清华大学发布最新移动端神经网络架构 RepViT,性能耗时仅为1.3ms
 发布于2024-12-14 阅读(0)
发布于2024-12-14 阅读(0)
扫一扫,手机访问

论文地址:https://arxiv.org/abs/2307.09283
代码地址:https://github.com/THU-MIG/RepViT

RepViT 在移动端 ViT 架构中表现出色,展现出显著的优势。接下来,我们将探讨本研究的贡献所在。
- 文中提到,轻量级 ViTs 通常比轻量级 CNNs 在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(
MSHA)可以让模型学习全局表示。然而,轻量级 ViTs 和轻量级 CNNs 之间的架构差异尚未得到充分研究。 - 在这项研究中,作者们通过整合轻量级 ViTs 的有效架构选择,逐步提升了标准轻量级 CNN(特别是
MobileNetV3的移动友好性。这便衍生出一个新的纯轻量级 CNN 家族的诞生,即RepViT。值得注意的是,尽管 RepViT 具有 MetaFormer 结构,但它完全由卷积组成。 - 实验结果表明,
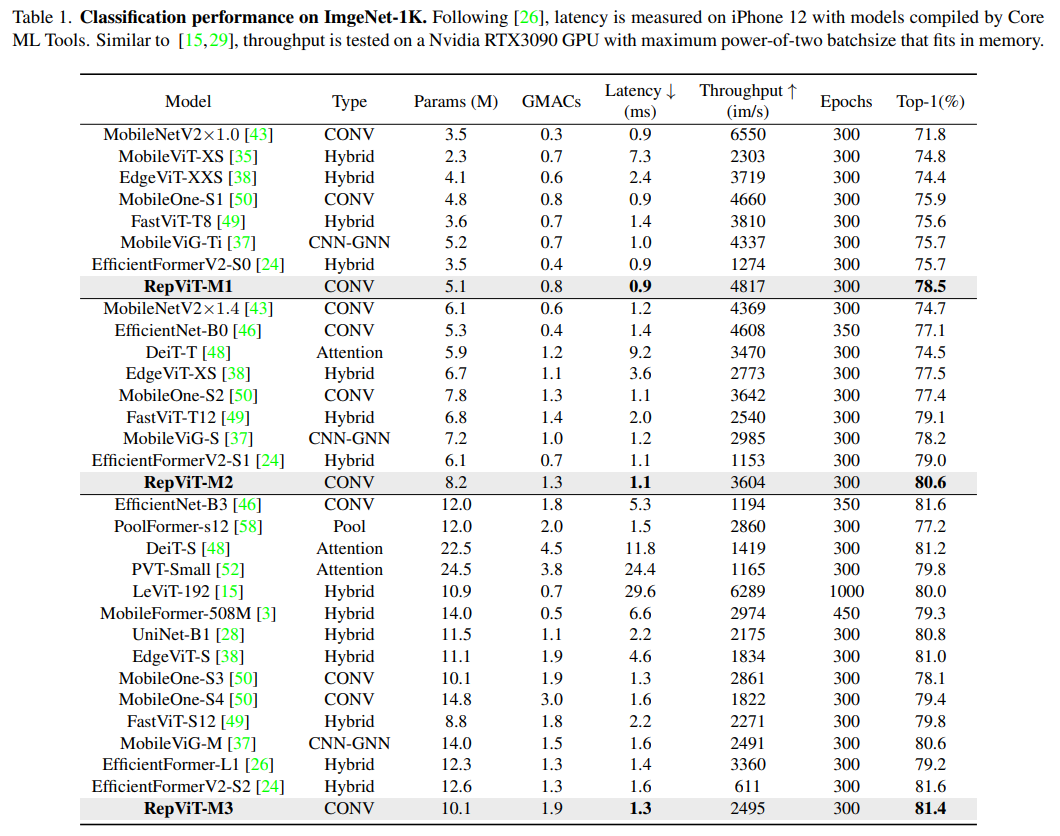
RepViT超越了现有的最先进的轻量级 ViTs,并在各种视觉任务上显示出优于现有最先进轻量级ViTs的性能和效率,包括 ImageNet 分类、COCO-2017 上的目标检测和实例分割,以及 ADE20k 上的语义分割。特别地,在ImageNet上,RepViT在iPhone 12上达到了近乎 1ms 的延迟和超过 80% 的Top-1 准确率,这是轻量级模型的首次突破。
好了,接下来大家应该关心的应该时“如何设计到如此低延迟但精度还很6的模型”出来呢?
方法

再 ConvNeXt 中,作者们是基于 ResNet50 架构的基础上通过严谨的理论和实验分析,最终设计出一个非常优异的足以媲美 Swin-Transformer 的纯卷积神经网络架构。同样地,RepViT也是主要通过将轻量级 ViTs 的架构设计逐步整合到标准轻量级 CNN,即MobileNetV3-L,来对其进行针对性地改造(魔改)。在这个过程中,作者们考虑了不同粒度级别的设计元素,并通过一系列步骤达到优化的目标。
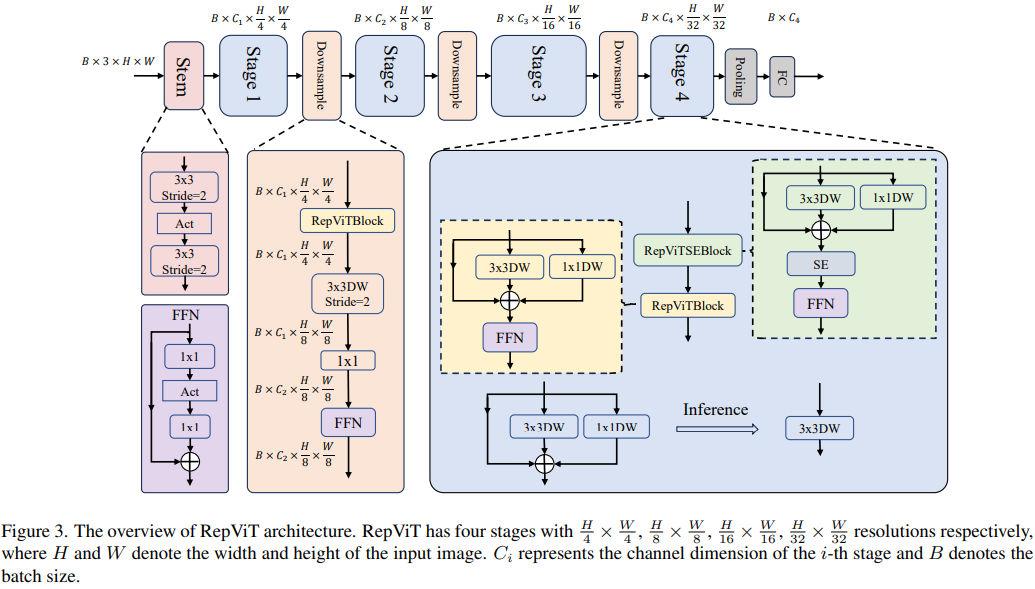
训练配方的对齐
在论文中,新引入了一个用于衡量移动设备上延迟的指标,并确保训练策略与目前流行的轻量级 ViTs 保持一致。这一举措的目的是为了保证模型训练的一贯性,其中涉及到延迟度量和训练策略的调整两个关键概念。
延迟度量指标
为了更准确地衡量模型在真实移动设备上的性能,作者选择了直接测量模型在设备上的实际延迟,以此作为基准度量。这个度量方法不同于之前的研究,它们主要通过FLOPs或模型大小等指标优化模型的推理速度,这些指标并不总能很好地反映在移动应用中的实际延迟。
训练策略的对齐
这里,将 MobileNetV3-L 的训练策略调整以与其他轻量级 ViTs 模型对齐。这包括使用 AdamW 优化器【ViTs 模型必备的优化器】,进行 5 个 epoch 的预热训练,以及使用余弦退火学习率调度进行 300 个 epoch 的训练。尽管这种调整导致了模型准确率的略微下降,但可以保证公平性。
块设计的优化
接下来,基于一致的训练设置,作者们探索了最优的块设计。块设计是 CNN 架构中的一个重要组成部分,优化块设计有助于提高网络的性能。

分离 Token 混合器和通道混合器
这块主要是对 MobileNetV3-L 的块结构进行了改进,分离了令牌混合器和通道混合器。原来的 MobileNetV3 块结构包含一个 1x1 扩张卷积,然后是一个深度卷积和一个 1x1 的投影层,然后通过残差连接连接输入和输出。在此基础上,RepViT 将深度卷积提前,使得通道混合器和令牌混合器能够被分开。为了提高性能,还引入了结构重参数化来在训练时为深度滤波器引入多分支拓扑。最终,作者们成功地在 MobileNetV3 块中分离了令牌混合器和通道混合器,并将这种块命名为 RepViT 块。
降低扩张比例并增加宽度
在通道混合器中,原本的扩张比例是 4,这意味着 MLP 块的隐藏维度是输入维度的四倍,消耗了大量的计算资源,对推理时间有很大的影响。为了缓解这个问题,我们可以将扩张比例降低到 2,从而减少了参数冗余和延迟,使得 MobileNetV3-L 的延迟降低到 0.65ms。随后,通过增加网络的宽度,即增加各阶段的通道数量,Top-1 准确率提高到 73.5%,而延迟只增加到 0.89ms!
宏观架构元素的优化
在这一步,本文进一步优化了MobileNetV3-L在移动设备上的性能,主要是从宏观架构元素出发,包括 stem,降采样层,分类器以及整体阶段比例。通过优化这些宏观架构元素,模型的性能可以得到显著提高。
浅层网络使用卷积提取器
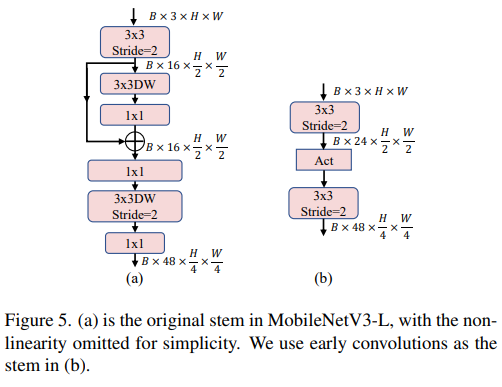 图片
图片
ViTs 通常使用一个将输入图像分割成非重叠补丁的 "patchify" 操作作为 stem。然而,这种方法在训练优化性和对训练配方的敏感性上存在问题。因此,作者们采用了早期卷积来代替,这种方法已经被许多轻量级 ViTs 所采纳。对比之下,MobileNetV3-L 使用了一个更复杂的 stem 进行 4x 下采样。这样一来,虽然滤波器的初始数量增加到24,但总的延迟降低到0.86ms,同时 top-1 准确率提高到 73.9%。
更深的下采样层
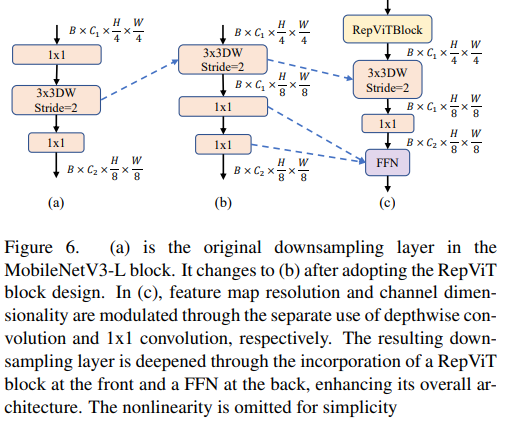
在 ViTs 中,空间下采样通常通过一个单独的补丁合并层来实现。因此这里我们可以采用一个单独和更深的下采样层,以增加网络深度并减少由于分辨率降低带来的信息损失。具体地,作者们首先使用一个 1x1 卷积来调整通道维度,然后将两个 1x1 卷积的输入和输出通过残差连接,形成一个前馈网络。此外,他们还在前面增加了一个 RepViT 块以进一步加深下采样层,这一步提高了 top-1 准确率到 75.4%,同时延迟为 0.96ms。
更简单的分类器

在轻量级 ViTs 中,分类器通常由一个全局平均池化层后跟一个线性层组成。相比之下,MobileNetV3-L 使用了一个更复杂的分类器。因为现在最后的阶段有更多的通道,所以作者们将它替换为一个简单的分类器,即一个全局平均池化层和一个线性层,这一步将延迟降低到 0.77ms,同时 top-1 准确率为 74.8%。
整体阶段比例
阶段比例代表了不同阶段中块数量的比例,从而表示了计算在各阶段中的分布。论文选择了一个更优的阶段比例 1:1:7:1,然后增加网络深度到 2:2:14:2,从而实现了一个更深的布局。这一步将 top-1 准确率提高到 76.9%,同时延迟为 1.02 ms。
微观设计的调整
接下来,RepViT 通过逐层微观设计来调整轻量级 CNN,这包括选择合适的卷积核大小和优化挤压-激励(Squeeze-and-excitation,简称SE)层的位置。这两种方法都能显著改善模型性能。
卷积核大小的选择
众所周知,CNNs 的性能和延迟通常受到卷积核大小的影响。例如,为了建模像 MHSA 这样的远距离上下文依赖,ConvNeXt 使用了大卷积核,从而实现了显著的性能提升。然而,大卷积核对于移动设备并不友好,因为它的计算复杂性和内存访问成本。MobileNetV3-L 主要使用 3x3 的卷积,有一部分块中使用 5x5 的卷积。作者们将它们替换为3x3的卷积,这导致延迟降低到 1.00ms,同时保持了76.9%的top-1准确率。
SE 层的位置
自注意力模块相对于卷积的一个优点是根据输入调整权重的能力,这被称为数据驱动属性。作为一个通道注意力模块,SE层可以弥补卷积在缺乏数据驱动属性上的限制,从而带来更好的性能。MobileNetV3-L 在某些块中加入了SE层,主要集中在后两个阶段。然而,与分辨率较高的阶段相比,分辨率较低的阶段从SE提供的全局平均池化操作中获得的准确率提升较小。作者们设计了一种策略,在所有阶段以交叉块的方式使用SE层,从而在最小的延迟增量下最大化准确率的提升,这一步将top-1准确率提升到77.4%,同时延迟降低到0.87ms。【这一点其实百度在很早前就已经做过实验比对得到过这个结论了,SE 层放置在靠近深层的地方效果好】
网络架构
最终,通过整合上述改进策略,我们便得到了模型RepViT的整体架构,该模型有多个变种,例如RepViT-M1/M2/M3。同样地,不同的变种主要通过每个阶段的通道数和块数来区分。

实验
图像分类
检测与分割
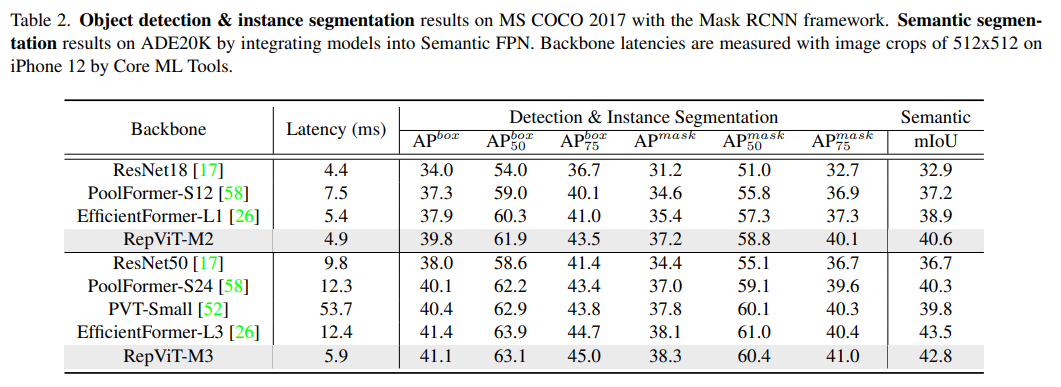
总结
本文通过引入轻量级 ViT 的架构选择,重新审视了轻量级 CNNs 的高效设计。这导致了 RepViT 的出现,这是一种新的轻量级 CNNs 家族,专为资源受限的移动设备设计。在各种视觉任务上,RepViT 超越了现有的最先进的轻量级 ViTs 和 CNNs,显示出优越的性能和延迟。这突显了纯粹的轻量级 CNNs 对移动设备的潜力。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 极越再度联手NVIDIA,高性能计算平台Thor将于2026年上车
- 阔别四年之后,第十八届北京国际汽车展览会重新回归。作为智能化先锋,高端智能汽车机器人品牌极越以“极越智美越来越AI”为主题,演绎未来AI科技,首秀北京车展破圈出位。2024年4月25日,极越汽车机器人携全新产品阵容亮相北京车展,旗下第二款车型——AI智能纯电驱动车极越07迎来车展首秀,以极具艺术审美的中国原创设计,赢得“最美7系”头衔。极越与NVIDIA再度联手,1000TFLOPS的高性能计算平台Thor将于2026年量产上车。同时,极越01也将升级最新V1.5.0版本,PPA智
- 4分钟前 产业 0
-
 正版软件
正版软件
- 比特币钱包地址地址
- 比特币钱包地址是一个唯一的字母数字字符串,用于识别比特币网络上的特定帐户。它由版本字节、校验和和脚本哈希组成。常见格式有旧格式(以1开头)和新格式(以bc1开头)。生成地址需要生成私钥和公钥,然后对公钥进行哈希并使用版本字节和校验和进行格式化。钱包地址是匿名的,但可以通过链上分析与个人身份联系起来,因此保护其安全至关重要。其他类型的地址包括隔离见证地址(SegWit)、多重签名地址和脚本
- 9分钟前 0
-
 正版软件
正版软件
- 减半对比特币价格影响什么
- 减半事件通过以下方式影响比特币价格:减少供应,增加需求增加稀缺性,提高价值存储吸引力增强投资者信心引发投机性需求与市场周期相关,推动牛市上涨长期减少供应,支持价值
- 24分钟前 0
-
 正版软件
正版软件
- 全球数字货币主流币有哪些
- 全球数字货币主流币包括比特币、以太坊、稳定币(如USDT)、币安币、瑞波币、狗狗币、卡尔达诺、索拉纳、波卡和阿瓦克斯,这些加密货币具有较高的市值、交易量和流通范围。
- 39分钟前 0
-
 正版软件
正版软件
- 专项资金已落实,天涯社区将恢复访问
- 本站4月30日消息,今日,天涯社区官方微博发布《关于天涯社区网络平台恢复访问展及新天涯展的公告》。公司宣称已经通过各种策略积极获取各种资本支持,并且已经开始实施符合各方认可的资金方案,不久将形成。目前必须的流程,加上技术的实施,正式恢复访问还需要一些时间。在确保数据安全合规的情况下,最初的恢复访问将从参与天涯会员计划的用户开始,再面向公众提供访问服务。在近期,一款称为“天涯社区”的应用已经重新上架到苹果AppStore以及部分安卓应用商店。该应用在上个月被下架,而现在重新获得了上架的机会。本站附公告全文如
- 54分钟前 天涯 天涯社区 0













