探讨大型模型的融合策略
 发布于2024-12-14 阅读(0)
发布于2024-12-14 阅读(0)
扫一扫,手机访问
在以前的实践中,模型融合被广泛运用,尤其在判别模型中,它被认为是一种能够稳定提升性能的方法。然而,对于生成语言模型而言,由于其涉及解码过程,其运作方式并不像判别模型那样直截了当。
另外,由于大模型的参数量增大,在参数规模更大的场景,简单的集成学习可以考量的方法相比低参数的机器学习更受限制,比如经典的stacking,boosting等方法,因为堆叠模型的参数问题,无法简单拓展。因此针对大模型的集成学习需要仔细考量。
下面我们讲解五种基本的集成方法,分别是 模型整合、概率集成、嫁接学习、众包投票、MOE。
一、模型整合
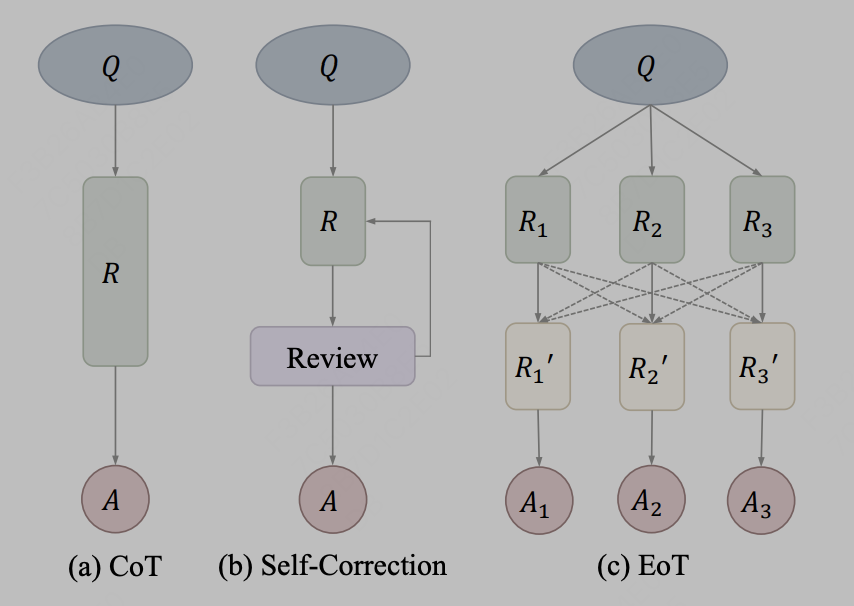
模型整合较为简单,即大模型在输出的文字层次进行融合,如简单的使用3个不同的LLama模型的输出结果,作为prompt输入到第四个模型中进行参考。在实际中,信息通过文字传递可以作为一种通信方法,其代表性的方法为EoT,来自于文章《Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communication》,EoT提出了一个新的思想交流框架,即“交换思想”(Exchange-of-Thought),旨在促进模型之间的交叉通信,以提升问题解决过程中的集体理解。通过这一框架,模型可以吸收其他模型的推理,从而更好地协调和改进自身的解决方案。用论文中的图示表示为:
 图片
图片
作者将CoT和自纠正方法视为同一概念后,EoT提供了一种新的方法,允许多个模型之间进行分层传递消息。通过跨模型通信,模型可以相互借鉴推理和思考过程,有助于更有效地解决问题。这种方法有望提升模型的性能和准确性。
二、概率集成
概率集成与传统的机器学习方法有着相似之处。例如,通过对模型预测的logit结果进行平均,可以形成一种集成方法。在大型模型中,概率集成可以在transformer模型的词表输出概率层次上进行融合。需要特别注意的是,这种操作要求融合的多个原始模型的词表必须保持一致。这样的集成方法可以提高模型的性能和鲁棒性,使其更适用于实际应用场景。
下面我们给出一个简单伪代码的实现。
kv_cache = NoneWhile True:input_ids = torch.tensor([[new_token]], dtype=torch.long, device='cuda')kv_cache1, kv_cache2 = kv_cache output1 = models[0](input_ids=input_ids, past_key_values=kv_cache1, use_cache=True)output2 = models[1](input_ids=input_ids, past_key_values=kv_cache2, use_cache=True)kv_cache = [output1.past_key_values, output2.past_key_values]prob = (output1.logits + output2.logits) / 2new_token = torch.argmax(prob, 0).item()
三、嫁接学习
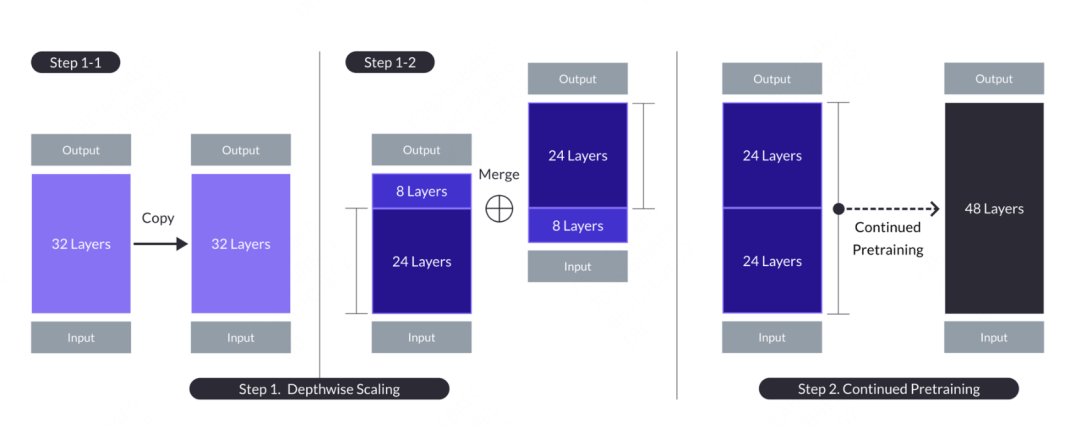
嫁接学习的概念来自于国内Kaggle Grandmaster的plantsgo,最早源自于数据挖掘竞赛。其本质上是一种迁移学习,一开始是用来描述将一个树模型的输出作为另一个树模型的输入的方法。此种方法与树的繁殖中的嫁接类似,故而得名。在大模型中,也有嫁接学习的应用,其模型名字为SOLAR,文章来源于 《SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling》,文中提出了一个模型嫁接的一种思路,与机器学习中的嫁接学习不同的是,大模型并不直接融合另外一个模型的概率结果,而是将其中的部分结构和权重嫁接到融合模型上,并经过一定的继续预训练过程,使其模型参数能够适应新的模型。具体的操作为,复制包含n层的基础模型,以便后续修改。然后,从原始模型中移除最后的m层,并从其副本中移除最初的m层,从而形成两个不同的n-m层模型。最后将这两个模型连接起来,形成一个具有2*(n-m)层的缩放模型。
当需要构建一个48层的目标模型时,可以考虑从两个32层的模型中各取前24层和后24层,将它们连接起来形成一个全新的48层模型。接着,对这个组合后的模型进行进一步的预训练。一般来说,继续预训练所需的数据量和计算资源要比从零开始训练要少。
 图片
图片
在继续预训练之后,还需要进行对齐操作,包含两个过程,分别是指令微调和DPO。指令微调采用开源instruct数据并改造出一个数学专用instruct数据,以增强模型的数学能力。DPO是传统的RLHF的替代,最终形成了SOLAR-chat版本。
四、众包投票
众包投票在今年的WSDM CUP第一名方案里上有所应用,在过往的国内生成比赛中大家也实践过。其核心思想是:如果一个模型生成的句子,与所有模型的结果最像,那这个句子可以认为是所有模型的平均。这样就把概率意义上的平均,变成了生成token结果的上的平均。假设给定一个测试样本,我们有个候选回答需要聚合,对于每一个候选,我们计算和)(之间的相关性分数并将它们加在一起作为的质量分数()。同样地,相关性量化来源可以是嵌入层余弦相似度(表示为emb_a_s)、词级ROUGE-L(表示为word_a_f)和字符级ROUGE-L(表示为char_a_f)。这里就是一些人工构造的相似度指标,包括字面上的和语义上的。
代码地址:https://github.com/zhangzhao219/WSDM-Cup-2024/tree/main
五、MoE
最后,也是最重要的大模型混合专家模型(Mixture of Experts,简称MoE),这是一种结合多个子模型(即“专家”)的模型架构方法,旨在通过多个专家的协同工作来提升整体的预测效果。MoE结构能够显著增强模型的处理能力和运行效率。典型的大模型MoE体系结构包含了一个门控机制(Gating Mechanism)和一系列专家网络。门控机制负责依据输入数据动态调配各个专家的权重,以此来决定每个专家对最终输出的贡献程度;同时,专家选择机制会根据门控信号的指示,挑选出一部分专家来参与实际的预测计算。这种设计不仅降低了整体的运算需求,还使得模型能够根据不同的输入选择最适用的专家。
混合专家模型(Mixture of Experts,MoE)并不是最近才有的新概念,混合专家模型的概念最早可以追溯到1991年发表的论文《Adaptive Mixture of Local Experts》。这种方法与集成学习有着相似之处,其核心是为由众多独立专家网络构成的集合体创立一个协调融合机制。在这样的架构下,每个独立的网络(即“专家”)负责处理数据集中的特定子集,并且专注于特定的输入数据区域。这个子集可能是偏向于某种话题,某种领域,某种问题分类等,并不是一个显示的概念。
面对不同的输入数据,一个关键的问题是系统如何决定由哪个专家来处理。门控网络(Gating Network)就是来解决这个问题的,它通过分配权重来确定各个专家的工作职责。在整个训练过程中,这些专家网络和门控网络会被同时训练,并不需要显示的手动操控。
在2010年至2015年这段时间里,有两个研究方向对混合专家模型(MoE)的进一步发展产生了重要影响:
组件化专家:在传统的MoE框架中,系统由一个门控网络和若干个专家网络构成。在支持向量机(SVM)、高斯过程以及其他机器学习方法的背景下,MoE常常被当作模型中的一个单独部分。然而,Eigen、Ranzato和Ilya等研究者提出了将MoE作为深层网络中一个内部组件的想法。这种创新使得MoE可以被整合进多层网络的特定位置中,从而使模型在变得更大的同时,也能保持高效。
条件计算:传统神经网络会在每一层对所有输入数据进行处理。在这段时期,Yoshua Bengio等学者开始研究一种基于输入特征动态激活或者禁用网络部分的方法。
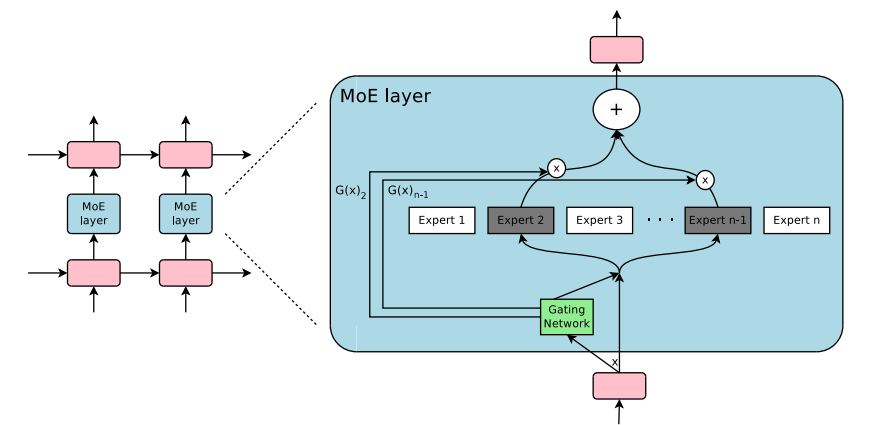
这两项研究的结合推动了混合专家模型在自然语言处理(NLP)领域的应用。尤其是在2017年,Shazeer和他的团队将这一理念应用于一个137亿参数的LSTM模型(这是当时在NLP领域广泛使用的一种模型架构,由Schmidhuber提出)。他们通过引入稀疏性来实现在保持模型规模巨大的同时,加快推理速度。这项工作主要应用于翻译任务,并且面对了包括高通信成本和训练稳定性问题在内的多个挑战。如图所示《Outrageously Large Neural Network》 中的MoE layer架构如下:
 图片
图片
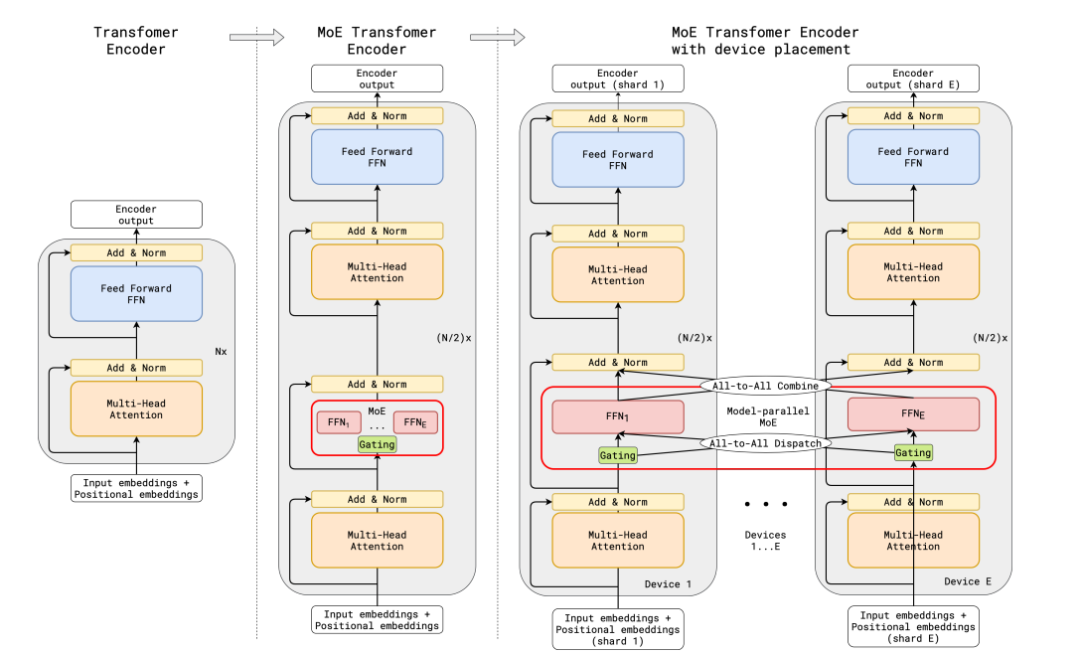
传统的MoE都集中在非transfomer的模型架构上,大模型时代的transfomer模型参数量达百亿级,如何在transformer上应用MoE并且把参数扩展到百亿级别,并且解决训练稳定性和推理效率的问题,成为MoE在大模型应用上的关键问题。谷歌提出了代表性的方法Gshard,成功将Transformer模型的参数量增加至超过六千亿,并以此提升模型水平。
在GShard框架下,编码器和解码器中的每个前馈网络(FFN)层被一种采用Top-2门控机制的混合专家模型(MoE)层所替代。下面的图示展现了编码器的结构设计。这样的设计对于执行大规模计算任务非常有利:当模型被分布到多个处理设备上时,MoE层在各个设备间进行共享,而其他层则在每个设备上独立复制。其架构如下图所示:
 图片
图片
为了确保训练过程中的负载均衡和效率,GShard提出了三种关键的技术,分别是损失函数,随机路由机制,专家容量限制。
辅助负载均衡损失函数:损失函数考量某个专家的buffer中已经存下的token数量,乘上某个专家的buffer中已经存下的token在该专家上的平均权重,构建这样的损失函数能让专家负载保持均衡。
随机路由机制:在Top-2的机制中,我们总是选择排名第一的专家,但是排名第二的专家则是通过其权重的比例来随机选择的。
专家容量限制:我们可以设置一个阈值来限定一个专家能够处理的token数量。如果两个专家的容量都已经达到了上限,那么令牌就会发生溢出,这时token会通过残差连接传递到下一层,或者在某些情况下被直接丢弃。专家容量是MoE架构中一个非常关键的概念,其存在的原因是所有的张量尺寸在编译时都已经静态确定,我们无法预知会有多少token分配给每个专家,因此需要预设一个固定的容量限制。
需要注意的是,在推理阶段,只有部分专家会被激活。同时,有些计算过程是被所有token共享的,比如自注意力(self-attention)机制。这就是我们能够用相当于12B参数的稠密模型计算资源来运行一个含有8个专家的47B参数模型的原因。如果我们使用Top-2门控机制,模型的参数量可以达到14B,但是由于自注意力操作是专家之间共享的,实际在模型运行时使用的参数量是12B。
整个MoeLayer的原理可以用如下伪代码表示:
M = input.shape[-1] # input维度为(seq_len, batch_size, M),M是注意力输出embedding的维度reshaped_input = input.reshape(-1, M)gates = softmax(einsum("SM, ME -> SE", reshaped_input, Wg)) #输入input,Wg是门控训练参数,维度为(M, E),E是MoE层中专家的数量,输出每个token被分配给每个专家的概率,维度为(S, E)combine_weights, dispatch_mask = Top2Gating(gates) #确定每个token最终分配给的前两位专家,返回相应的权重和掩码dispatched_expert_input = einsum("SEC, SM -> ECM", dispatch_mask, reshaped_input) # 对输入数据进行排序,按照专家的顺序排列,为分发到专家计算做矩阵形状整合h = enisum("ECM, EMH -> ECH", dispatched_expert_input, Wi) #各个专家计算分发过来的input,本质上是几个独立的全链接层h = relu(h)expert_outputs = enisum("ECH, EHM -> ECM", h, Wo) #各个专家的输出outputs = enisum("SEC, ECM -> SM", combine_weights, expert_outputs) #最后,进行加权计算,得到最终MoE-layer层的输出outputs_reshape = outputs.reshape(input.shape) # 从(S, M)变成(seq_len, batch_size, M)关于在MoE的架构改进上,Switch Transformers设计了一种特殊的Switch Transformer层,该层能够处理两个独立的输入(即两个不同的token),并配备了四个专家进行处理。与最初的top2专家的想法相反,Switch Transformers 采用了简化的top1专家策略。如下图所示:
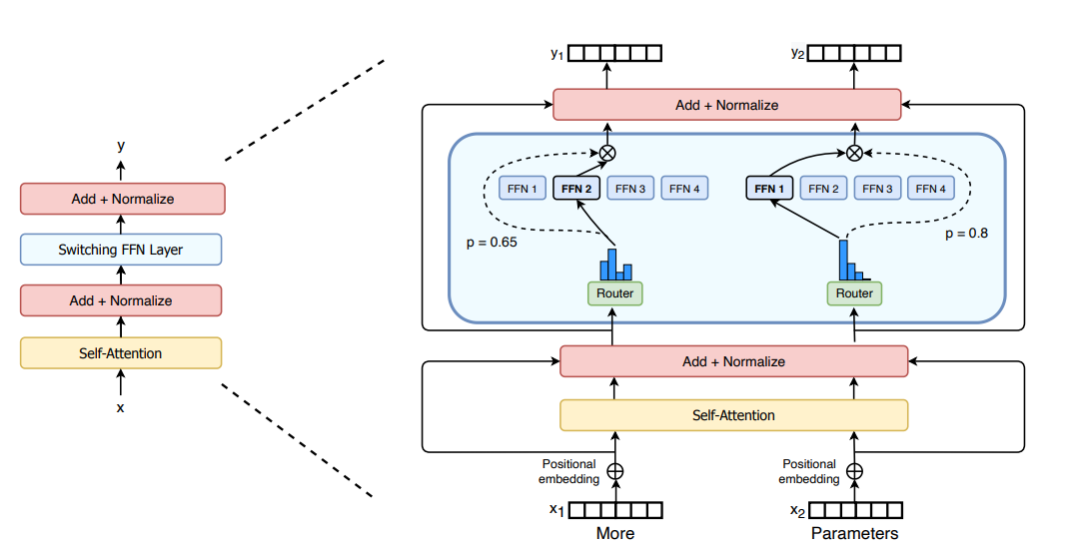 图片
图片
与之区别,国内知名大模型DeepSeek MoE的架构设计了一个共享专家,每次都参与激活,其设计基于这样一个前提:某个特定的专家能够精通特定的知识领域。通过将专家的知识领域进行细粒度的分割,可以防止单一专家需要掌握过多的知识面,从而避免知识的混杂。同时,设置共享专家能够确保一些普遍适用的知识在每次计算时都能被利用。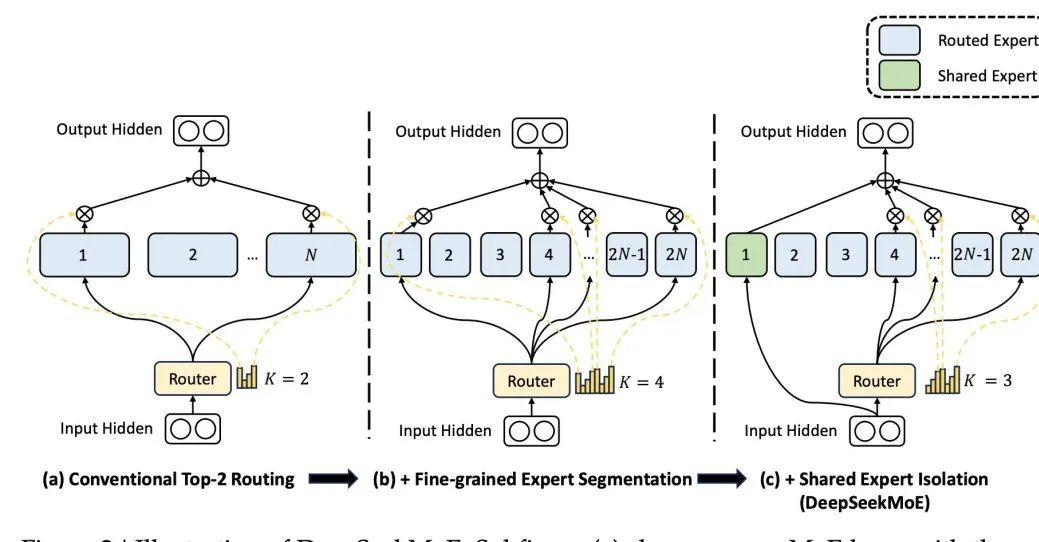 图片
图片
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 五菱扬光新能源商用车问世,宽敞车厢引领行业风向
- 五菱汽车官方公众号今日宣布,全新一代超大空间新能源商用车——五菱扬光正式上市,备受瞩目。新车凭借卓越的性能和先进技术,吸引了众多关注。五菱扬光提供了多种不同规格和价格选项,以满足不同消费者的需求。其中,230KM实用型售价为7.18万元,300KM实用型售价为7.98万元,而300KM舒适型售价为8.38万元。这种差异定价策略让五菱扬光在市场上具备了较强的竞争力,能够吸引不同群体的消费者。这种价格区分也显示了对消费者需求的深入了解,使得购买者可以根据自己的预算和需求选择最适合的车型。五菱扬光通过这种差异化
- 6分钟前 五菱汽车 0
-
 正版软件
正版软件
- 曝光苹果内部代号“一条面包”的个性化车型
- 据3月11日的报道,近期有国外媒体透露,苹果公司在2020年初曾组织了一次高层试驾活动。在亚利桑那州的阳光下,苹果的高管们体验了一款内部代号为“一条面包”的个性化原型车。这款车的设计独具特色,采用全玻璃车顶和侧滑门设计,呈现出现代感十足的风格。白色的轮胎则为整体增添了一抹亮丽的色彩。车厢内部参考了私人飞机的豪华内饰风格,配置了舒适的俱乐部座椅,乘客可以根据个人需求调整座椅的角度和位置,让乘坐者能够享受到家般的舒适体验。据了解,这款原型车的最引人关注之处在于其独特的设计理念。该车采用了一种全新的驾驶方式,摒
- 16分钟前 苹果 0
-
 正版软件
正版软件
- 陶哲轩的预言得到验证!AI解开椭圆曲线难题,华人数学家跻身千禧大奖之争
- 用AI研究数学领域,最近又有重大发现了。这次数学家们用AI发现的,是椭圆曲线中的murmuration(椋鸟群飞)现象。他们发现,如果以正确的方式观察,在椭圆曲线中会出现像飞行中的椋鸟群一般的图案。现在,murmuration相关研究已经轰动了数学圈,每周都有相关新研究问世。令人不可思议的是,这个发现是由数个偶然组成的——椭圆曲线的数据按照conductor排序,导致一个缺乏经验的本科生无意中遗漏了某个数值,进而使曲线的震荡变得明显。而那些提前预排序的数据集也被别人提前处理完毕,这一系列的巧合使得整个情况
- 31分钟前 模型 训练 0
-
 正版软件
正版软件
- 清华大学自然语言处理团队发布InfLLM:实现「1024K超长上下文」无需额外训练的100%召回率
- 大型模型仅能记忆和理解有限的上下文,这已成为它们在实际应用中的一大制约。例如,对话型人工智能系统常常无法持久记忆前一天的对话内容,这导致利用大型模型构建的智能体表现出前后不一致的行为和记忆。为了让大型模型能够更好地处理更长的上下文,研究人员提出了一种名为InfLLM的新方法。这一方法由清华大学、麻省理工学院和人民大学的研究人员联合提出,它能够使大型语言模型(LLM)无需额外的训练就能够处理超长文本。InfLLM利用了少量的计算资源和显存开销,从而实现了对超长文本的高效处理。论文地址:https://arx
- 1小时前 23:00 模型 AI 0
-
 正版软件
正版软件
- Pika发动技能:视频和音频一起处理!
- 就在刚刚,Pika发布了一项新功能:很抱歉我们之前一直处于静音状态。今天起,大家可以给视频无缝生成音效了——SoundEffects!生成的方式有两种:要么给一句Prompt,描述你想要的声音;要么直接让Pika根据视频内容自动生成。并且Pika非常自信地说到:“如果你觉得音效听起来很棒,那是因为它确实如此”。车鸣声、广播声、鹰叫声、刀剑声、欢呼声……可谓是声声不息,并且从效果上来看,也是高度与视频画面匹配。不仅是发布的宣传片,Pika官网现在也放出了多个demo。例如无需任何prompt,AI只是看了眼
- 1小时前 22:50 人工智能 机器学习 0













