层次化精细化网络算法用于自动驾驶车道检测
 发布于2024-12-13 阅读(0)
发布于2024-12-13 阅读(0)
扫一扫,手机访问
在视觉导航系统中,车道检测是一项至关重要的功能。它不仅对自动驾驶和高级驾驶员辅助系统(ADAS)等应用有着显著的影响,而且对于智能车辆的自我定位和安全驾驶起着关键作用。因此,车道检测技术的发展对于提高交通系统的智能化和安全性具有重要意义。
然而,车道检测具有独特的局部模式,要求准确预测网络图像中的车道信息,并依赖详细的低级特征来实现精确定位。因此,车道检测可被视为计算机视觉中一项重要而具有挑战性的任务。
使用不同的特征级别对于准确的车道检测非常重要,但折现工作仍处于探索阶段。本文介绍了跨层细化网络(CLRNet),旨在充分利用到车道检测中的高级和低级特征。首先,通过检测具有高级语义特征的车道,然后根据低级特征进行细化。这种方式可以利用更多的上下文信息来检测车道,同时利用本地详细的车道特征来提高定位精度。此外,通过 ROIGather 的方式来收集全局上下文,可以进一步增强车道的特征表示。除了设计全新的网络之外,还引入了线路 IoU 损失,它将车道线作为一个整体单元进行回归,以提高定位精度。
如前所述,由于Lane具有高级语义,但它拥有特定的局部模式,需要详细的低级特征才能准确定位。如何在 CNN 中有效利用不同的特征级别仍然是一个问题。如下图 1(a)所示,地标和车道线具有不同的语义,但它们具有相似的特征(例如长白线)。如果没有高级语义和全局上下文,很难区分它们。另一方面,地域性也很重要,巷子又长又细,当地格局简单。
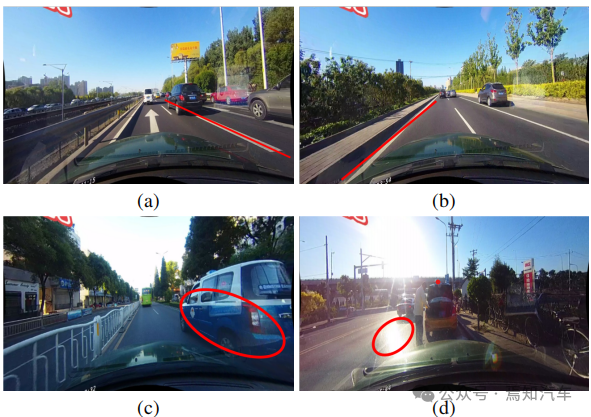
在图1(b)中展示了高级特征的检测结果,虽然成功检测到了车道,但其准确性有待提高。因此,结合低层和高层信息能够相互补充,从而实现更精确的车道检测。
车道检测中常见的另一个问题是缺乏车道存在的视觉信息。在某些情况下,车道可能被其他车辆占据,导致难以检测车道。另外,在极端的光照条件下,车道的识别也会变得困难。
相关工作
以前的工作要么对车道的局部几何进行建模并将其集成到全局结果中,要么构建具有全局特征的全连接层来预测车道。这些检测器已经证明了局部或全局特征对于车道检测的重要性,但没有同时利用好这两个特征,因此可能产生不准确的检测性能。比如,SCNN和RESA提出了一种消息传递机制来收集全局上下文,但这些方法执行像素级预测并且不将车道作为一个整体单元。因此,它们的性能落后于许多最先进的探测器。
对于车道检测来说,低级和高级特征是互补的,基于此,本文提出了一种新颖的网络架构(CLRNet)来充分利用低级和高级特征进行车道检测。首先,通过ROIGather 收集全局上下文来进一步增强车道特征的表示,也可以将其插入其他网络中。其次,提出为车道检测量身定制的线IoU(LIoU)损失,将车道作为整个单元进行回归,并显着提高性能。为了更好地比较不同探测器的定位精度,还采用了新的mF1 指标。
基于CNN的车道检测目前主要分为三种方法:基于分割的方法,基于锚的方法和基于参数的方法,这些方法根据车道的表示方式来进行识别。
1、基于分割的方法
这类算法通常采用逐像素预测公式,即将车道检测视为语义分割任务。SCNN提出了一种消息传递机制来解决非视觉能检测到的目标问题,该机制捕获了车道中呈现的强空间关系。SCNN显着提高了车道检测性能,但该方法对于实时应用来说速度较慢。RESA提出了一种实时特征聚合模块,使网络能够收集全局特征并提高性能。在CurveLane-NAS中,使用神经架构搜索(NAS)来寻找更好的网络来捕获准确的信息,以有利于曲线车道的检测。然而,NAS 的计算成本极其昂贵,并且需要花费大量的 GPU 时间。这些基于分割的方法效率低下且耗时,因为它们对整个图像执行像素级预测,并且不将车道视为一个整体单元。
2、基于锚点的方法
车道检测中基于锚的方法可以分为两类,例如基于线锚的方法和基于行锚的方法。基于线锚的方法采用预定义的线锚作为参考来回归准确的车道。Line-CNN是在车道检测中使用线和弦的开创性工作。LaneATT提出了一种新颖的基于锚的注意力机制,可以聚合全局信息。它实现了最先进的结果,并显示出高功效和效率。SGNet引入了一种新颖的消失点引导锚生成器,并添加了多个结构引导以提高性能。对于基于行锚的方法,它预测图像上每个预定义行的可能单元格。UFLD首先提出了一种基于行锚的车道检测方法,并采用轻量级主干网来实现高推理速度。虽然简单、快速,但其整体性能并不好。CondLaneNet引入了一种基于条件卷积和基于行锚的公式的条件车道检测策略,即它首先定位车道线的起点,然后执行基于行锚的车道检测。但在一些复杂场景下,起点难以识别,导致性能相对较差。
3、基于参数的方法
与点回归不同,基于参数的方法用参数对车道曲线进行建模,并对这些参数进行回归以检测车道。PolyLaneNet采用多项式回归问题并取得了很高的效率。LSTR将道路结构和相机位姿考虑在内来对车道形状进行建模,然后将Transformer引入车道检测任务以获得全局特征。
基于参数的方法需要回归的参数较少,但对预测参数敏感,例如,高阶系数的错误预测可能会导致车道形状的变化。尽管基于参数的方法具有很快的推理速度,但它们仍然难以实现更高的性能。
跨层细化网络(CLRNet)的方法论概述
在本文中,介绍了一种新的框架——跨层细化网络(CLRNet),它充分利用低级和高级特征进行车道检测。具体来说,首先对高语义特征进行检测以粗略地定位车道。然后再根据细节特征逐步细化车道位置和特征提取可以获得高精度的检测结果(即更精确的位置)。为了解决车道的非视觉所能探测的区域盲区问题,引入了 ROI收集器,通过建立ROI车道特征与整个特征图之间的关系来捕获更多的全局上下文信息。此外,还定义了车道线的交并比 IoU,并提出 Line IoU (LIoU) 损失,将车道作为一个整体单元进行回归,与标准损失(即 smooth-l1 损失)相比,显着提高了性能。
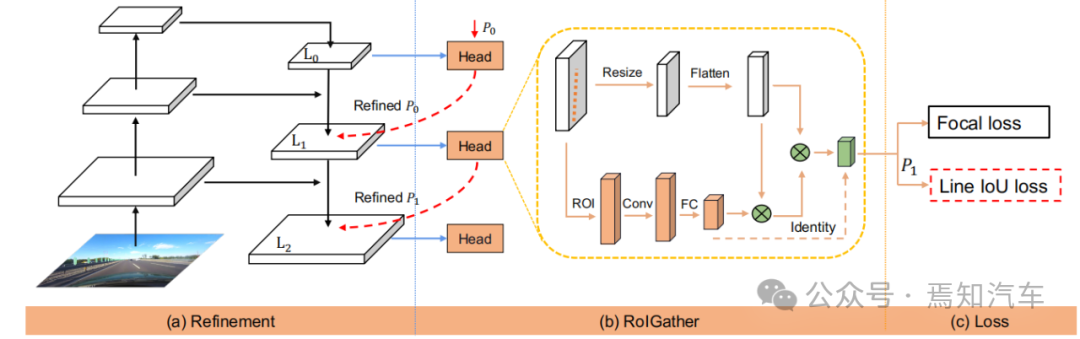
图 2. CLRNet 概述
如上图表示了本文介绍的CLRNet算法进行车道线IoU处理的整个前端网络。其中,图(a)网络从 FPN 结构生成特征图。随后,每个车道先验将从高级特征细化为低级特征。图(b)表示每个头将利用更多上下文信息为车道获取先验特征。图(c)则表示车道先验的分类和回归。而本文所提出的 Line IoU 损失有助于进一步提高回归性能。
如下将更加详细说明本文介绍的算法工作过程。
1、车道网络表示
众所周知,实际道路中的车道又细又长,这种特征表示是具有很强的形状先验信息的,因此预定义的车道先验可以帮助网络更好地定位车道。在常规的目标检测中,目标由矩形框表示。然而,无论何种矩形框却并不适合表示长线。这里使用等距的二维点作为车道表示。具体来说,车道表示为点序列,即 P = {(x1, y1), ···,(xN , yN )}。点的 y 坐标在图像垂直方向上均匀采样,即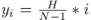 ,其中 H 是图像高度。因此,x坐标与相应的
,其中 H 是图像高度。因此,x坐标与相应的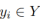 相关联,这里将这种表示称为 Lane 优先。每个车道先验将由网络预测,并由四个部分组成:
相关联,这里将这种表示称为 Lane 优先。每个车道先验将由网络预测,并由四个部分组成:
(1) 前景和背景概率。
(2) 车道长度优先。
(3) 车道线的起点与先验车道的 x 轴之间的角度(称为 x、y 和 θ)。
(4) N 个偏移量,即预测与其真实值之间的水平距离。
2、跨层细化动机
在神经网络中,深层的高级特征对具有更多语义特征的道路目标表现出更强烈的反馈,而浅层的低级特征则具有更多的局部上下文信息。算法允许车道对象访问高级特征可以帮助利用更有用的上下文信息,例如区分车道线或地标。同时,精细的细节特征有助于以高定位精度检测车道。在对象检测中,它构建特征金字塔以利用ConvNet特征层次结构的金字塔形状,并将不同尺度的对象分配给不同的金字塔级别。然而,很难直接将一条车道仅分配给一个级别,因为高级和低级功能对于车道都至关重要。受 Cascade RCNN的启发,可以将车道对象分配给所有级别,并按顺序来检测各个车道。
特别是,可以检测具有高级特征的车道,以粗略地定位车道。根据检测到的已知车道,就可以使用更详细的特征来细化它们。
3、细化结构
整个算法的目标是利用 ConvNet 的金字塔特征层次结构(具有从低级到高级的语义),并构建一个始终具有高级语义的特征金字塔。以残差网络ResNet作为主干,使用{L0, L1, L2}表示 FPN 生成的特征级别。
如图2所示,跨层细化是从最高级别L0开始的,且逐渐接近L2。通过使用{R0,R1,R2}来表示相应的细化。然后可以继续构建一系列的细化结构:
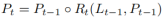
其中 t = 1, · · · , T, T 是细化的总数。
整个方法从具有高语义的最高层执行检测,Pt是车道先验的参数(起点坐标x、y和角度θ),它是受启发且可自学习的。对于第一层L0,P0均匀分布在图像平面上,细化Rt以Pt作为输入以获得ROI车道特征,然后执行两个FC层以获得细化参数Pt。逐步细化车道先验信息和特征信息提取对于跨层细化是非常重要。注意,此方法不限于 FPN 结构,仅使用 ResNet或采用 PAFPN也是合适的。
4、ROI 收集
在为每个特征图分配车道先验信息后,可以使用 ROI Align模块获得车道先验的特征。然而,这些特征的上下文信息仍然不够。在某些情况下,车道实例可能会被占用或在极端照明条件下会变得模糊。在这种情况下,可能没有局部视觉实时跟踪数据来表明车道的存在性。为了确定一个像素是否属于车道,需要查看附近的特征。最近的一些研究也表明,如果充分利用远程依赖关系,性能可以得到提高。因此,可以收集更多有用的上下文信息来更好地学习车道特征。
为此,先沿车道进行卷积计算,这样,车道先验中的每个像素都可以收集附近像素的信息,并且可以根据该信息对占用的部分进行强化。此外,还通过建立了车道先验特征和整个特征图之间的关系。因此,可以利用更多的上下文信息来学习更好的特征表示。
整个ROI搜集模块结构重量轻且易于实施。因为,它以特征图和车道先验作为输入,每个车道先验有 N 个点。与边界框的 ROI Align 不同,对于每个车道先验信息搜集,需要先按照 ROI Align得到车道先验的 ROI 特征 (Xp ∈ RC×Np )。从车道先验中均匀采样 Np 点,并使用双线性插值来计算这些位置处输入特征的精确值。对于L1、L2的ROI特征,可以通过连接前几层的 ROI 特征来增强特征表示。通过对提取的 ROI 特征进行卷积可以收集每个车道像素的附近特征。为了节省内存,这里使用全连接来进一步提取车道先验特征(Xp ∈ RC×1),其中,特征图的大小调整为 Xf ∈ RC×H×W ,可以继续展平为 Xf ∈RC×HW 。
为了收集车道具有先验特征的全局上下文信息,需要首先计算 ROI 车道先验特征 (Xp) 和全局特征图 (Xf) 之间的注意力矩阵 W,其写为:
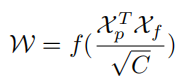
其中 f 是归一化函数 soft max。聚合后的特征可写为:
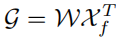
输出 G 反映了 Xf 对 Xp 的叠加值,它是从 Xf 的所有位置中选择的。最后,将输出添加到原始输入 Xp 上。
为了进一步演示 ROIGather 在网络中的工作原理,在图3 中可视化了注意力图的ROIGather 分析。它显示了车道先验的 ROI 特征和整个特征图之间的注意力。橙色线是之前对应的车道,红色区域对应于注意力权重的高分。
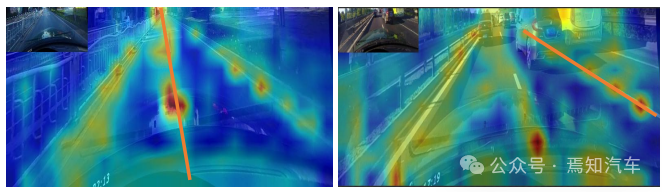
图 3. ROIGather 中注意力权重的图示
如上图显示了车道先验(橙色线)的 ROI 特征与整个特征图之间的注意力权重。颜色越亮,权重值越大。值得注意的是,所提出的 ROIGather 可以有效地收集具有丰富语义信息的全局上下文,即使在遮挡下也能捕获前景车道的特征。
5、车道线交并比IoU 损失
如上所述,车道先验由需要与其基本事实回归的离散点组成。常用的距离损失(如 smooth-l1)可用于对这些点进行回归。然而,这种损失将点作为单独的变量,这是一个过于简单化的假设,导致回归不太准确。
与距离损失相反,并集交集(IoU)可以将车道先验作为一个整体单元进行回归,并且它是针对评估指标量身定制的。这里推导出一种简单有效的算法来计算线 IoU (LIoU) 损失。
如下图所示,线交并比 IoU可以通过根据采样的 xi 位置对扩展段的 IoU 进行积分来计算。
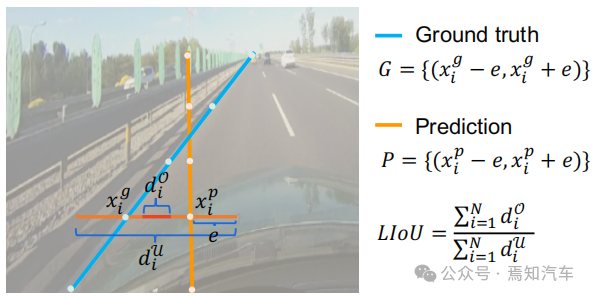
图 4. 线 IoU 图示
如上图所示的公式中显示,从线段交并比 IoU 的定义开始引入线 IoU 损失,即两条线段之间相互作用与并集的比率。对于如图 4 所示的预测车道中的每个点,首先将其(xpi )以半径 e 延伸为线段。然后,可以计算延长线段与其groundtruth之间的IoU,写为:
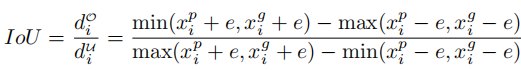
其中 xpi - e, xpi + e 是 xpi 的扩展点,xgi -e,xgi + e 是对应的groundtruth点。请注意,d0i可以为负值,这使得在非重叠线段的情况下可以进行有效的信息优化。
那么LIoU可以被认为是无限线点的组合。为了简化表达式并易于计算,将其转换为离散形式,
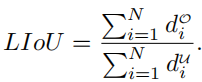
然后,LIoU损失定义为:
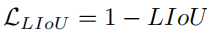
其中−1 ≤ LIoU ≤1,当两条线完美重叠时,则LIoU = 1,当两条线相距较远时,LIoU收敛于-1。
通过Line IoU损失来计算车道线关联关系有两个优点:(1)它简单且可微分,很容易实现并行计算。(2)它将车道作为一个整体进行预测,这有助于提高整体性能。
6、训练和推理细节
首先,是进行正向样本选择。
在训练过程中,每个地面真实车道作为正样本被动态分配一个或多个预测车道。特别是,根据分配成本对预测车道进行排序,其定义为:
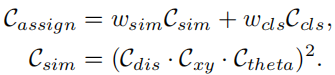
这里 Ccls 是预测和标签之间的焦点成本。Csim 是预测车道和真实车道之间的相似成本。它由三部分组成,Cdis表示所有有效车道点的平均像素距离,Cxy表示起点坐标的距离,Ctheta表示theta角的差值,它们都归一化为[0, 1]。wcls和wsim是每个定义分量的权重系数。每个地面实况车道都根据 Cassign 分配有动态数量(top-k)的预测车道。
其次,是训练损失。
训练损失包括分类损失和回归损失,其中,回归损失仅对指定的样本进行计算。总体损失函数定义为:
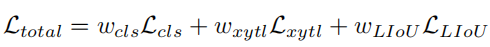
Lcls 是预测和标签之间的焦点损失,Lxytl 是起点坐标、theta 角度和车道长度回归的 smooth-l1 损失,LLIoU 是预测车道和地面实况之间的线 IoU 损失。通过添加辅助分割损失的方式,仅在训练期间使用,没有推理成本。
最后,是进行有效推理。通过设置一个带有分类分数的阈值来过滤背景车道(低分车道先验),并使用 nms 来删除之后的高重叠车道。如果使用一对一分配,即设置 top-k = 1,这里也可以是无 nms 的。
总结
在本文中,我们提出了用于车道检测的跨层细化网络(CLRNet)。CLRNet 可以利用高级特征来预测车道,同时利用局部详细特征来提高定位精度。为了解决车道存在的视觉证据不足的问题,提出通过 ROIGather 建立与所有像素的关系来增强车道特征表示。为了将车道作为一个整体进行回归,提出了为车道检测量身定制的 Line IoU 损失,与标准损失(即 smooth-l1 损失)相比,它大大提高了性能。本方法在三个车道检测基准数据集(即 CULane、LLamas 和 Tusimple)上进行评估。所提出的方法在三个车道检测基准上大大优于其他最先进的方法(CULane、Tusimple和 LLAMAS)。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- iQOO Neo9系列曝光:搭载高通骁龙8s Gen3,采用无塑料支架直屏设计
- 数码博主@数码闲聊站今日曝光了一款iQOO新机的消息,称该机可能归属于备受瞩目的Neo9系列。据该博主透露,这款iQOO新机已经完成了备案,并将搭载骁龙8sGen3处理器。此外,该机主打的一大卖点是采用了国产无塑料支架的直屏设计,具体参数包括6.78英寸的屏幕、2800×1260p的分辨率、1.5K+144Hz的刷新率。在低亮度下,该机还支持2160HzPWM高频调光。在摄像头方面,该机将采用50Mp大底双摄方案。之前,该博主还曝光了一则消息,称iQOONeo9系列新机预计将在4月份正式发布。去年12月发
- 12分钟前 iQOO 0
-
 正版软件
正版软件
- AR/VR如何促进自动化和机器人制造领域的发展
- AR/VR技术如何为机器人提供动力以及它们如何使工厂和工业受益,本文对此进行探讨。由于新冠疫情持续蔓延,以及供应链中断、劳动力短缺和通货膨胀等挑战的出现,2022年商业环境发生了显著变化。这些问题的影响迫使许多企业和制造业高管不得不考虑采用自动化和机器人技术来改善其生产、分销和履行设施。这种转变不仅是为了提高生产效率和降低成本,还是为了应对不稳定因素对企业运营造成的影响。通过引入先进技术,企业可以更好地应对当前的挑战,提升竞争力,并为企业在持续的经济挑战和商业投资者的持续压力下,面临着更大的竞争压力。因此
- 27分钟前 机器人 AR VR 0
-
 正版软件
正版软件
- 揭秘苹果最新专利:iPhone相机消除红眼效果
- 近日,美国商标和专利局公布了苹果公司成功获得的一项关于iPhone相机技术的新专利。该专利的主要目的是通过消除或减轻拍摄时出现的红眼现象,从而提高照片的质量。这项专利技术的创新性在于利用先进的算法和光学技术来识别并自动修复照片中的红眼问题,使用户能够拍摄更清晰、更生动的照片。苹果公司一直致力于不断提升其产品的摄影功能,这项专利的授权进一步证明了苹果在相机技术领域的领先地位。在摄影中,红眼现象是一个常见的问题,尤其是在低光条件下使用闪光灯时更加明显。这种现象是由于闪光灯光线穿过被摄者的瞳孔照射到眼底,再经反
- 42分钟前 苹果 0
-
 正版软件
正版软件
- 北京奔驰全面超越500万辆生产大关,迈入“双500万”全新时代
- 北京奔驰近日宣布,其整车累计产量已突破500万辆,这一里程碑标志着梅赛德斯-奔驰在中国本土生产历程中取得了重要成就。这一成就凸显了奔驰在全球汽车制造业中的卓越地位。自2005年北京奔驰生产出第一辆国产梅赛德斯-奔驰汽车——代号为W211的第八代E级车以来,其生产速度不断加快,每个百万产量的达成时间都在持续缩短。从最初的11年,到后来的2年、22个月、21个月,再到最近的20个月,这一成就不仅展示了北京奔驰的高效生产能力,也反映了中国汽车市场的蓬勃发展和消费者对高品质汽车的不断增长的需求。小编了解到,北京奔
- 57分钟前 奔驰 0
-
 正版软件
正版软件
- “荣耀春季旗舰系列发布会即将启动,Magic6至臻版和保时捷设计RSR版值得期待”
- 3月8日消息,荣耀手机今日正式宣布,将于3月18日19:30盛大举行荣耀春季旗舰新品发布会。届时,备受期待的荣耀Magic6至臻版、与保时捷设计联手打造的荣耀Magic6RSR保时捷设计版,以及荣耀首款AIPC——荣耀MagicBookPro16将悉数登场,为科技爱好者们带来一场视觉与技术的盛宴。荣耀与保时捷设计再次携手合作,将科技与奢华完美结合。他们以RSR命名的新旗舰手机必将带来卓越的产品性能。在跑车行业,RSR象征着稀缺和高端地位,荣耀此次将其引入手机领域,暗示着这款新品将拥有超强性能和独特设计。据
- 1小时前 20:25 荣耀 0













