清华大学自然语言处理团队发布InfLLM:实现「1024K超长上下文」无需额外训练的100%召回率
 发布于2024-12-14 阅读(0)
发布于2024-12-14 阅读(0)
扫一扫,手机访问
大型模型仅能记忆和理解有限的上下文,这已成为它们在实际应用中的一大制约。例如,对话型人工智能系统常常无法持久记忆前一天的对话内容,这导致利用大型模型构建的智能体表现出前后不一致的行为和记忆。
为了让大型模型能够更好地处理更长的上下文,研究人员提出了一种名为InfLLM的新方法。这一方法由清华大学、麻省理工学院和人民大学的研究人员联合提出,它能够使大型语言模型(LLM)无需额外的训练就能够处理超长文本。InfLLM利用了少量的计算资源和显存开销,从而实现了对超长文本的高效处理。

论文地址:https://arxiv.org/abs/2402.04617
代码仓库:https://github.com/thunlp/InfLLM
实验结果表明,InfLLM能够有效地扩展Mistral、LLaMA的上下文处理窗口,并在1024K上下文的海底捞针任务中实现100%召回。
研究背景
大规模预训练语言模型(LLMs)近几年在众多任务上取得了突破性的进展,成为众多应用的基础模型。
这些实际应用也对LLMs处理长序列的能力提出了更高的挑战。例如,LLM驱动的智能体需要持续处理从外部环境接收的信息,这要求它具备更强的记忆能力。同时,对话式人工智能需要更好地记住与用户的对话内容,以便生成更个性化的回答。
然而,目前的大型模型通常只在包含数千个Token的序列上进行预训练,这导致将它们应用于超长文本时面临两大挑战:
1. 分布外长度:直接将LLMs应用到更长长度的文本中,往往需要LLMs处理超过训练范围的位置编码,从而造成Out-of-Distribution问题,无法泛化;
2. 注意力干扰:过长的上下文将使模型注意力被过度分散到无关的信息中,从而无法有效建模上下文中远距离语义依赖。
方法介绍
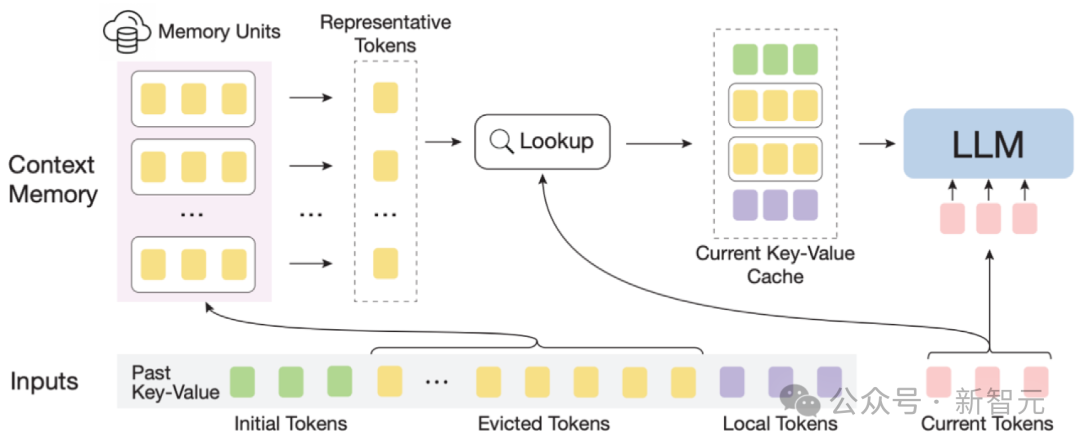
InfLLM示意图
为了高效地实现大模型的长度泛化能力,作者提出了一种无需训练的记忆增强方法,InfLLM,用于流式地处理超长序列。
InfLLM旨在激发LLMs的内在能力,以有限的计算成本捕获超长上下文中的长距离语义依赖关系,从而实现高效的长文本理解。
整体框架:考虑到长文本注意力的稀疏性,处理每个Token通常只需要其上下文的一小部分。
作者构建了一个外部记忆模块,用于存储超长上下文信息;采用滑动窗口机制,每个计算步骤,只有与当前Token距离相近的Tokens(Local Tokens)和外部记忆模块中的少量相关信息参与到注意力层的计算中,而忽略其他不相关的噪声。
因此,LLMs可以使用有限的窗口大小来理解整个长序列,并避免引入噪声。
然而,超长序列中的海量上下文对于记忆模块中有效的相关信息定位和记忆查找效率带来了重大挑战。
为了应对这些挑战,上下文记忆模块中每个记忆单元由一个语义块构成,一个语义块由连续的若干Token构成。
具体而言, (1)为了有效定位相关记忆单元,每个语义块的连贯语义比碎片化的Token更能有效满足相关信息查询的需求。
此外,作者从每个语义块中选择语义上最重要的Token,即接收到注意力分数最高的Token,作为语义块的表示,这种方法有助于避免在相关性计算中不重要Token的干扰。
(2)为了高效的内存查找,语义块级别的记忆单元避免了逐Token,逐注意力的相关性计算,降低了计算复杂性。
此外,语义块级别的记忆单元确保了连续的内存访问,并减少了内存加载成本。
得益于此,作者设计了一种针对上下文记忆模块的高效卸载机制(Offloading)。
考虑到大多数记忆单元的使用频率不高,InfLLM将所有记忆单元卸载到CPU内存上,并动态保留频繁使用的记忆单元放在GPU显存中,从而显著减少了显存使用量。
可以将InfLLM总结为:
1. 在滑动窗口的基础上,加入远距离的上下文记忆模块。
2. 将历史上下文切分成语义块,构成上下文记忆模块中的记忆单元。每个记忆单元通过其在之前注意力计算中的注意力分数确定代表性Token,作为记忆单元的表示。从而避免上下文中的噪音干扰,并降低记忆查询复杂度
实验分析
作者在 Mistral-7b-Inst-v0.2(32K) 和 Vicuna-7b-v1.5(4K)模型上应用 InfLLM,分别使用4K和2K的局部窗口大小。
与原始模型、位置编码内插、Infinite-LM以及StreamingLLM进行比较,在长文本数据 Infinite-Bench 和 Longbench 上取得了显著的效果提升。
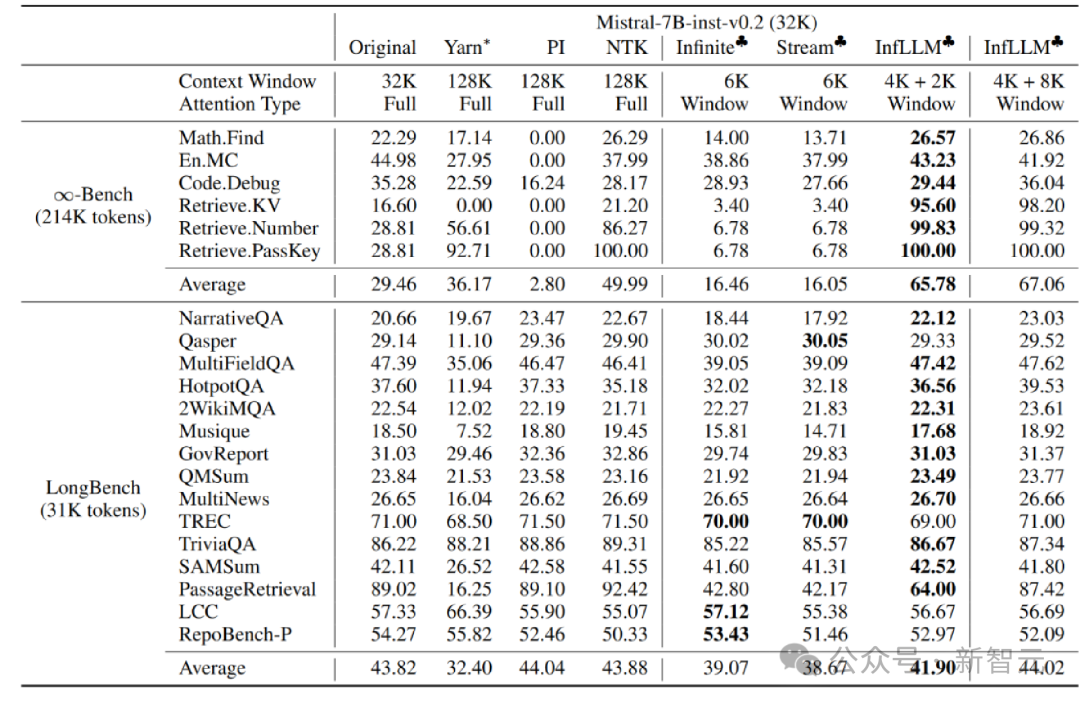
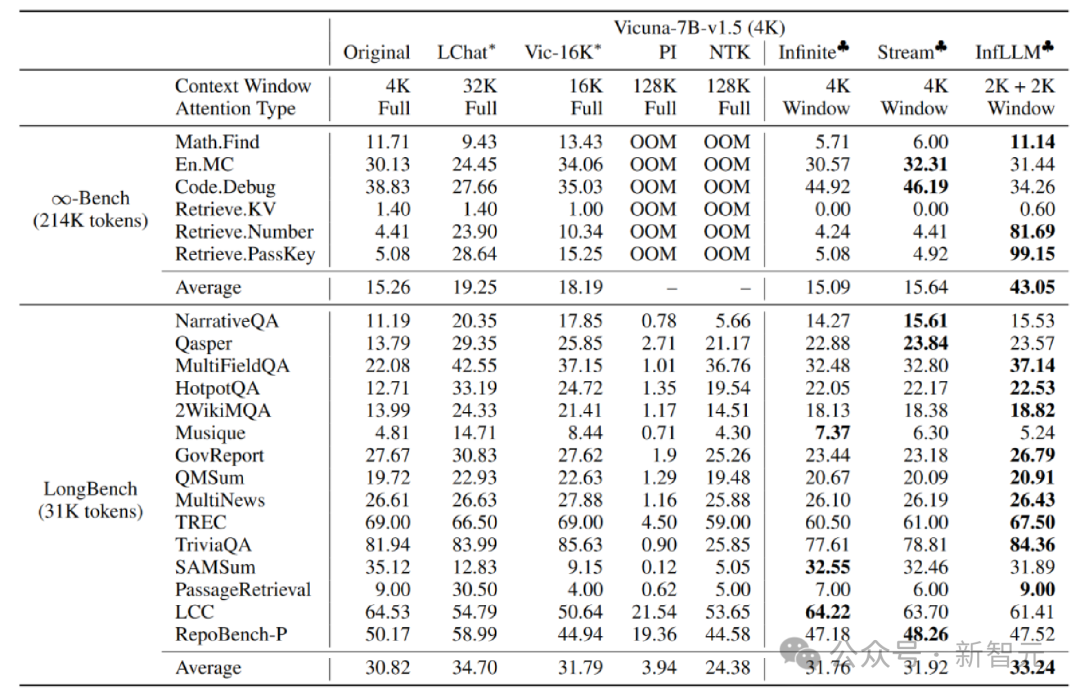
超长文本实验
此外,作者继续探索了 InfLLM 在更长文本上的泛化能力,在 1024K 长度的「海底捞针」任务中仍能保持 100% 的召回率。
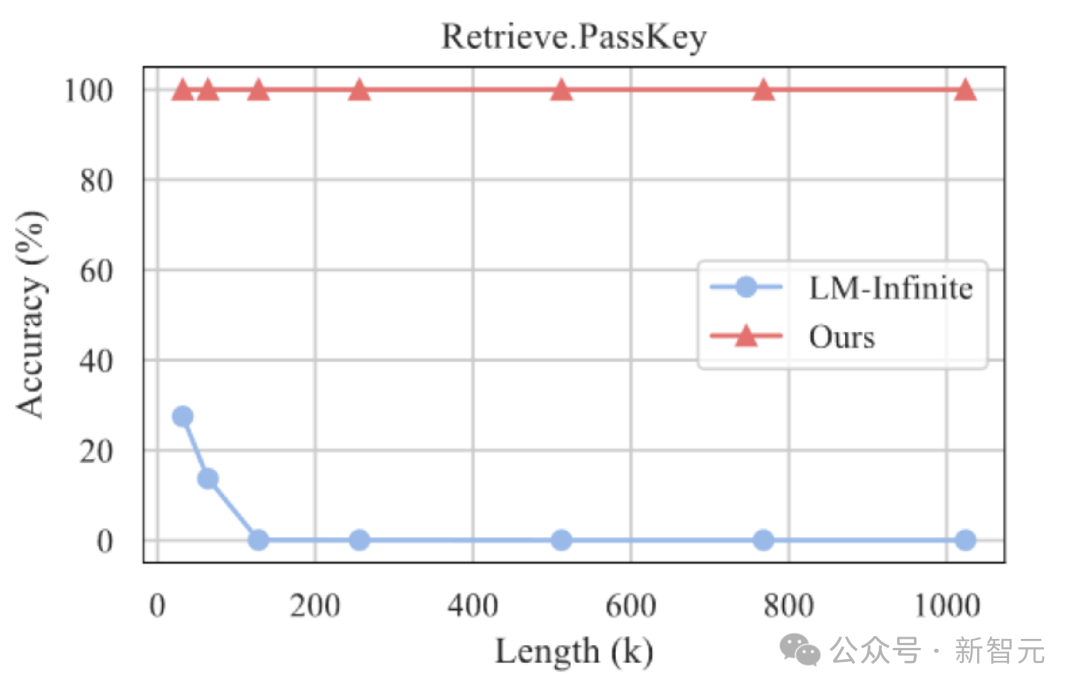
海底捞针实验结果
总结
在本文中,团队提出了 InfLLM,无需训练即可实现 LLM 的超长文本处理拓展,并可以捕捉到长距离的语义信息。
InfLLM 在滑动窗口的基础上,增加了包含长距离上下文信息的记忆模块,并使用缓存和offload 机制实现了少量计算和显存消耗的流式长文本推理。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 理想汽车推出全新升级计划,享受5年无忧用车服务的MEGA用户
- 理想汽车宣布旗下备受期待的新车型——理想MEGA,已开始交付。根据官方消息,为了满足用户需求并提升用车体验,理想汽车根据用户反馈制定了一系列升级方案。在充电设施方面,理想汽车已经成功投入使用351座超充站,共计1518个充电桩,这些设施主要布局在高速公路服务区。然而,理想汽车并不满足于此,他们计划进一步加大对城市超充站的投资。预计到今年年底,理想汽车将在全国范围内建成2700座超充站,配备20,000个充电桩。其中,城市地区将拥有2000座超充站和17,000个充电桩,实现一、二、三线城市超过60%的城区
- 10分钟前 理想汽车 0
-
 正版软件
正版软件
- 一加 Nord CE4 印度发布会日期确定,搭载强劲的骁龙7 Gen3,性能大幅提升
- 据消息,一加手机官方今日宣布,备受期待的中端机型一加NordCE4将于4月1日在印度市场正式发布。新机延续上一代经典设计,同时在细节上进行了巧妙的调整和创新。一加NordCE4在外观上延续了上一代的经典设计元素,但也在一些细节上进行了精心的改动。最引人注目的是,闪光灯模组被巧妙地调整至摄像头下方,并采用了圆形设计,这一变化使得整体造型更加和谐而富有新意。此外,新机在顶部保留了红外遥控发射器,这一贴心设计将为用户带来更多实用的遥控功能。一加NordCE4将采用全新的骁龙7Gen3处理器,相较于之前的骁龙78
- 15分钟前 一加 0
-
 正版软件
正版软件
- 五种数据存储方式受人工智能影响
- 人工智能(AI)的兴起已经颠覆了技术领域的传统游戏规则,对各行各业产生了深远影响。特别是在数据存储方面,人工智能的发展引领着一场革命,重新定义了数据的存储和管理方式。数据作为任何业务的关键资产,其价值和影响不言而喻,而人工智能的介入则在如何管理和保护这些数据方面发挥着至关重要的作用。本文旨在探讨人工智能如何重塑数据管理和存储领域的关键方面,以应对不断增长的数据需求和挑战。人工智能对存储系统的优化至关重要,它通过智能化的数据处理和分析,提升了存储系统的性能和效率。更重要的是,人工智能技术的引入为安全性、效率
- 30分钟前 人工智能 存储 数据存储 0
-
 正版软件
正版软件
- 利用Vision Pro在实时模式下训练机器狗!MIT博士生的开源项目备受关注
- VisionPro又现火爆新玩法,这回还和具身智能联动了~就像这样,MIT小哥利用VisionPro的手部追踪功能,成功实现了对机器狗的实时控制。不仅开门这样的动作能精准get:也几乎没什么延时。Demo一出,不仅网友们大赞鹅妹子嘤,各路具身智能研究人员也嗨了。比如这位准清华叉院博士生:还有人大胆预测:这就是我们与下一代机器互动的方式。项目如何实现,作者小哥朴英孝(YounghyoPark)已经在GitHub上开源。相关App可以直接在VisionPro的AppStore上下载。用VisionPro训练机
- 45分钟前 训练 机器狗 0
-
 正版软件
正版软件
- 黑鲨外设 2024 春季新品发布会将于 3 月 25 日举行,口号为“旗舰跃迁”
- 本站3月11日消息,黑鲨虽然许久未发布手机新品,但还是推出了不少外设产品。黑鲨外设2024春季新品发布会定档3月25日20:00,口号为“旗舰跃迁”。从官方预热来看,预计将推出新的旗舰外设产品。京东手机通讯官方微博则表示“省流:散热器”。目前尚不清楚新品的具体信息,本站将跟进黑鲨外设2024春季新品发布会相关内容。对于外界有关“黑鲨迟迟没有手机新品”的质疑,黑鲨此前表示:现在的我们,经过反复捶打,骨子里是硬的,是掰不断的,手表、耳机、手柄乃至其他产品,都是黑鲨一步步地自我拯救,正因如此,黑鲨才能继续站在这
- 1小时前 01:55 黑鲨 外设 0













