构建下一代决策智能体:超越自回归,实现长序列规划路径
 发布于2024-12-14 阅读(0)
发布于2024-12-14 阅读(0)
扫一扫,手机访问
设想一下,当你站在房间内,准备向门口走去,你是通过自回归的方式逐步规划路径吗?实际上,你的路径是一次性整体生成的。
最新研究指出,利用扩散模型的规划模块可以同时生成长序列的轨迹规划,更符合人类的决策方式。此外,扩散模型在策略表征和数据合成方面还能为现有的决策智能算法提供更为优化的方案。
来自上海交通大学的团队撰写的综述论文《Diffusion Models for Reinforcement Learning: A Survey》梳理了扩散模型在强化学习相关领域的应用。综述指出现有强化学习算法面临长序列规划误差累积、策略表达能力受限、交互数据不足等挑战,而扩散模型已经展现出解决强化学习问题中的优势,并为应对上述长期以来的挑战带来新的思路。

论文链接:https://arxiv.org/abs/2311.01223
项目地址:https://github.com/apexrl/Diff4RLSurvey
该综述对扩散模型在强化学习中的作用进行了分类,总结了不同强化学习场景中扩散模型的成功案例。最后,综述展望了未来利用扩散模型解决强化学习问题的发展方向。
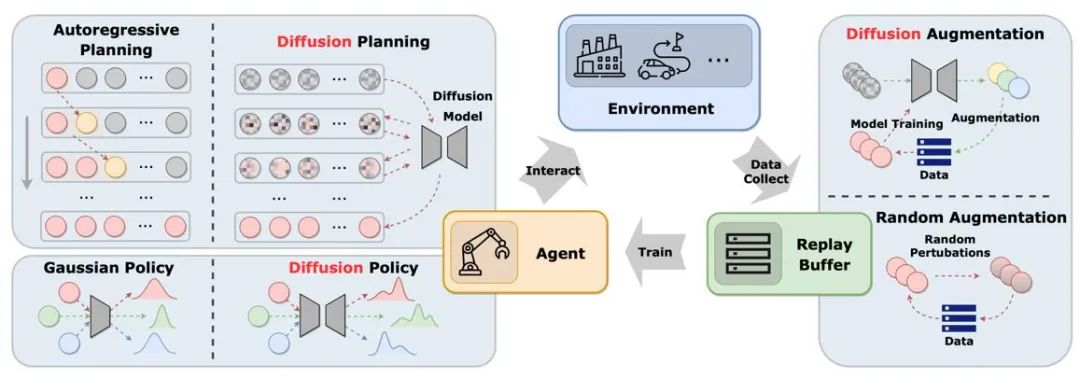
图中展示了扩散模型在经典智能体-环境-经验回放池循环中的作用。与传统解决方案相比,扩散模型为系统引入了新的元素,提供了更全面的信息交互和学习机会。通过这种方式,智能体能够更好地适应环境变化,并且优化其决策
扩散模型在强化学习中扮演的角色
文章根据扩散模型在强化学习中扮演角色的不同,分类比较了扩散模型的应用方式和特点。
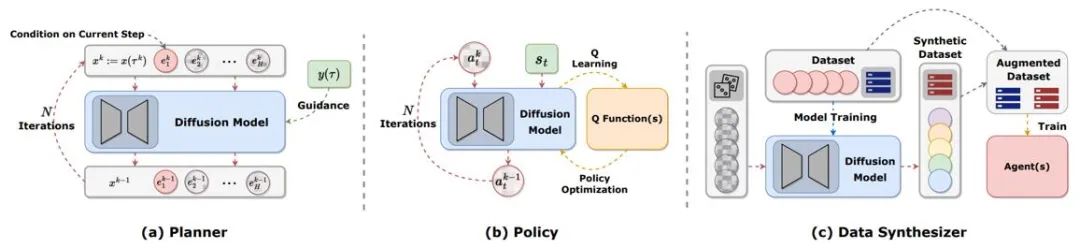
图 2:扩散模型在强化学习中扮演的不同角色。
轨迹规划
强化学习中的规划指通过使用动态模型在想象中做决策,再选择最大化累积奖励的适当动作。规划的过程通常会探索各种动作和状态的序列,从而提升决策的长期效果。在基于模型的强化学习(MBRL)框架中,规划序列通常以自回归方式进行模拟,导致累积误差。扩散模型可以同时生成多步规划序列。现有文章用扩散模型生成的目标非常多样,包括 (s,a,r)、(s,a)、仅有 s、仅有 a 等等。为了在在线评估时生成高奖励的轨迹,许多工作使用了有分类器或无分类器的引导采样技术。
策略表征
扩散规划器更近似传统强化学习中的 MBRL,与之相对,将扩散模型作为策略更类似于无模型强化学习。Diffusion-QL 首先将扩散策略与 Q 学习框架结合。由于扩散模型拟合多模态分布的能力远超传统模型,扩散策略在由多个行为策略采样的多模态数据集中表现良好。扩散策略与普通策略相同,通常以状态作为条件生成动作,同时考虑最大化 Q (s,a) 函数。Diffusion-QL 等方法在扩散模型训练时加上加权的价值函数项,而 CEP 从能量的视角构造加权回归目标,用价值函数作为因子,调整扩散模型学到的动作分布。
数据合成
扩散模型可以作为数据合成器,来缓解离线或在线强化学习中数据稀少的问题。传统强化学习数据增强方法通常只能对原有数据进行小幅扰动,而扩散模型强大的分布拟合能力使其可以直接学习整个数据集的分布,再采样出新的高质量数据。
其他类型
除了以上几类,还有一些零散的工作以其他方式使用扩散模型。例如,DVF 利用扩散模型估计值函数。LDCQ 首先将轨迹编码到隐空间上,再在隐空间上应用扩散模型。PolyGRAD 用扩散模型学习环境动态转移,允许策略和模型交互来提升策略学习效率。
在不同强化学习相关问题中的应用
离线强化学习
扩散模型的引入有助于离线强化学习策略拟合多模态数据分布并扩展了策略的表征能力。Diffuser 首先提出了基于分类器指导的高奖励轨迹生成算法并启发了大量的后续工作。同时,扩散模型也能应用在多任务与多智能体强化学习场景。
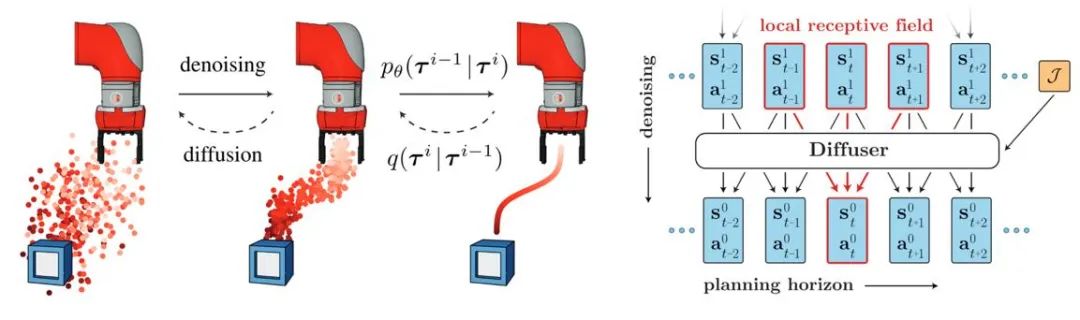
图 3:Diffuser 轨迹生成过程和模型示意图
在线强化学习
研究者证明扩散模型对在线强化学习中的价值函数、策略也具备优化能力。例如,DIPO 对动作数据重标注并使用扩散模型训练,使策略避免了基于价值引导训练的不稳定性;CPQL 则验证了单步采样扩散模型作为策略能够平衡交互时的探索和利用。
模仿学习
模仿学习通过学习专家演示数据来重建专家行为。扩散模型的应用有助于提高策略表征能力以及学习多样的任务技能。在机器人控制领域,研究发现扩散模型能够在保持时序稳定性的条件下预测闭环动作序列。Diffusion Policy 采用图像输入的扩散模型生成机器人动作序列。实验表明扩散模型能够生成有效闭环动作序列,同时保证时序一致性。
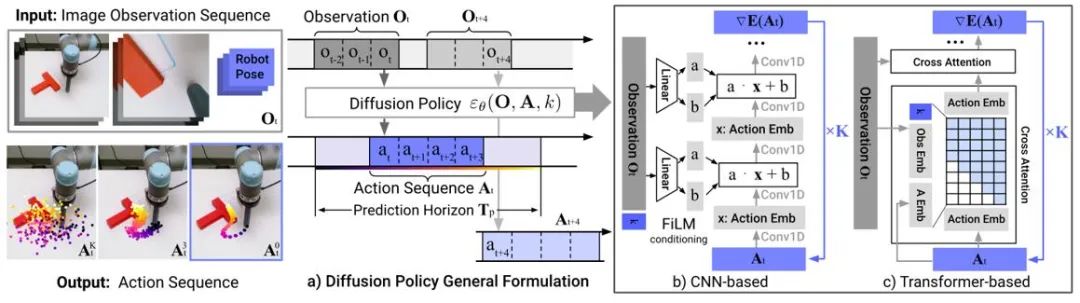
图 4:Diffusion Policy 模型示意图
轨迹生成
扩散模型在强化学习中的轨迹生成主要聚焦于人类动作生成以及机器人控制两类任务。扩散模型生成的动作数据或视频数据被用于构建仿真模拟器或训练下游决策模型。UniPi 训练了一个视频生成扩散模型作为通用策略,通过接入不同的逆动力学模型来得到底层控制命令,实现跨具身的机器人控制。
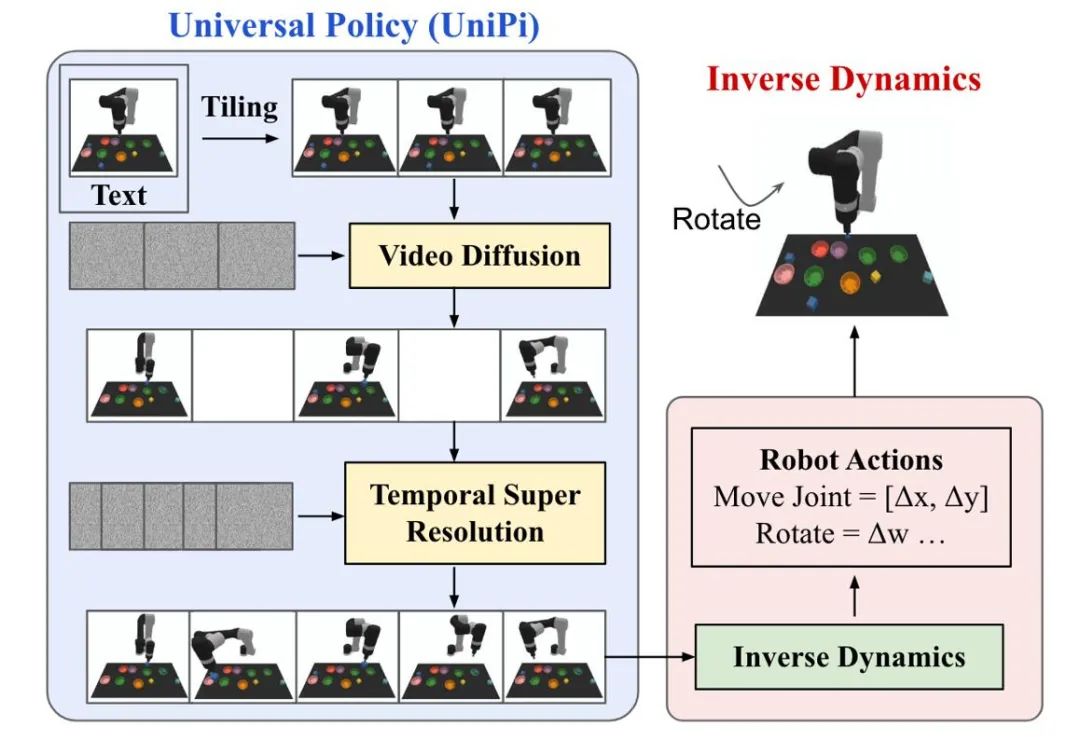
图 5:UniPi 决策过程示意图。
数据增强
扩散模型还可以直接拟合原始数据分布,在保持真实性的前提下提供多样的动态扩展数据。例如,SynthER 和 MTDiff-s 通过扩散模型生成了训练任务的完整环境转移信息并将其应用于策略的提升,且结果显示生成数据的多样程度以及准确性都优于历史方法。
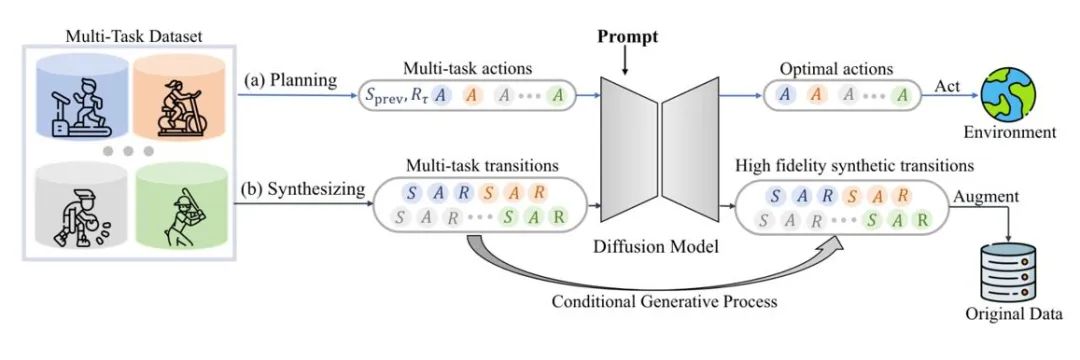
图 6:MTDiff 进行多任务规划和数据增强的示意图
未来展望
生成式仿真环境
如图 1 所示,现有研究主要利用扩散模型来克服智能体和经验回放池的局限性,利用扩散模型增强仿真环境的研究比较少。Gen2Sim 利用文生图扩散模型在模拟环境中生成多样化的可操作物体来提高机器人精密操作的泛化能力。扩散模型还有可能在仿真环境中生成状态转移函数、奖励函数或多智能体交互中的对手行为。
加入安全约束
通过将安全约束作为模型的采样条件,基于扩散模型的智能体可以做出满足特定约束的决策。扩散模型的引导采样允许通过学习额外的分类器来不断加入新的安全约束,而原模型的参数保持不变,从而节省额外的训练开销。
检索增强生成
检索增强生成技术能够通过访问外部数据集增强模型能力,在大语言模型上得到广泛的应用。通过检索与智能体当前状态相关的轨迹并输入到模型中,基于扩散的决策模型在这些状态下的性能同样可能得到提升。如果检索数据集不断更新,智能体有可能在不重新训练的情况下表现出新的行为。
组合多种技能
与分类器引导或无分类器引导相结合,扩散模型可以组合多种简单技能来完成复杂任务。离线强化学习中的早期结果也表明扩散模型可以共享不同技能之间的知识,从而有可能通过组合不同技能实现零样本迁移或持续学习。
表格
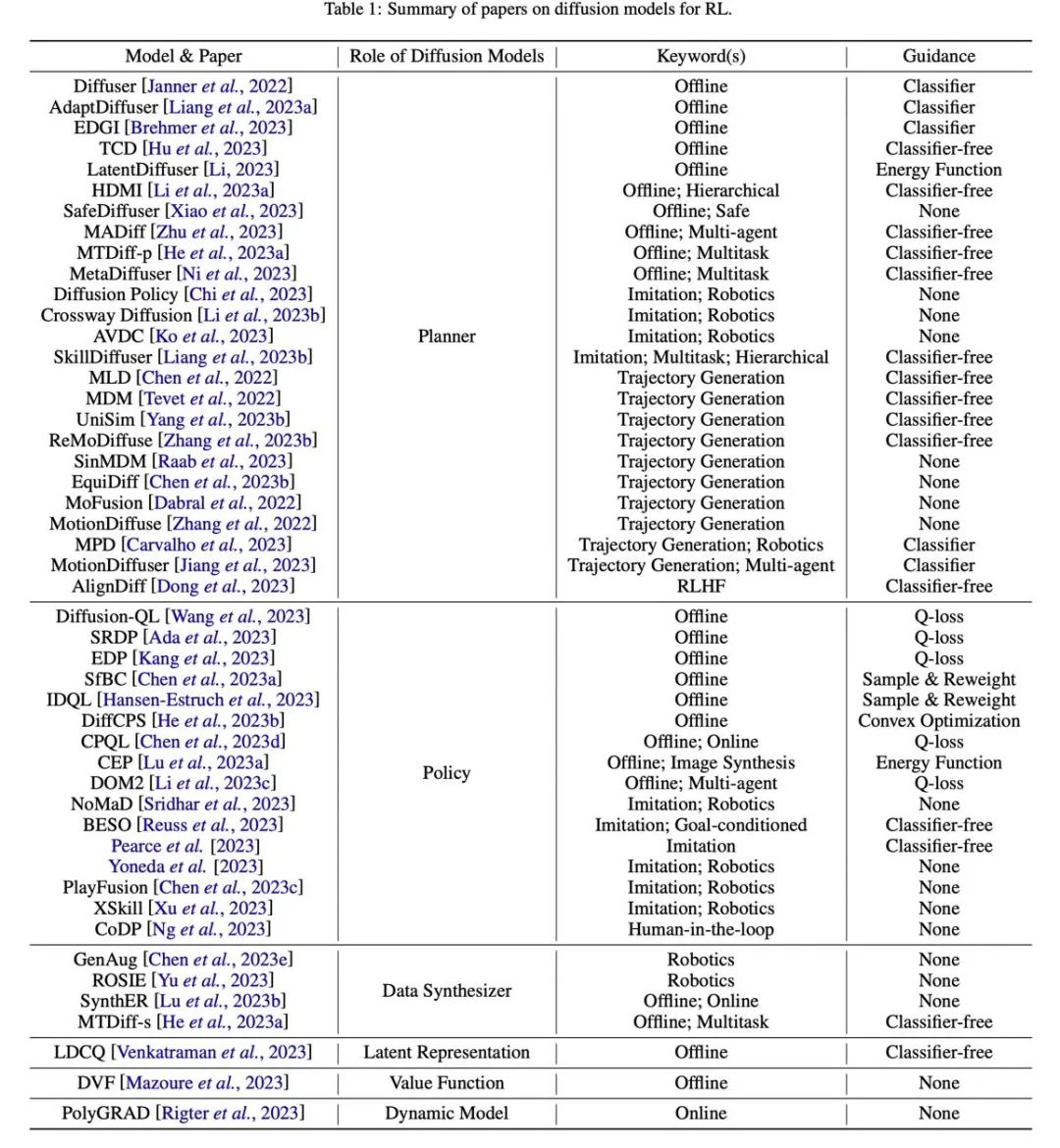
图 7:相关论文汇总分类表格。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 物理世界为何成为LLM的致命弱点?LeCun最新专访揭秘
- 在人工智能领域,很少有像YannLeCun这样的学者,在65岁的年龄还能高度活跃于社交媒体。YannLeCun在人工智能领域以直率的批评者形象为人所知。他一直积极支持开源精神,并领导Meta的团队推出了备受青睐的Llama2模型,成为开源大模型领域的领军人物。尽管许多人对人工智能的未来感到焦虑,担心可能出现的末日情景,但LeCun却持不同看法,坚信人工智能的发展对社会将带来积极影响,尤其是超级智能的到来。近日,LeCun又一次来到LexFridman的播客,展开了一场接近三个小时的对谈,内容涉及开源的重要
- 10分钟前 开源 AGI 0
-
 正版软件
正版软件
- 北汽蓝谷推出新品牌“享界”瞄准BBA市场,预计月销量超过一万辆
- 3月11日,最近一份北汽蓝谷的内部交流纪要引起了业内人士的关注。这份纪要透露,北汽蓝谷与华为合作推出全新品牌“享界”,其首款产品即将在北京车展上亮相,并计划于6月份正式发布。据了解,北汽蓝谷对与华为的合作寄予厚望,为智选车设定了年产能30万辆的宏大目标。同时,他们对“享界”首款产品的市场表现也充满信心,预计其月销量将突破1万辆大关。这次合作被视为双方共同发展的重要契机,双方将共同探索智能出行领域的创新模式,为消费者带来更加智能便捷的出行体验。这款车型被定位为行政轿车,内部定价在30-50万元之间,直接剑指
- 25分钟前 华为 北汽蓝谷 0
-
 正版软件
正版软件
- 新科技:RT-H胜过RT-2的最新研究成果
- 随着大型语言模型如GPT-4与机器人技术的结合日益紧密,人工智能正逐渐走向现实世界。因此,与具身智能相关的研究也引起越来越多的关注。在诸多研究项目中,谷歌的"RT"系列机器人一直处于前沿地位,这一趋势在近期开始加速(详见《大模型正在重构机器人,谷歌Deepmind如何定义未来的具身智能》)。去年7月,谷歌DeepMind推出了RT-2,这是全球第一个能够控制机器人进行视觉-语言-动作(VLA)交互的模型。只需用对话的方式下达指令,RT-2就能在大量图片中识别出霉霉,并将一罐可乐送到她手中。如今,这个机器人
- 40分钟前 谷歌 智能 研究 0
-
 正版软件
正版软件
- 微软发布详细的指南,教用户如何卸载OneDrive 在Windows 10/11
- 微软最近升级了Windows10/11操作系统中的OneDrive云服务,改进了云同步和订阅到期提醒等功能。对于那些不想使用OneDrive的用户,微软也提供了详细的卸载指南。微软在官方网站上发布了一份新的支持文档,指导用户如何关闭或卸载OneDrive。文档中明确指出了卸载步骤:用户只需点击“开始”按钮,在搜索框中输入“程序”,然后在结果列表中选择“添加或删除程序”。在“应用和功能”下,找到并选择“MicrosoftOneDrive”,然后点击“卸载”即可。如果系统要求输入管理员密码或进行确认,用户需按
- 55分钟前 微软 0
-
 正版软件
正版软件
- 探讨大型模型的融合策略
- 在以前的实践中,模型融合被广泛运用,尤其在判别模型中,它被认为是一种能够稳定提升性能的方法。然而,对于生成语言模型而言,由于其涉及解码过程,其运作方式并不像判别模型那样直截了当。另外,由于大模型的参数量增大,在参数规模更大的场景,简单的集成学习可以考量的方法相比低参数的机器学习更受限制,比如经典的stacking,boosting等方法,因为堆叠模型的参数问题,无法简单拓展。因此针对大模型的集成学习需要仔细考量。下面我们讲解五种基本的集成方法,分别是模型整合、概率集成、嫁接学习、众包投票、MOE。一、模型
- 1小时前 20:25 模型 场景 融合 0













