新科技:RT-H胜过RT-2的最新研究成果
 发布于2024-12-14 阅读(0)
发布于2024-12-14 阅读(0)
扫一扫,手机访问
随着大型语言模型如GPT-4与机器人技术的结合日益紧密,人工智能正逐渐走向现实世界。因此,与具身智能相关的研究也引起越来越多的关注。在诸多研究项目中,谷歌的"RT"系列机器人一直处于前沿地位,这一趋势在近期开始加速(详见《大模型正在重构机器人,谷歌Deepmind如何定义未来的具身智能》)。

去年7月,谷歌DeepMind推出了RT-2,这是全球第一个能够控制机器人进行视觉-语言-动作(VLA)交互的模型。只需用对话的方式下达指令,RT-2就能在大量图片中识别出霉霉,并将一罐可乐送到她手中。
如今,这个机器人又进化了。最新版的 RT 机器人名叫「RT-H」,它能通过将复杂任务分解成简单的语言指令,再将这些指令转化为机器人行动,来提高任务执行的准确性和学习效率。举例来说,给定一项任务,如「盖上开心果罐的盖子」和场景图像,RT-H 会利用视觉语言模型(VLM)预测语言动作(motion),如「向前移动手臂」和「向右旋转手臂」,然后根据这些语言动作,预测机器人的行动(action)。

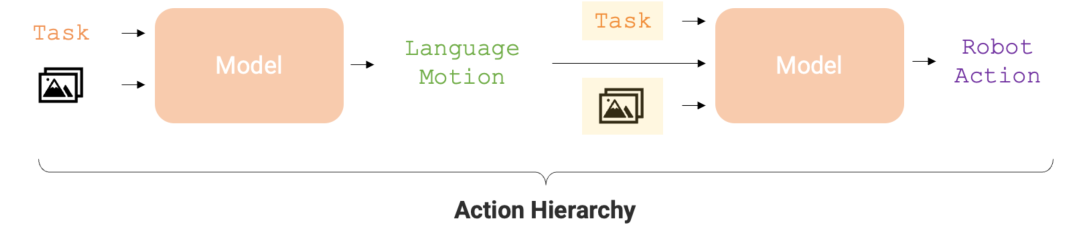
行动层级对于优化机器人任务执行的准确性和学习效率至关重要。这种层级结构使得 RT-H 在各种机器人任务中的表现明显优于 RT-2,为机器人提供了更为高效的执行路径。

以下是论文的详细信息。
论文概览

- 论文标题:RT-H: Action Hierarchies Using Language
- 论文链接:https://arxiv.org/pdf/2403.01823.pdf
- 项目链接:https://rt-hierarchy.github.io/
语言是人类推理的引擎,它使我们能够将复杂概念分解为更简单的组成部分,纠正我们的误解,并在新环境中推广概念。近年来,机器人也开始利用语言高效、组合式的结构来分解高层次概念、提供语言修正或实现在新环境下的泛化。
这些研究通常遵循一个共同的范式:面对一个用语言描述的高层任务(如「拿起可乐罐」),它们学习将观察和语言中的任务描述映射到低层次机器人行动的策略,这需要通过大规模多任务数据集实现。语言在这些场景中的优势在于编码类似任务之间的共享结构(例如,「拿起可乐罐」与「拿起苹果」),从而减少了学习从任务到行动映射所需的数据。然而,随着任务变得更加多样化,描述每个任务的语言也变得更加多样(例如,「拿起可乐罐」与「倒一杯水」),这使得仅通过高层次语言学习不同任务之间的共享结构变得更加困难。
为了学习多样化的任务,研究者的目标是更准确地捕捉这些任务之间的相似性。
他们发现语言不仅可以描述高层次任务,还能细致说明完成任务的方法 —— 这种表示更细腻,更贴近具体动作。例如,「拿起可乐罐」这一任务可以分解为一系列更细节的步骤,即「语言动作(language motion)」:首先「手臂向前伸」,接着「抓紧罐子」,最后「手臂上举」。研究者的核心洞见是,通过将语言动作作为连接高层次任务描述与底层次动作之间的中间层,可以利用它们来构建一个通过语言动作形成的行动层级。
建立这种行动层级有几大好处:
- 它使不同任务之间在语言动作层面上能够更好地共享数据,使得语言动作的组合和在多任务数据集中的泛化性得到增强。例如,「倒一杯水」与「拿起可乐罐」虽在语义上有所不同,但在执行到捡起物体之前,它们的语言动作完全一致。
- 语言动作不是简单的固定原语,而是根据当前任务和场景的具体情况通过指令和视觉观察来学习的。比如,「手臂向前伸」并没具体说明移动的速度或方向,这取决于具体任务和观察情况。学习到的语言动作的上下文依赖性和灵活性为我们提供了新的能力:当策略未能百分百成功时,允许人们对语言动作进行修正(见图 1 中橙色区域)。进一步地,机器人甚至可以从这些人类的修正中学习。例如,在执行「拿起可乐罐」的任务时,如果机器人提前关闭了夹爪,我们可以指导它「保持手臂前伸的姿势更久一些」,这种在特定场景下的微调不仅易于人类指导,也更易于机器人学习。

鉴于语言动作存在以上优势,来自谷歌 DeepMind 的研究者设计了一个端到端的框架 ——RT-H(Robot Transformer with Action Hierarchies,即使用行动层级的机器人 Transformer),专注于学习这类行动层级。RT-H 通过分析观察结果和高层次任务描述来预测当前的语言动作指令,从而在细节层面上理解如何执行任务。接着,利用这些观察、任务以及推断出的语言动作,RT-H 为每一步骤预测相应的行动,语言动作在此过程中提供额外的上下文,帮助更准确地预测具体行动(图 1 紫色区域)。
此外,他们还开发了一种自动化方法,从机器人的本体感受中提取简化的语言动作集,建立了包含超过 2500 个语言动作的丰富数据库,无需手动标注。
RT-H 的模型架构借鉴了 RT-2,后者是一个在互联网规模的视觉与语言数据上共同训练的大型视觉语言模型(VLM),旨在提升策略学习效果。RT-H 采用单一模型同时处理语言动作和行动查询,充分利用广泛的互联网规模知识,为行动层级的各个层次提供支持。
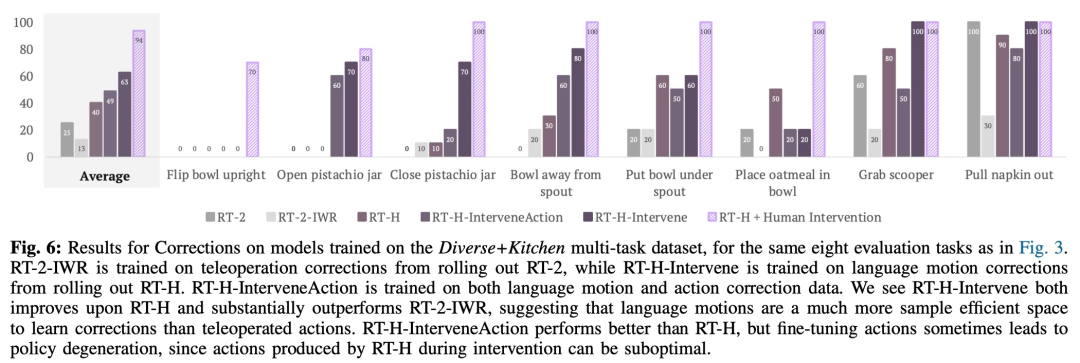
在实验中,研究者发现使用语言动作层级在处理多样化的多任务数据集时能够带来显著的改善,相比 RT-2 在一系列任务上的表现提高了 15%。他们还发现,对语言动作进行修正能够在同样的任务上达到接近完美的成功率,展示了学习到的语言动作的灵活性和情境适应性。此外,通过对模型进行语言动作干预的微调,其表现超过了 SOTA 交互式模仿学习方法(如 IWR)50%。最终,他们证明了 RT-H 中的语言动作能够更好地适应场景和物体变化,相比于 RT-2 展现出了更优的泛化性能。
RT-H 架构详解
为了有效地捕获跨多任务数据集的共享结构(不由高层次任务描述表征),RT-H 旨在学习显式利用行动层级策略。
具体来说,研究团队将中间语言动作预测层引入策略学习中。描述机器人细粒度行为的语言动作可以从多任务数据集中捕获有用的信息,并可以产生高性能的策略。当学习到的策略难以执行时,语言动作可以再次发挥作用:它们为与给定场景相关的在线人工修正提供了直观的界面。经过语言动作训练的策略可以自然地遵循低水平的人工修正,并在给定修正数据的情况下成功完成任务。此外,该策略甚至可以根据语言修正数据进行训练,并进一步提高其性能。
如图 2 所示,RT-H 有两个关键阶段:首先根据任务描述和视觉观察预测语言动作,然后根据预测的语言动作、具体任务、观察结果推断精确的行动。
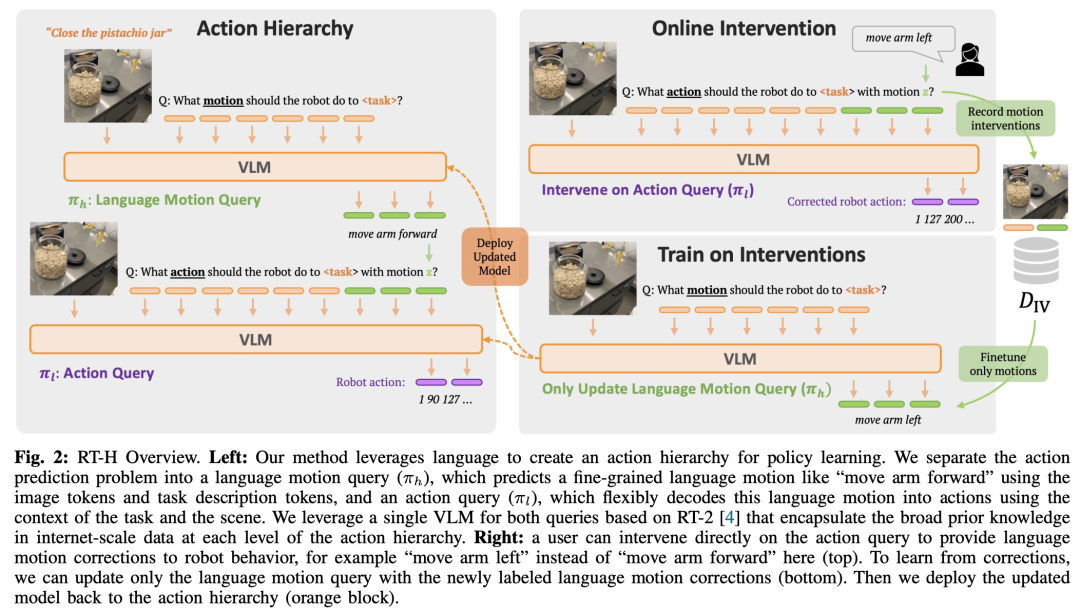
RT-H 使用 VLM 主干网络并遵循 RT-2 的训练过程来进行实例化。与 RT-2 类似,RT-H 通过协同训练利用了互联网规模数据中自然语言和图像处理方面的大量先验知识。为了将这些先验知识合并到行动层级的所有层次中,单个模型会同时学习语言动作和行动查询。
实验结果
为了全面评估 RT-H 的性能,研究团队设置了四个关键的实验问题:
- Q1(性能):带有语言的行动层级是否可以提高多任务数据集上的策略性能?
- Q2(情境性):RT-H 学得的语言动作是否与任务和场景情境相关?
- Q3(纠正):在语言动作修正上进行训练比远程(teleoperated)修正更好吗?
- Q4(概括):行动层级是否可以提高分布外设置的稳健性?
数据集方面,该研究采用一个大型多任务数据集,其中包含 10 万个具有随机对象姿态和背景的演示样本。该数据集结合了以下数据集:
- Kitchen:RT-1 和 RT-2 使用的数据集,由 70K 样本中的 6 个语义任务类别组成。
- Diverse:一个由更复杂的任务组成的新数据集,具有超过 24 个语义任务类别,但只有 30K 样本。
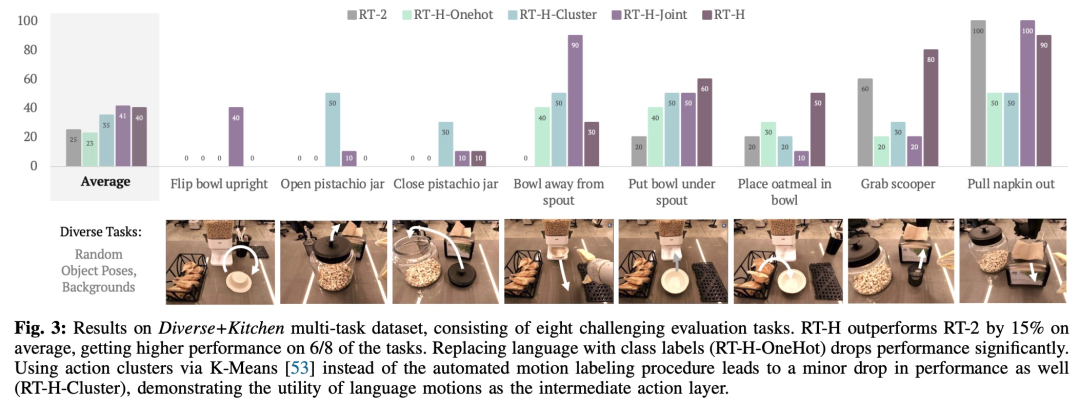
该研究将此组合数据集称为 Diverse+Kitchen (D+K) 数据集,并使用自动化程序对其进行语言动作标记。为了评估在完整 Diverse+Kitchen 数据集上训练的 RT-H 的性能,该研究针对八项具体任务进行了评估,包括:
1)将碗直立放在柜台上
2)打开开心果罐
3)关闭开心果罐
4)将碗移离谷物分配器
5)将碗放在谷物分配器下方
6)将燕麦片放入碗中
7)从篮子里拿勺子
8)从分配器中拉出餐巾
选择这八个任务是因为它们需要复杂的动作序列和高精度。
下表给出了在 Diverse+Kitchen 数据集或 Kitchen 数据集上训练时 RT-H、RT-H-Joint 和 RT-2 训练检查点的最小 MSE。RT-H 的 MSE 比 RT-2 低大约 20%,RTH-Joint 的 MSE 比 RT-2 低 5-10%,这表明行动层级有助于改进大型多任务数据集中的离线行动预测。RT-H (GT) 使用 ground truth MSE 指标,与端到端 MSE 的差距为 40%,这说明正确标记的语言动作对于预测行动具有很高的信息价值。
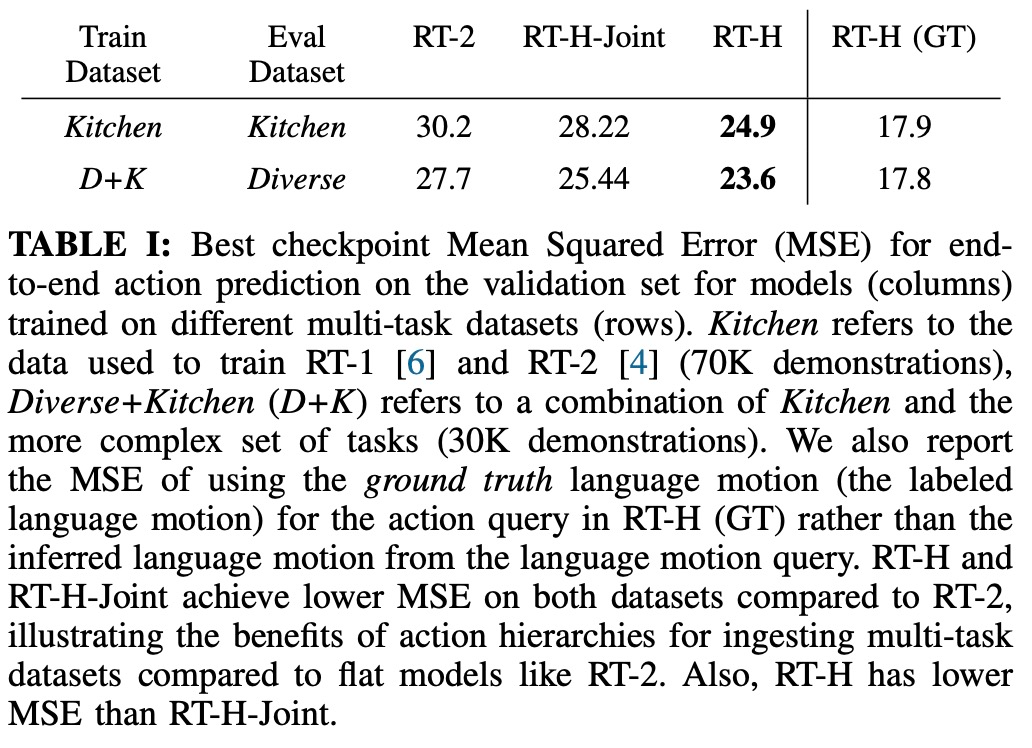
图 4 展示了几个从 RT-H 在线评估中获取的上下文动作示例。可以看到,相同的语言动作通常会导致完成任务的行动发生微妙的变化,同时仍尊重更高级别的语言动作。

如图 5 所示,研究团队通过在线干预 RT-H 中的语言动作来展示 RT-H 的灵活性。

该研究还用比较实验来分析修正的作用,结果如下图 6 所示:
如图 7 所示,RT-H 和 RT-H-Joint 对场景变化明显更加稳健:
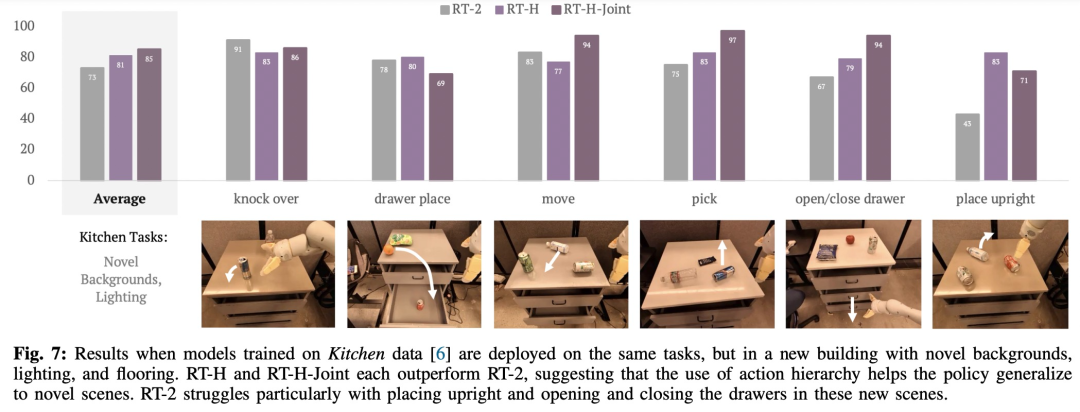
实际上,看似不同的任务之间具备一些共享结构,例如这些任务中每一个都需要一些拾取行为来开始任务,并且通过学习跨不同任务的语言动作的共享结构,RT-H 可以完成拾取阶段而无需任何修正。

即使当 RT-H 不再能够泛化其语言动作预测时,语言动作修正通常也可以泛化,因此只需进行一些修正就可以成功完成任务。这表明语言动作在扩大新任务数据收集方面的潜力。
感兴趣的读者可以阅读论文原文,了解更多研究内容。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 特斯拉开发延长充电线,适用于各种充电口位置的汽车
- 特斯拉最近宣布,他们正在研发适用于不同充电口位置的汽车的充电延长线,以支持NACS至NACS标准。特斯拉的超级充电站网络原本主要为特斯拉自家车型设计,这些车型的充电口统一位于驾驶员侧后部。然而,自从特斯拉决定向非特斯拉电动车开放超级充电站以来,一些问题逐渐浮现。因为许多其他品牌的电动汽车充电口位置与特斯拉不同,有的位于车头,有的则位于驾驶员侧前部,这导致车主在使用特斯拉充电站时需要调整停车位置。特斯拉目前正在努力解决充电线长度不足的问题,他们计划推出符合NACS至NACS标准的延长线,以便各种充电口位置的
- 9分钟前 特斯拉 0
-
 正版软件
正版软件
- 五菱扬光新能源商用车问世,宽敞车厢引领行业风向
- 五菱汽车官方公众号今日宣布,全新一代超大空间新能源商用车——五菱扬光正式上市,备受瞩目。新车凭借卓越的性能和先进技术,吸引了众多关注。五菱扬光提供了多种不同规格和价格选项,以满足不同消费者的需求。其中,230KM实用型售价为7.18万元,300KM实用型售价为7.98万元,而300KM舒适型售价为8.38万元。这种差异定价策略让五菱扬光在市场上具备了较强的竞争力,能够吸引不同群体的消费者。这种价格区分也显示了对消费者需求的深入了解,使得购买者可以根据自己的预算和需求选择最适合的车型。五菱扬光通过这种差异化
- 14分钟前 五菱汽车 0
-
 正版软件
正版软件
- 曝光苹果内部代号“一条面包”的个性化车型
- 据3月11日的报道,近期有国外媒体透露,苹果公司在2020年初曾组织了一次高层试驾活动。在亚利桑那州的阳光下,苹果的高管们体验了一款内部代号为“一条面包”的个性化原型车。这款车的设计独具特色,采用全玻璃车顶和侧滑门设计,呈现出现代感十足的风格。白色的轮胎则为整体增添了一抹亮丽的色彩。车厢内部参考了私人飞机的豪华内饰风格,配置了舒适的俱乐部座椅,乘客可以根据个人需求调整座椅的角度和位置,让乘坐者能够享受到家般的舒适体验。据了解,这款原型车的最引人关注之处在于其独特的设计理念。该车采用了一种全新的驾驶方式,摒
- 29分钟前 苹果 0
-
 正版软件
正版软件
- 陶哲轩的预言得到验证!AI解开椭圆曲线难题,华人数学家跻身千禧大奖之争
- 用AI研究数学领域,最近又有重大发现了。这次数学家们用AI发现的,是椭圆曲线中的murmuration(椋鸟群飞)现象。他们发现,如果以正确的方式观察,在椭圆曲线中会出现像飞行中的椋鸟群一般的图案。现在,murmuration相关研究已经轰动了数学圈,每周都有相关新研究问世。令人不可思议的是,这个发现是由数个偶然组成的——椭圆曲线的数据按照conductor排序,导致一个缺乏经验的本科生无意中遗漏了某个数值,进而使曲线的震荡变得明显。而那些提前预排序的数据集也被别人提前处理完毕,这一系列的巧合使得整个情况
- 44分钟前 模型 训练 0
-
 正版软件
正版软件
- 清华大学自然语言处理团队发布InfLLM:实现「1024K超长上下文」无需额外训练的100%召回率
- 大型模型仅能记忆和理解有限的上下文,这已成为它们在实际应用中的一大制约。例如,对话型人工智能系统常常无法持久记忆前一天的对话内容,这导致利用大型模型构建的智能体表现出前后不一致的行为和记忆。为了让大型模型能够更好地处理更长的上下文,研究人员提出了一种名为InfLLM的新方法。这一方法由清华大学、麻省理工学院和人民大学的研究人员联合提出,它能够使大型语言模型(LLM)无需额外的训练就能够处理超长文本。InfLLM利用了少量的计算资源和显存开销,从而实现了对超长文本的高效处理。论文地址:https://arx
- 1小时前 23:00 模型 AI 0













