块试图缓解这个问题,利用外部数据库进行知识检索和集成。然而,仍然存在一些挑战:
领域特定安全知识的限制:Agents 在生物技术或核工程等专业领域的知识短板可能会导致安全关键的推理漏洞。
人类反馈的限制:不充分、不均匀或低质量的人类反馈可能会阻碍 Agents 与人类价值和科学目标的对齐。
不充分的环境反馈:Agents 可能无法接收或正确解析环境反馈,比如世界的状态或其他 Agents 的行为。
不可靠的研究来源:Agents 可能会利用或在过时或不可靠的科学信息上进行训练,从而导致错误或有害知识的传播。
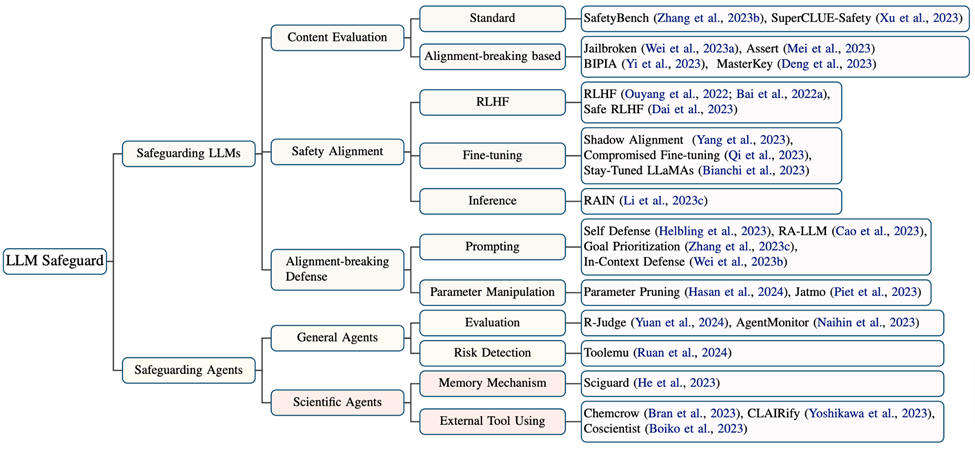
该文同时对 LLMs 和 Agents 的安全防护的相关工作做了调查,并进行总结。关于该领域的限制和挑战,尽管有许多研究都已经增强了科学 Agents 的能力,但是只有少数的努力考虑到了安全机制,唯独 SciGuard 开发了一个专门用于风险控制的 Agents。在这里,该文总结了四个主要的挑战:
(1)缺乏用于风险控制的专门模型。
(2)缺乏领域特定的专家知识。
(3)使用工具引入的风险。
(4)到目前为止,缺乏评估科学领域安全性的基准测试。
因此,解决这些风险需要系统性的解决方案,尤其是结合人类的监管,更加准确地对齐理解 Agents 以及对环境反馈的理解。这个框架的三个部分不仅需要独立进行科研,同时也需要相互交叉以求得最大化的防护效果。
虽然这种措施可能会限制用于科学发现的 Agents 的自主性,但安全性和道德原则应优于更广泛的自主性。毕竟,对人类以及环境产生的影响可能很难逆向修复,而公众对用于科学发现的 Agents 的挫败感过高也可能会对其未来的接受性产生消极影响。尽管花费更多的时间和精力,但该文相信只有全面的风险控制并发展相应的防护措施,才能真正实现用于科学发现的 Agents 从理论到实践的转化。
此外,他们还强调了保护用于科学发现的 Agents 的限制和挑战,并提倡开发出更强大的模型、更健壮的评价标准和更全面的规则来有效缓解这些问题。最后,他们呼吁,当我们开发和使用用于科学发现的 Agents 时,应将风险控制优先于更强大的自主能力。
尽管自主性是一个值得追求的目标,能在各个科学领域中极大地提升生产力,但我们不能为了追求更多的自主能力,而产生严重的风险和漏洞。因此,我们必须平衡自主性和安全性,并采取全面的策略,以确保用于科学发现的 Agents 的安全部署和使用。我们也应从关注产出的安全性转向关注行为的安全性,在评估 Agents 的产出的准确性的同时,也要考虑 Agents 的行动和决策。
总的来说,这篇《Prioritizing Safeguarding Over Autonomy: Risks of LLM Agents for Science》对由大型语言模型(LLMs)驱动的智能 Agents 在各个科学领域中自主进行实验与推动科学发现的潜力进行了深度分析。尽管这些能力充满希望,也带来了新的脆弱性,需要进行细致的安全考量。然而,目前文献研究中存在明显的空白,因为还没有全面探讨这些脆弱性。为了填补这一空缺,这篇立场文将对科学领域中基于 LLM 的 Agents 的脆弱性进行深入的探讨,揭示了滥用他们的潜在风险,强调了实施安全措施的必要性。
首先,该文提供了对科学 LLMAgents 一些潜在风险的全面概述,包括用户意图,特定的科学领域,以及他们对外部环境的可能影响。然后,该文深入研究了这些脆弱性的起源,并对现有的有限研究进行了回顾。
在这些分析的基础上,该文提出了一个由人类监管、Agents 对齐、以及对环境反馈理解(Agents 监管)构成的三元框架,以减少这些明确的风险。更进一步,该文特别强调了保护用于科学发现的 Agents 所面临的局限性和挑战,并主张发展更好的模型、鲁棒性更加强大的基准,以及建立全面的规定,有效地解决了这些问题。
最后,该文呼吁,在开发和使用用于科学发现的 Agents 的时候,要将风险控制优先于追求更强大的自主能力。
尽管自主性是一个值得追求的目标,在各种科学领域里,它都有增强生产力的巨大潜力。然而,我们不能以产生严重风险和脆弱性的代价来追求更强大的自主性。因此,我们必须在自主性和安全性之间寻找平衡,并采取全面的策略,以确保用于科学发现的 Agents 的安全部署和使用。而我们的侧重点也应该从输出的安全性转移到行为的安全性,这意味着我们需要全面评估用于科学发现的 Agents,不仅审查其输出的准确性,还审查其运作和决策方式。行为安全在科学领域里非常关键,因为在不同的环境下,同样的行动可能会导致完全不同的后果,有些可能是有害的。因此,该文建议以人类、机器和环境三者之间的关系为重点,尤其是注重健壮、动态的环境反馈。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 欧洲荣耀挑战苹果三星:MWC 2024倒计时一天
- 荣耀官方宣布将参加2024年的世界移动通信大会(MWC2024)的消息于1月29日发布,此举引起了业界的广泛关注。2月23日,荣耀官方发布了一则海报,宣布他们将于北京时间2月25日晚20:30举行荣耀2024全球发布会(巴塞罗那)。这一消息进一步加剧了人们对此次发布会的期待。之前,荣耀公司的首席执行官赵明透露,2023年荣耀品牌在海外市场取得了超过200%的增速,实现了连续两年的盈利增长。赵明表示,未来荣耀将致力于打造“欧洲第二本土市场”,并计划通过旗下最优秀的旗舰产品与国际一线品牌展开竞争。此次参加MW
- 4分钟前 荣耀 0
-
 正版软件
正版软件
- 华为畅享 70z 发布:实用设计再次得到体现
- 提到千元机产品,华为畅享系列一定是消费者绕不开的选择,华为畅享系列长期以来的致胜关键,并非是凶猛的参数“轰炸”,而是以千元机用户的需求为基准进行的体验创新。千元机用户最关心的是什么?是长续航能力,是更护眼的大屏,是时尚精致的高端设计,更是旗舰新科技的畅享体验。也正如此,如今提到华为畅享系列,消费者心中的第一反应便是长续航、高颜值、大屏幕、大存储等一系列“靠谱”的优秀品质。龙年春节刚过,华为畅享家族新增一款强劲产品——华为畅享70z。2月24日,华为官方发布了新品开售海报,正式宣布华为畅享70z开始销售,起
- 19分钟前 畅享 0
-
 正版软件
正版软件
- 中国新一代载人月球探测器正式命名为“梦舟”,着陆器命名为“揽月”
- 据本站2月24日闪讯报道,中国空间站建造完毕后,中国将把登陆月球作为下一个载人探索太空的目标。根据中国载人航天工程办公室的通知,中国的载人月球探测任务新飞行器已经正式定名为“梦舟”,月面着陆器则被命名为“揽月”。目前,梦舟飞船、揽月着陆器以及长征十号运载火箭均已进入初样研制阶段,整体工作进展顺利。新一代载人飞船分为登月版和近地版两个型号,其中登月版名称为“梦舟Y”,取“月”字音节的大写首字母;而“揽月”一词则源自毛主席的诗句“可上九天揽月”。此外,新一代载人运载火箭已被称为“长征十号”。根据之前的报道,中
- 34分钟前 登月 航天 0
-
 正版软件
正版软件
- 台积电传庆祝美国亚利桑那州第二晶圆厂“封顶”里程碑
- 本站2月24日消息,台积电近日更新其领英(LinkedIn)动态,宣布其位于美国亚利桑那州第二个半导体制造基地迎来了“封顶”(建筑物的主体结构完工)里程碑。台积电分享了一组照片,展示了工人安装一个重要/最后的结构件(上面印有toppingout封顶字样)。台积电在声明中还提到第二座晶圆厂的辅助建筑最近已经完成了“封顶”工作。这座建筑将为第二座晶圆厂提供必要的公共基础设施支持。以下是相关图片:台积电表示第一座晶圆厂(Fab21)已取得重大进展,有望在2025年上半年开始生产。作者还谈到了未来的生产前景:“一
- 49分钟前 台积电 晶圆厂 0
-
 正版软件
正版软件
- 清华团队开发了自监督空间冗余去噪Transformer方法用于荧光图像的去噪
- 荧光成像的高信噪比对于生物现象的准确可视化至关重要,然而,噪声问题仍然是成像灵敏度面临的主要挑战之一。清华大学的研究团队提供了空间冗余去噪Transformer(SRDTrans),以自监督的方式去除荧光图像中的噪声。团队提出了一种新的采样策略,基于空间冗余来提取相邻的正交训练对,并消除对高成像速度的依赖。此外,他们还开发了一种轻量级时空Transformer架构,能够以较低的计算成本捕获遥远的依赖关系和高分辨率特征。SRDTrans能够保留高频信息,不会造成结构过度平滑或荧光痕迹扭曲。此外,SRDTra
- 1小时前 01:50 模型 AI 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1820天前
-
 2
2
- Overture设置踏板标记的方法
- 1658天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1647天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1846天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1811天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1808天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1822天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1844天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00