揭示Sora同类架构细节的Stable Diffusion 3技术报告发布
 发布于2024-12-13 阅读(0)
发布于2024-12-13 阅读(0)
扫一扫,手机访问
很快啊,“文生图新王”Stable Diffusion 3的技术报告,这就来了。
全文一共28页,诚意满满。

“老规矩”,宣传海报(⬇️)直接用模型生成,再秀一把文字渲染能力:
所以,SD3这比DALL·E 3和Midjourney v6都要强的文字以及指令跟随技能,究竟怎么点亮的?
技术报告揭露:
全靠多模态扩散Transformer架构MMDiT。
通过对图像和文本表示分别应用不同组权重的方法,实现了比之前版本更强大的性能提升,这是成功的关键。
具体几何,我们翻开报告来看。
微调DiT,提升文本渲染能力
在发布SD3之初,官方就已经透露它的架构和Sora同源,属于扩散型Transformer——DiT。
现在答案揭晓:
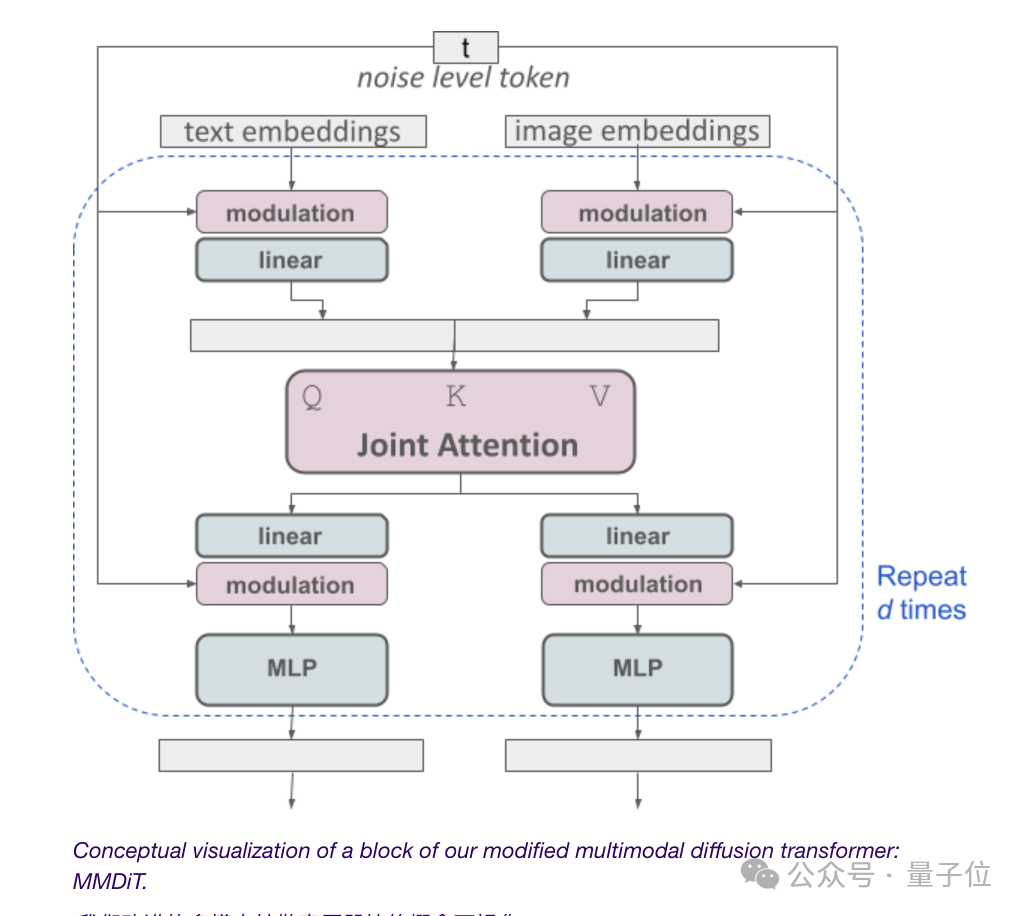
由于文生图模型需要考虑文本和图像两种模式,Stability AI比DiT更近一步,提出了新架构MMDiT。
这里的“MM”就是指“multimodal”。
和Stable Diffusion此前的版本一样,官方用两个预训练模型来获得合适和文本和图像表示。
其中文本表示的编码用三种不同的文本嵌入器(embedders)来搞定,包括两个CLIP模型和一个T5模型。
图像token的编码则用一个改进的自动编码器模型来完成。
由于文本和图像的embedding在概念上完全不是一个东西,因此,SD3对这两种模式使用了两组独立的权重。
(有网友吐槽:这个架构图好像要启动“人类补完计划”啊,嗯是的,有人就是“看到了《新世纪福音战士》的资料才点进来这篇报告的”)
言归正传,如上图所示,这相当于每种模态都有两个独立的transformer,但是会将它们的序列连接起来进行注意力操作。
这样,两种表示都可以在自己的空间中工作,同时还能考虑到另一种。
最终,通过这种方法,信息就可以在图像和文本token之间“流动”,在输出时提高模型的整体理解能力和文字渲染能力。
并且正如之前的效果展示,这种架构还可以轻松扩展到视频等多种模式。

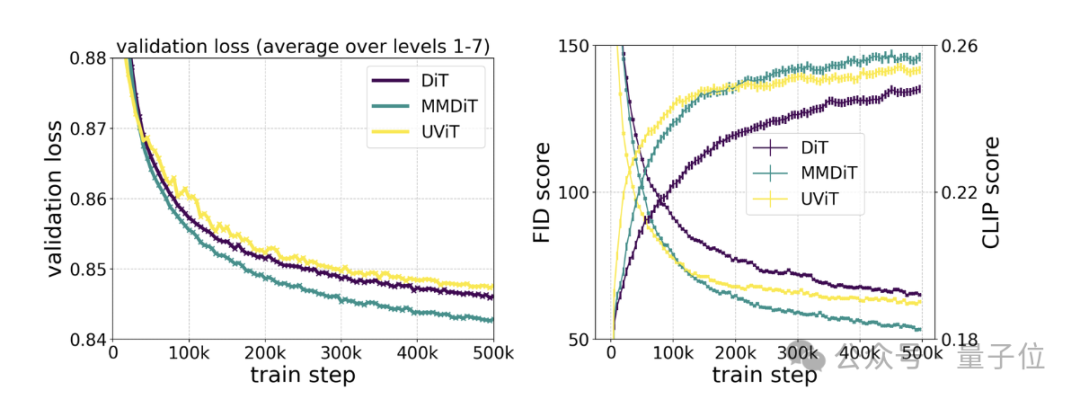
具体测试则显示,MMDiT出于DiT却胜于DiT:
它在训练过程中的视觉保真度和文本对齐度都优于现有的文本到图像backbone,比如UViT、DiT。
重新加权流技术,不断提升性能
在发布之初,除了扩散型Transformer架构,官方还透露SD3结合了flow matching。
什么“流”?
如今天发布的论文标题所揭露,SD3采用的正是“Rectified Flow”(RF)。

这是一个“极度简化、一步生成”的扩散模型生成新方法,入选了ICLR2023。
它可以使模型的数据和噪声在训练期间以线性轨迹进行连接,产生更“直”的推理路径,从而可以使用更少的步骤进行采样。
基于RF,SD3在训练过程中引入了一张全新的轨迹采样。
它主打给轨迹的中间部分更多权重,因为作者假设这些部分会完成更具挑战性的预测任务。
通过多个数据集、指标和采样器配置,与其他60个扩散轨迹方法(比如LDM、EDM和ADM)测试这一生成方法发现:
虽然以前的RF方法在少步采样方案中表现出不错的性能,但它们的相对性能随着步数的增加而下降。
相比之下,SD3重新加权的RF变体可以不断提高性能。
模型能力还可进一步提高
官方使用重新加权的RF方法和MMDiT架构对文本到图像的生成进行了规模化研究(scaling study)。
训练的模型范围从15个具有4.5亿参数的模块到38个具有80亿参数的模块。
从中他们观察到:随着模型大小和训练步骤的增加,验证损失呈现出平滑的下降趋势,即模型通过不断学习适应了更为复杂的数据。
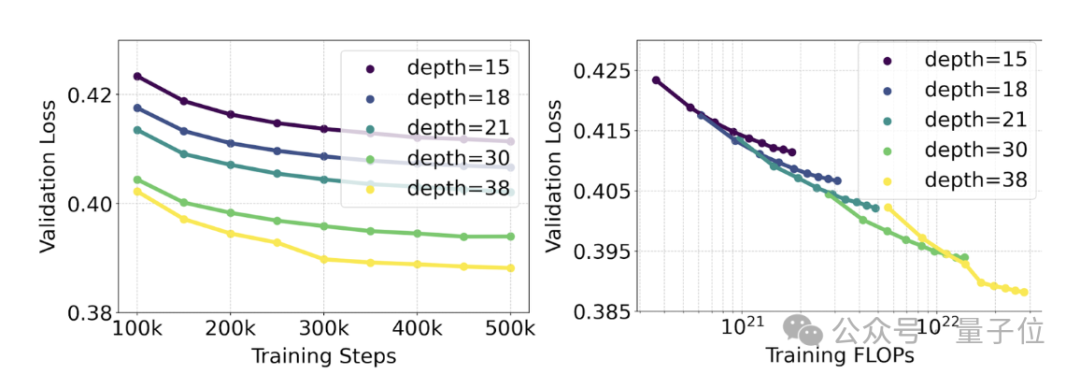
为了测试这是否在模型输出上转化为更有意义的改进,官方还评估了自动图像对齐指标(GenEval)以及人类偏好评分(ELO)。
结果是:
两者有很强的相关性。即验证损失可以作为一个很有力的指标,预测整体模型表现。
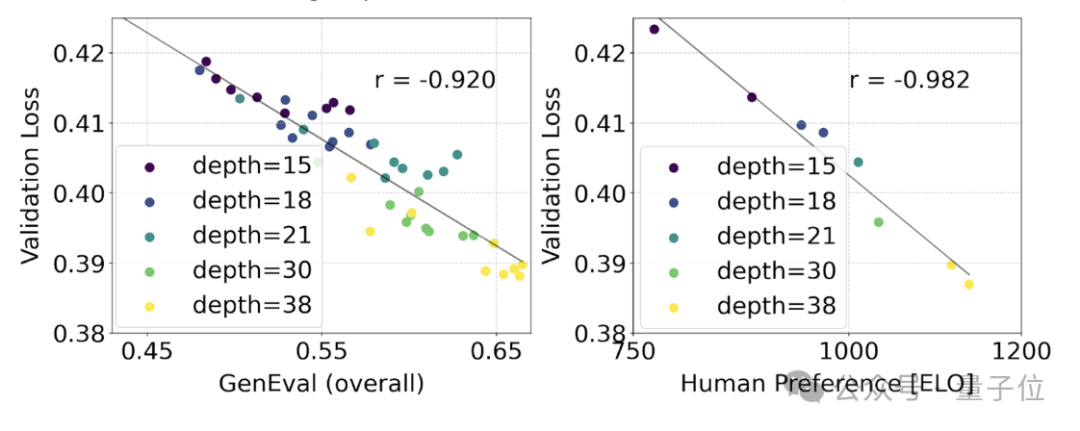
此外,由于这里的扩展趋势没有出现饱和迹象(即即随着模型规模的增加,性能仍在提升,没有达到极限),官方很乐观地表示:
未来的SD3性能还能继续提高。
最后,技术报告还提到了文本编码器的问题:
通过移除用于推理的47亿参数、内存密集型T5文本编码器,SD3的内存需求可以显著降低,但同时,性能损失很小(win rate从50%降到46%)。
不过,为了文字渲染能力,官方还是建议不要去掉T5,因为没有它,文本表示的win rate将跌至38%。

那么总结一下就是说:SD3的3个文本编码器中,T5在生成带文本图像(以及高度详细的场景描述图)时贡献是最大的。
网友:开源承诺如期兑现,感恩
SD3报告一出,不少网友就表示:
Stability AI对开源的承诺如期而至很是欣慰,希望他们能够继续保持并长久运营下去。

还有人就差报OpenAI大名了:

更加值得欣慰的是,有人在评论区提到:
SD3模型的权重全部都可以下载,目前规划的是8亿参数、20亿参数和80亿参数。


速度怎么样?
咳咳,技术报告有提:
80亿的SD3在24GB的RTX 4090上需要34s才能生成1024*1024的图像(采样步骤50个)——不过这只是早期未经优化的初步推理测试结果。
报告全文:https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf 。
参考链接:
[1]https://stability.ai/news/stable-diffusion-3-research-paper。
[2]https://news.ycombinator.com/item?id=39599958。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 九号公司推出 F2 升级版电动滑板车:25km 续航,2599 元
- 本站4月19日消息,九号电动滑板车F2升级版现已上架并开启预售,首发价2599元,号称同价618。这款电动滑板车采用了LED实时显示屏,10英寸轮胎、高强性车架,承重200斤,电池寿命达到3000小时,续航可达20~25km,时速最高25km/h,号称5年后性能不低于新车的70%。除此外,它还采用了双轮制动(电子刹+碟刹),0.1秒响应,胎面具备破水防滑纹,保证潮湿路面不打滑。本站附参数如下:京东九号(Ninebot)电动滑板车F2F25F302599元领100元券
- 8分钟前 电动滑板车 0
-
 正版软件
正版软件
- enj币怎么样
- ENJ币是一种用于游戏领域的区块链加密货币,旨在提供游戏内资产的所有权、流动性、互操作性和稀缺性。它用于游戏内购买、资产交易、游戏奖励和创建游戏物品,并有望随着区块链游戏的发展而持续发挥重要作用。
- 13分钟前 0
-
 正版软件
正版软件
- upbit交易所在中国如何注册登录
- 在Upbit註冊並登錄:造訪Upbit官網www.upbit.com。按「註冊」按鈕(位於右上角)。填寫註冊表,並驗證電子郵件信箱。設定兩步驟驗證(2FA)。按「登錄」按鈕(位於右上角)。輸入註冊時使用的信箱和密碼。完成兩步驟驗證(2FA)。登錄成功,即會被導向Upbit儀表板。請注意,Upbit不在中國營運,因此中國用戶無法註冊或登錄。
- 28分钟前 0
-
 正版软件
正版软件
- 门罗币是什么?门罗币的工作原理是什么?
- 门罗币是一种注重隐私的加密货币,旨在提供匿名和不可追踪的交易,通过环签名、零知识证明和隐形地址等加密技术增强隐私性。其优势包括匿名性、不可追踪性和可扩展性,但它也面临监管疑虑、可用性受限和可追溯性的潜在挑战。门罗币适用于重视隐私的应用场景,包括匿名支付、数据保护,但也可能用于非法活动。门罗币:注重隐私的加密货币门罗币是一种注重隐私的加密货币,旨在提供匿名和不可追踪的交易。它使用环签名和零知识证明等加密技术来掩盖交易的来源和目的地。工作原理门罗币基于区块链技术,但采用了以下独特功能来增强隐私:环签名:环签名
- 43分钟前 0
-
 正版软件
正版软件
- 加密货币交易所排行榜前十名有哪些
- 加密货币交易所排行榜前十名根据CoinMarketCap在2023年2月的数据,加密货币交易所的排名如下:**排名名称**1Binance2Coinbase3FTX4Kraken5HuobiGlobal6OKX7Bybit8Gate.io9KuCoin10Crypto.com1.BinanceBinance是全球最大的加密货币交易所,拥有广泛的数字资产和交易对。它以快速、安全和低交易费用而闻名。2.CoinbaseCoinbase是美国最受欢迎的加密货币交易所。它提供易于使用的用户界面、广泛的资产选择和高
- 58分钟前 0













