低比特量化的大型语言模型权重和激活功能已实现商用APP集成 - ICLR 2024 Spotlight
 发布于2024-12-13 阅读(0)
发布于2024-12-13 阅读(0)
扫一扫,手机访问
模型量化是模型压缩与加速中的一项关键技术,其将模型权重与激活值量化至低 bit,以允许模型占用更少的内存开销并加快推理速度。对于具有海量参数的大语言模型而言,模型量化显得更加重要。例如,GPT-3 模型的 175B 参数当使用 FP16 格式加载时,需消耗 350GB 的内存,需要至少 5 张 80GB 的 A100 GPU。
但若是可以将 GPT-3 模型的权重压缩至 3bit,则可以实现单张 A100-80GB 完成所有模型权重的加载。
目前,现有的大型语言模型后训练量化算法存在一个明显的挑战,即依赖手动设定量化参数,缺乏相应的优化过程。这导致在进行低比特量化时,现有方法往往会出现性能下降的情况。虽然量化感知训练在确定最佳量化配置方面具有一定效果,但它却需要额外的训练成本和数据支持。特别是在大型语言模型中,计算量本身就已经很大,这使得量化感知训练在大规模语言模型量化方面的应用变得更加困难。
这引出一个问题:我们能否在保持后训练量化的时间和数据效率的同时,达到量化感知训练的性能?
为了应对大语言模型后训练期间的量化参数优化难题,一群研究人员来自上海人工智能实验室、香港大学和香港中文大学提出了《OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models》。这项算法不仅支持大型语言模型中权重和激活值的量化,还能适应各种不同的量化比特位设置。

arXiv 论文地址:https://arxiv.org/abs/2308.13137
OpenReview 论文地址:https://openreview.net/forum?id=8Wuvhh0LYW
代码地址:https://github.com/OpenGVLab/OmniQuant
框架方法

如上图所示,OmniQuant 是一种针对大语言模型(LLM)的可微分量化技术,同时支持仅权重量化和权重激活值同时量化。并且,其在实现高性能量化模型的同时,保持了后训练量化的训练时间高效性和数据高效性。例如,OmniQuant 可在单卡 A100-40GB 上,在 1-16 小时内完成对 LLaMA-7B ~ LLaMA70B 模型量化参数的更新。
为了达到这个目标,OmniQuant 采用了一个 Block-wise 量化误差最小化框架。同时,OmniQuant 设计了两种新颖的策略来增加可学习的量化参数,包括可学习的权重裁剪(Learnable Weight Clipping,LWC),以减轻量化权重的难度,以及一个可学习的等价转换(Learnable Equivalent Transformation, LET),进一步将量化的挑战从激活值转移到权重。
此外,OmniQuant 引入的所有可学习参数在量化完成后可以被融合消除,量化模型可以基于现有工具完成在多平台的部署,包括 GPU、Android、IOS 等等。
Block-wise 量化误差最小化
OmniQuant 提出了一个新的优化流程,该流程采用 Block-wise 量化误差最小化,并且以可微分的方式优化额外的量化参数。其中,优化目标公式化如下:
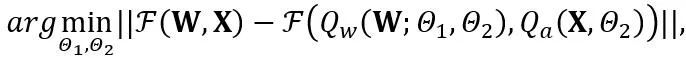
其中 F 代表 LLM 中一个变换器块的映射函数,W 和 X 分别是全精度权重和激活,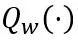 和
和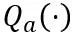 分别代表权重和激活量化器,
分别代表权重和激活量化器,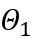 和
和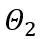 分别是可学习的权重裁剪(LWC)和可学习的等价转换(LET)中的量化参数。OmniQuant 安装 Block-wise 量化按顺序量化一个 Transformer Block 中的参数,然后再移动到下一个。
分别是可学习的权重裁剪(LWC)和可学习的等价转换(LET)中的量化参数。OmniQuant 安装 Block-wise 量化按顺序量化一个 Transformer Block 中的参数,然后再移动到下一个。
可学习的权重裁剪 (LWC)
等价转换在模型权重和激活值之间进行量级迁移。OmniQuant 采用的可学习等价转换使得在参数优化过程中会使得模型权重的分布随着训练不断地发生改变。此前直接学习权重裁剪阈值的方法 [1,2] 只适用于权重分布不发生剧烈改变的情况,否则会难以收敛。基于此问题,与以往方法直接学习权重裁剪阈值不同,LWC 通过以下方式优化裁剪强度:
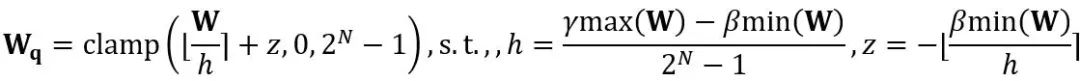
其中 ⌊⋅⌉ 表示取整操作。N 是目标位数。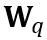 和 W 分别表示量化后和全精度的权重。h 是权重的归一化因子,z 是零点值。裁剪(clamp)操作限制量化值在 N 位整数的范围内,即
和 W 分别表示量化后和全精度的权重。h 是权重的归一化因子,z 是零点值。裁剪(clamp)操作限制量化值在 N 位整数的范围内,即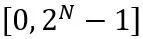 。在上式中,
。在上式中,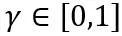 和
和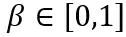 分别是权重上界和下界的可学习裁剪强度。因此,在优化目标函数中
分别是权重上界和下界的可学习裁剪强度。因此,在优化目标函数中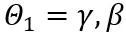 。
。
可学习的等价转换 (LET)
除了通过优化裁剪阈值来实现更适合量化的权重的 LWC 之外,OmniQuant 通过 LET 进一步降低激活值的量化难度。考虑到 LLM 激活值中的异常值是存在于特定通道,以前的方法如 SmoothQuant [3], Outlier Supression+[4] 通过数学上的等价转换将量化的难度从激活值转移到权重。
然而,手工选择或者贪心搜索得到的等价转换参数会限制量化模型的性能。得益于 Block-wise 量化误差最小化的引入,OmniQuant 的 LET 可以以一种可微分的方式确定最优的等价转换参数。受 Outlier Suppression+~\citep {outlier-plus} 的启发,采用了通道级的缩放和通道级的移位来操纵激活分布,为激活值中的异常值问题提供了一个有效的解决方案。具体来说,OmniQuant 探索了线性层和注意力操作中的等价转换。
线性层中的等价转换:线性层接受输入的令牌序列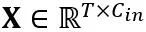 ,其中 T 是令牌长度,是权重矩阵
,其中 T 是令牌长度,是权重矩阵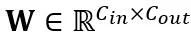 和偏置向量
和偏置向量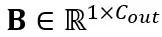 的乘积。数学上等效的线性层表达为:
的乘积。数学上等效的线性层表达为:
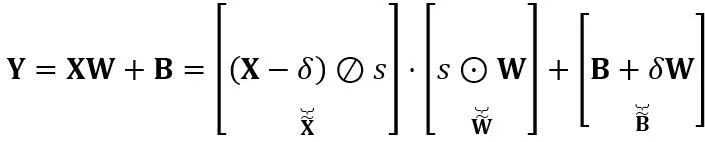
其中 Y 代表输出,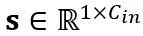 和
和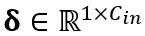 分别是通道级的缩放和移位参数,
分别是通道级的缩放和移位参数,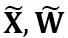 和
和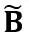 分别是等效激活、权重和偏置,⊘ 和 ⊙ 代表元素级的除法和乘法。通过上式等价转换,激活值被转换为更易于量化的形式,代价是增加了权重的量化难度。从这个意义上说,LWC 可以提高由 LET 实现的模型量化性能,因为它使权重更易于量化。最后,OmniQuant 对转换后的激活和权重进行量化,如下所示
分别是等效激活、权重和偏置,⊘ 和 ⊙ 代表元素级的除法和乘法。通过上式等价转换,激活值被转换为更易于量化的形式,代价是增加了权重的量化难度。从这个意义上说,LWC 可以提高由 LET 实现的模型量化性能,因为它使权重更易于量化。最后,OmniQuant 对转换后的激活和权重进行量化,如下所示
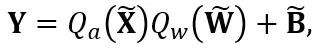
其中 Q_a 是普通的 MinMax 量化器,Q_w 是带有可学习权重裁剪(即所提出的 LWC)的 MinMax 量化器。
注意力操作中的等价转换:除了线性层之外,注意力操作也占据了 LLM 的大部分计算。此外,LLM 的自回归推理模式需要为每个 token 存储键值(KV)缓存,这对于长序列来说导致了巨大的内存需求。因此,OmniQuant 也考虑将自主力计算中的 Q/K/V 矩阵量化为低位。具体来说,自注意力矩阵中的可学习等效变换可以写为:
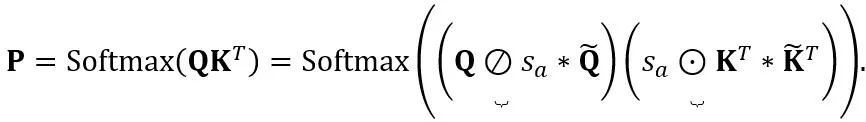
其中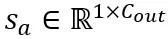 缩放因子。自注意力计算中的量化计算表达为
缩放因子。自注意力计算中的量化计算表达为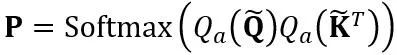 。在这里 OmniQuant 也使用 MinMax 量化方案作为
。在这里 OmniQuant 也使用 MinMax 量化方案作为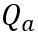 来量化
来量化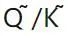 矩阵。所以,最终优化目标函数中的
矩阵。所以,最终优化目标函数中的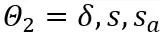 。
。
伪代码

OmniQuant 的伪算法如上图所示。注意,LWC 与 LET 引入的额外参数在模型量化完后都可以被消除,即 OmniQuant 不会给量化模型引入任何额外开销,因此其可直接适配于现有的量化部署工具。
实验性能
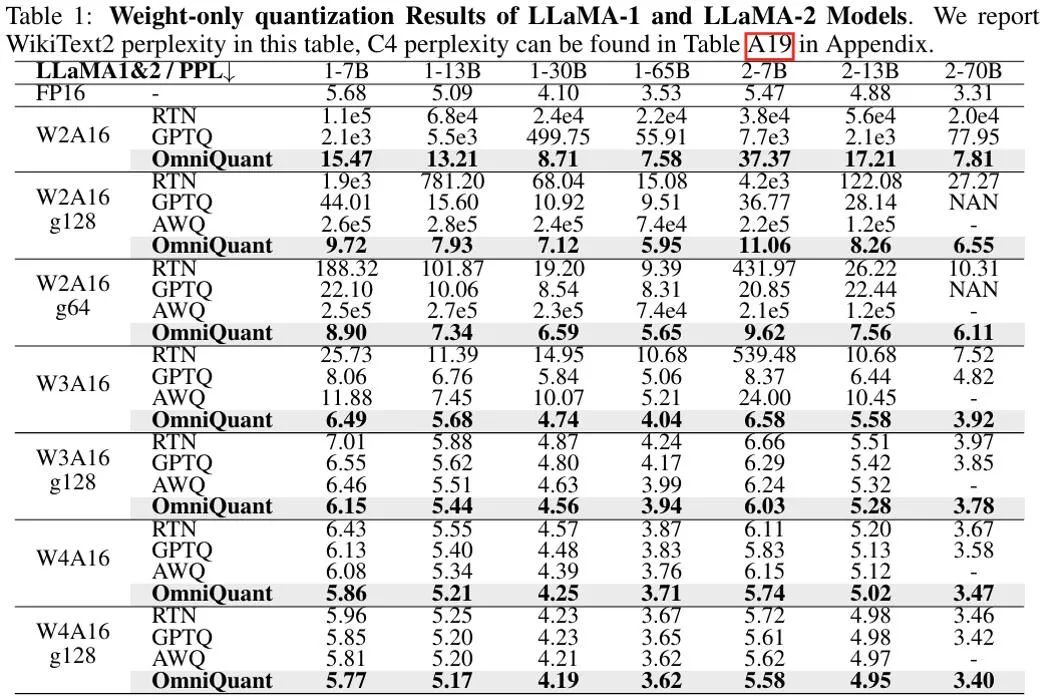
上图显示了 OmniQuant 在 LLaMA 模型上仅权重量化结果的实验结果,更多 OPT 模型结果详见原文。可以看出,OmniQuant 在各种 LLM 模型(OPT、LLaMA-1、LLaMA-2)以及多样化的量化配置(包括 W2A16、W2A16g128、W2A16g64、W3A16、W3A16g128、W4A16 和 W4A16g128)中,始终优于以前的 LLM 仅权重量化方法。同时,这些实验表明了 OmniQuant 的通用性,能够适应多种量化配置。例如,尽管 AWQ [5] 在分组量化方面特别有效,但 OmniQuant 在通道级和分组级量化中均显示出更优的性能。此外,随着量化比特位数的减少,OmniQuant 的性能优势变得更加明显。
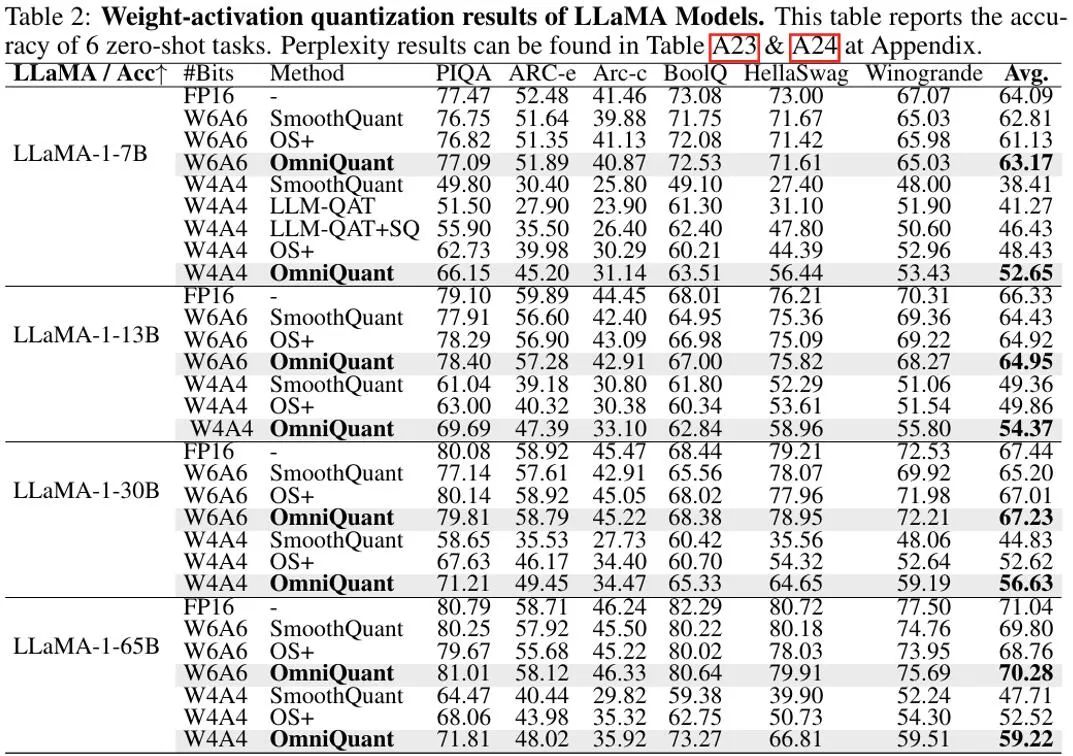
在权重和激活值都量化的设置中中,实验主要关注点在于 W6A6 和 W4A4 量化。实验设置中排除了 W8A8 量化,因为与全精度模型相比,此前的 SmoothQuant 几乎可以实现无损的 W8A8 模型量化。上图显示了 OmniQuant 在 LLaMA 模型上权重激活值都量化结果的实验结果。值得注意的是,在 W4A4 量化的不同模型中,OmniQuant 显著提高了平均准确率,增幅在 + 4.99% ∼ +11.80% 之间。特别是在 LLaMA-7B 模型中,OmniQuant 甚至以 + 6.22% 的显著差距超越了最近的量化感知训练方法 LLM-QAT [6]。这一改进证明了引入额外可学习参数的有效性,这比量化感知训练所采用的全局权重调整更为有益。
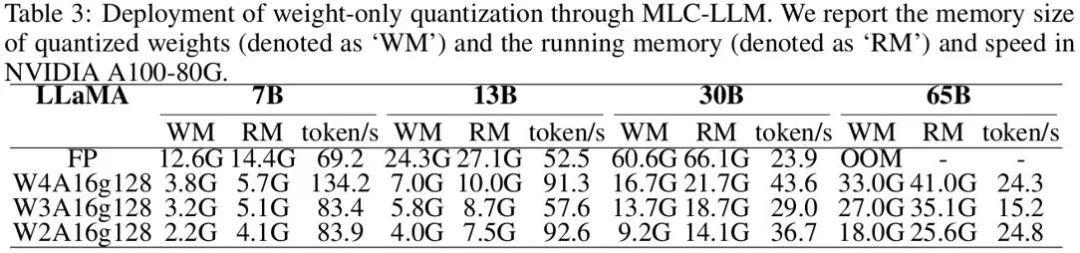
同时,使用 OmniQuant 量化的模型可以在 MLC-LLM [7] 上实现无缝部署。上图展示了 LLaMA 系列量化模型在 NVIDIA A100-80G 上的内存需求和推理速度。
Weights Memory (WM) 代表量化权重存储,而 Running Memory (RM) 表示推理过程中的内存,后者更高是因为保留了某些激活值。推理速度是通过生成 512 个令牌来衡量的。显而易见,与 16 位全精度模型相比,量化模型显著减少了内存使用。而且,W4A16g128 和 W2A16g128 量化几乎使推理速度翻倍。
值得注意的是,MLC-LLM [7] 也支持 OmniQuant 量化模型在其余平台的部署,包括 Android 手机和 IOS 手机。如上图所示,近期的应用 Private LLM 即是利用 OmniQuant 算法来完成 LLM 在 iPhone、iPad,macOS 等多平台的内存高效部署。
总结
OmniQuant 是一种将量化推进到到低比特格式的先进大语言模型量化算法。OmniQuant 的核心原则是保留原始的全精度权重的同时添加可学习的量化参数。它利用可学习的权重才接和等价变换来优化权重和激活值的量化兼容性。在融合梯度更新的同时,OmniQuant 保持了与现有的 PTQ 方法相当的训练时间效率和数据效率。此外,OmniQuant 还确保了硬件兼容性,因为其添加的可训练参数可以被融合到原模型中不带来任何额外开销。
Reference
[1] Pact: Parameterized clipping activation for quantized neural networks.
[2] LSQ: Learned step size quantization.
[3] Smoothquant: Accurate and efficient post-training quantization for large language models.
[4] Outlier suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling.
[5] Awq: Activation-aware weight quantization for llm compression and acceleration.
[6] Llm-qat: Data-free quantization aware training for large language models.
[7] MLC-LLM:https://github.com/mlc-ai/mlc-llm
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 三星推出卷轴手机配备空气质量传感器,开创健康科技新领域
- 近日,有消息人士@xleaks7透露了三星最新的专利设计,其中包括一款配备空气质量传感器的卷轴手机。这项创新设计体现了当今消费者对环境健康越来越重视的态度,并将这种需求融入到日常电子设备中。据报道,三星推出的卷轴手机在保持设备便携性、实用性和美观性的基础上,独具创意地搭载了空气质量传感器。这一举措为便携式电子设备提供了全新可能性,使空气质量监测变得更高效、可靠且用户友好。据小编了解,该款手机的突出特性包括一个可调节的滑动外壳,这一设计不仅可以调整显示屏的尺寸,还可以控制气流进入空气质量传感器。手机采用可滚
- 2分钟前 三星 0
-
 正版软件
正版软件
- 岚图汽车三月投入十亿补贴,全系车型最高可享受5万元现金优惠
- 3月7日消息,岚图汽车近日宣布,将在三月启动一项规模高达“十亿”的补贴活动,为消费者提供极具吸引力的现金优惠。据悉,此次活动中,部分车型的优惠幅度甚至达到了惊人的“5万元”。与此同时,众多车企也纷纷加入了降价补贴的行列,包括比亚迪、吉利、哪吒等在内的十余家知名车企都已推出了相应的优惠措施。据小编了解,岚图汽车的此次补贴活动将持续至2024年3月31日,涵盖了岚图梦想家、新岚图FREE、岚图追光等多款热门车型。具体优惠政策如下:新岚图梦想家的售价在33.99万至46.99万元之间,消费者可享受高达3万元的置
- 12分钟前 岚图汽车 0
-
 正版软件
正版软件
- 预测:苹果将在2027年推出20.3英寸折叠屏MacBook,分析师郭明錤指出
- 近日,随着折叠屏技术逐渐成熟并市场需求不断增长,业界对于苹果推出折叠屏设备的期待也在不断升温。然而,对于近期流传的消息称苹果可能在2025年或2026年开始量产可折叠的iPhone或iPad,著名分析师郭明錤持有不同看法。郭明錤表示,苹果在推出新技术和产品时一向非常谨慎,他认为苹果可能会在技术及市场成熟之后才会考虑推出折叠屏设备。他指出,苹果一直致力于提供稳定和优质的用户体验,因此不会匆忙跟风推出折叠屏设备,而是会等待时机成熟后再推出。尽管市场对根据最新的研究报告,郭明錤指出苹果公司正在内部开发一款具有明
- 27分钟前 苹果 0
-
 正版软件
正版软件
- 广汽本田飞度推出运动时尚套装MUGEN版,正式开售
- 广汽本田今日宣布,旗下备受期待的两款新车型——飞度無限MUGEN版和型格無限MUGEN版已正式上市。这两款新车在原有车型的基础上,加装了原厂無限MUGEN套件,进一步提升了整车外观的运动时尚感。这一举措旨在满足消费者对更具个性化和动感设计的需求,为他们带来全新的驾驶体验。这两款新车的推出将进一步丰富广汽本田的产品线,为消费者提供更多选择,也展示了广汽本田对市场需求的敏锐把握和产品创新的实力。据了解,飞度無限MUGEN版售价为9.78万元。车身尺寸方面,长宽高分别为4125×1694×1537mm,轴距为2
- 42分钟前 广汽本田飞度 0
-
 正版软件
正版软件
- 即将发布的佳能EOS R5 Mark II:全新规格,更强性能
- 据可靠消息透露,佳能公司正全力准备发布新一代全画幅无反光镜相机EOSR5MarkII。据悉,佳能已开始向特定细分市场发布保密协议,计划在今年4月底之前正式推出EOSR5MarkII。预计发布后的几个月内,该相机将陆续上市,以满足消费者的需求。CanonRumors称,这款相机将带来许多令人激动的新功能和性能提升,让摄影爱好者们期待不已。EOSR5MarkII的发布将为相机市场注入新的活力,预计将受到消费者的积极追捧。有关EOSR5MarkII的规格细节已经开始逐渐浮出水面。根据传闻,这款新相机可能配备一块
- 57分钟前 佳能 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1829天前
-
 2
2
- Overture设置踏板标记的方法
- 1666天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1656天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1854天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1820天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1816天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1831天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1852天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00