微软基于AI的新电子结构计算框架在Nature子刊发表
 发布于2024-12-15 阅读(0)
发布于2024-12-15 阅读(0)
扫一扫,手机访问
编辑 | ScienceAI
编者按:为了使电子结构方法突破当前广泛应用的密度泛函理论(KSDFT)所能求解的分子体系规模,微软研究院科学智能中心的研究员们基于人工智能技术和无轨道密度泛函理论(OFDFT)开发了一种新的电子结构计算框架M-OFDFT。这一框架不仅保持了与KSDFT相当的计算精度,而且在计算效率上实现了显著提升,并展现了优异的外推性能,为分子科学研究中诸多计算方法的基础——电子结构方法开辟了新的思路。相关研究成果已在国际知名学术期刊《自然-计算科学》(Nature Computational Science)上发表。
然而,各种电子结构方法的精度和计算效率通常很难达到平衡。目前,Kohn-Sham形式的密度泛函理论(Kohn-Sham density functional theory, KSDFT)被广泛应用,因为它在精度和效率之间取得了相对合理的平衡。不过,KSDFT仍然存在较高的计算复杂度,这使其无法很好地应对不断增长的求解大规模分子体系的需求。
微软研究院科学智能中心的研究员们提出了一种基于深度学习和无轨道密度泛函理论(OFDFT)的电子结构计算框架M-OFDFT。这一框架不仅在计算效率方面取得显著突破,同时也保持了高精度的计算解决能力。该成果突显了人工智能在提升电子结构计算中精度和效率的平衡方面的独特潜力。这一新框架有望加速相关行业问题的研究与开发进程。
M-OFDFT的相关研究成果以「Ovecoming the Barrier of Orbital-Free Density Functional Theory for Molecular Systems Using Deep Learning」为题,于 2024 年 3 月 11 日发表在国际知名学术期刊《自然-计算科学》(Nature Computational Science)上。

人工智能给电子结构方法带来新机会
电子结构方法是研究分子体系物理化学性质的基本工具。由于多电子体系的复杂性,高精度的电子结构方法往往计算代价较高,难以在工业界应用。为了处理较大分子系统,通常引入了一些近似,从而牺牲了一定的精度。目前,KSDFT方法在精度和效率方面取得了平衡,因此被广泛应用。
不过,近期人工智能技术的喜人进展也为其他电子结构计算框架带来了新的机会。为了使电子结构方法突破KSDFT所能求解的分子体系规模,微软研究院的研究员们利用人工智能技术,开发了M-OFDFT,该方法比KSDFT效率更高,同时又能保有其精度。基于OFDFT的开发,让M-OFDFT成为了一种比KSDFT理论复杂度更低的电子结构计算框架,因为它只需优化电子密度函数这一个函数来求解电子状态即可,KSDFT则需要优化与电子数相同的多个函数。
然而,OFDFT仍然面临着一个巨大的挑战——需要关于密度函数的电子动能泛函,但其确切形式尚不明确,并且构建适用于分子体系的高精度近似方法也相当困难。
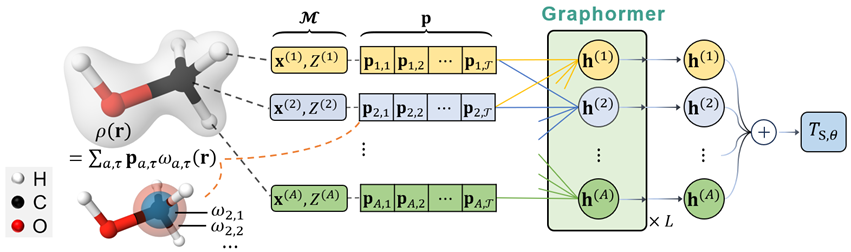
针对这一难题,M-OFDFT使用一个深度学习模型来近似动能泛函。借助深度学习模型的强大拟合能力,M-OFDFT可实现比基于近似物理模型设计的经典动能泛函更高的准确度。对于一个待求解的分子体系结构,M-OFDFT会使用动能泛函模型以及其他可直接计算的能量项构造出一个电子密度的优化目标,然后通过优化过程求解最优(基态)电子密度(图1),进而可计算能量、力、电荷分布等分子属性。
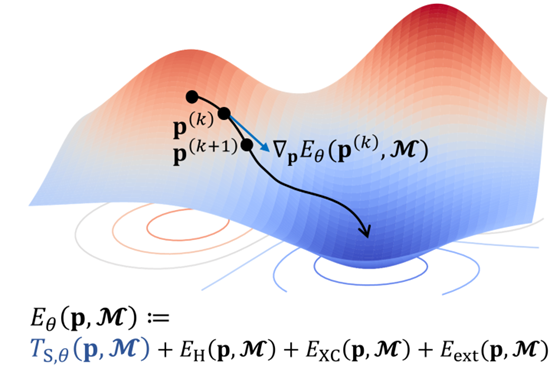
图1:对于待求解的分子体系结构,M-OFDFT通过最小化电子能量来求解电子密度(以其向量化系数表示),其中难以近似的动能部分由深度学习模型来近似。
M-OFDFT实现兼具精度与效率的电子结构方法
研究员们对M-OFDFT进行了一系列的实验验证。首先考察的是M-OFDFT在常见小分子体系上的求解精度。
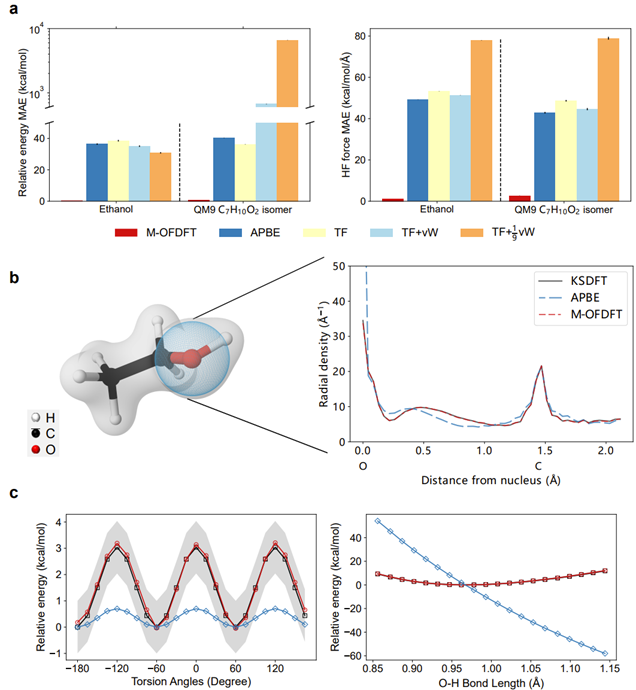
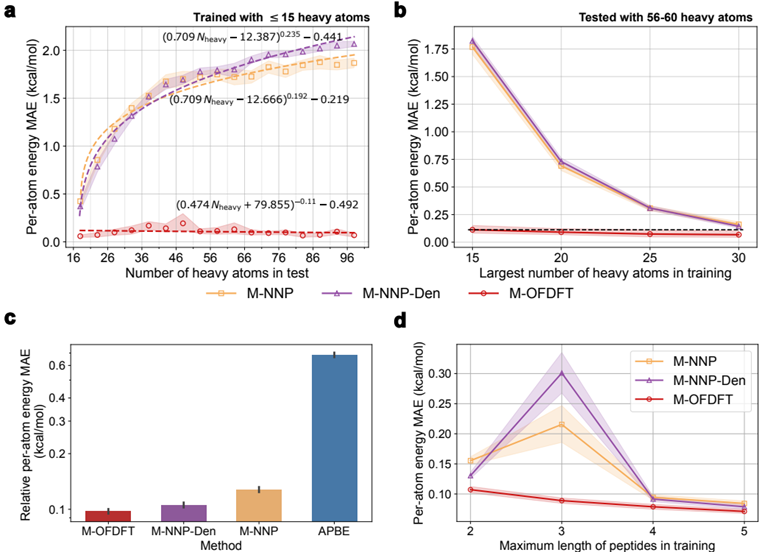
结果显示,M-OFDFT在乙醇分子构象以及QM9数据集的分子上可以达到与KSDFT相当的精度(能量达到化学精度1 kcal/mol)。相较于经典OFDFT方法,精度提高了两个数量级(图2-a)。M-OFDFT解得的电子密度也与KSDFT的结果重合(图2-b),特别是得到了电子壳层结构,而经典OFDFT的结果则有明显偏差。由M-OFDFT解得的乙醇构象空间上的势能面(每个点都是通过密度优化得到的,并不是直接预测)也与KSDFT的结果一致(图2-c)。
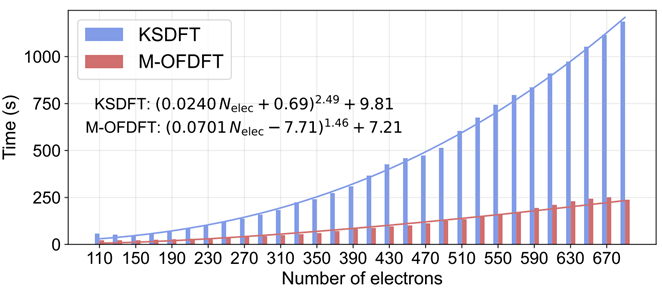
之后,研究员们又验证了M-OFDFT不仅保有KSDFT级别的精度,其更低的理论计算复杂度还使其在效率上也超越了KSDFT。在实际计算中M-OFDFT取得了的复杂度(图3),比KSDFT 的实际复杂度低了一阶,且其所需绝对时间也明显少于KSDFT。在两个更大的蛋白质体系上(包含2676和2750个电子),M-OFDFT实现了25.6倍和27.4倍的加速。
M-OFDFT具有更强的泛化能力
深度学习模型在科学任务中的应用面临一大挑战是,在具有与训练数据不同特点的数据上的泛化问题。但采用了OFDFT框架后,动能泛函模型遇到的泛化问题就会减轻,从而使 M-OFDFT可以在比训练集分子规模更大的体系上展现出良好的外推能力。
实验结果表明,M-OFDFT的能量预测误差显著低于基于深度学习的端到端能量预测模型(图4-a)。此外,研究员们还利用在多肽片段上训练的M-OFDFT模型求解完整蛋白结构,并取得了超越端到端模型和经典OFDFT的泛化性能(图4-c)。不仅如此,相较端到端模型,M-OFDFT还可以用更少的大分子体系训练数据取得更好的泛化表现(图4-b与图4-d)。
M-OFDFT的工作原理
「神龙见首又见尾」:高效捕获非局域效应的动能泛函模型
动能密度泛函具有明显的非局域效应,而用经典的基于格点(grid)的方式表征电子密度则会带来高昂的非局域计算代价。为此,M-OFDFT将电子密度在一组原子基组函数上展开,并使用展开系数作为电子密度表征。由于基函数叠加的形状与电子分布接近,所以其数量可远小于格点数,使得非局域计算代价大大降低,并有助于刻画电子密度中的壳层结构。
M-OFDFT将每个原子上的电子密度系数和类型与坐标作为节点特征,并基于Graphormer模型 [1]预测电子动能(图5),其自注意力机制显式刻画了荷载在每两个原子上的电子密度特征之间的相互作用,从而可捕捉非局域性质。此外,为了保证动能的旋转不变性,M-OFDFT使用了以各个原子为中心、基于其相邻原子的局部坐标系,将电子密度系数转换为旋转不变的特征。
「横看成岭侧成峰,远近高低各不同」:高效学习电子能量曲面的训练策略
与传统机器学习任务不同,动能泛函模型是被当作其输入变量的优化目标使用的,而非用于在一些单点上做预测,这对模型的学习提出了更高的要求:模型必须捕捉到每个分子结构上电子能量曲面的轮廓。
为此,研究员们深入分析了用来生成数据的电子结构方法,发现它其实可以为每个分子结构生成多个数据点,而且还能提供梯度标注,从而让模型可以拥有更丰富的曲面轮廓特征。然而梯度的巨大范围也使神经网络难以优化。对此,研究员们还提出了一系列增强模块,让模型能够更容易地表达巨大的梯度。
开启未来电子结构方法的新篇章
M-OFDFT成功突破了无轨道密度泛函框架在分子体系中的瓶颈,将其求解精度提升到了常用的KSDFT的水平,同时保有了其更低的计算代价,推进了电子结构方法在「精度-效率」方面的权衡,为分子科学研究提供了一种更有潜力的研究工具。
尽管M-OFDFT已经在某些分子体系上展现了出色的泛化性能,但在更大的分子体系上实现长时间且稳定的高精度模拟仍是一个巨大的挑战。微软研究院期待M-OFDFT可以沿着这一方向激发更多研究与创新,并在未来和其他方法一起为电子结构计算带来更多突破性的成果和影响。
相关文章:
[1] Do Transformers really perform badly for graph representation? Advances in Neural Information Processing Systems 34 (NeurIPS 2021).(https://proceedings.neurips.cc/paper/2021/hash/f1c1592588411002af340cbaedd6fc33-Abstract.html)
注:封面来自网络。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 比亚迪方程豹宣传片惊现 2009 年首款敞篷跑车 S8身影,4月16日见分晓
- 4月13日消息,方程豹汽车即将于4月16日举行春季发布会,届时备受期待的豹3、豹8等车型有望亮相。此次发布会备受关注,因为除了这两款新车型,方程豹还可能带来一款全新的敞篷跑车,这在最新宣传片中已初露端倪。在广告片中,一款造型独特的敞篷跑车引人注目。经过仔细观察,这款车很可能是比亚迪首款硬顶敞篷新车S8的重生版。S8曾于2009年上市,以其当时尚的外观和高科技配置赢得了消费者的喜爱。如今,这款车型似乎将以全新的面貌回归市场,为方程豹汽车品牌注入更多活力。数据小编理解了需求,新款S8有望采用先进的DMO专业跑
- 刚刚 0
-
 正版软件
正版软件
- 曝蔚来新品牌乐道选定三大电池巨头,比亚迪、宁德时代与中创新航联手供货
- 5月7日消息,近日路透社发布消息,称中国电动汽车制造商蔚来汽车已与比亚迪达成合作协议,后者将成为蔚来新推出的品牌乐道汽车的电池供应商。同时,宁德时代和中创新航也加入了这一合作阵容,共同为乐道汽车提供动力电池。根据协议分工,中创新航将专注于提供大容量电池组,而比亚迪则会与宁德时代联手,为新款乐道汽车供应小电池容量的电池组。这一合作动态无疑将对电动汽车行业产生深远影响。今年前三个月,国内动力电池产业创新联盟发布的数据显示,宁德时代、比亚迪和中创新航三家公司已经成为全球排名前三的动力电池供应商。其中,宁德时代的
- 10分钟前 0
-
 正版软件
正版软件
- cspr币是空气币吗
- CSPR币并非空气币,因为它基于坚实的技术基础、拥有强大的团队和支持,并具有实际用途。其独特的Casper共识机制、经验丰富的团队、不断壮大的生态系统和市场表现都支持这一结论。CSPR币用于支付交易费用、质押和参与网络治理。
- 25分钟前 0
-
 正版软件
正版软件
- 格密码的量子危机?一文带你解析格密码学术风波
- 区块链的量子安全威胁以及应对2024年3月10日,以太坊联合创始人VitalikButerin在以太坊研究论坛(ethresear.ch)发布最新文章《Howtohard-forktosavemostuser'sfundsinaquantumemergency》[1],文中表示:以太坊生态系统面临的量子计算攻击威胁,可以通过恢复性分叉策略和抗量子密码技术来保护用户资金安全。对于区块链来说,量子安全威胁到底是什么?量子计算[2]作为利用量子力学调控量子信息单元进行计算的新型计算模式,在20世纪80年
- 40分钟前 0
-
 正版软件
正版软件
- grt币怎么买
- GRT币可以在支持GRT交易的加密货币交易所(如Binance、Coinbase)购买。步骤如下:创建账户;充值资金;搜索GRT交易对;下单购买;存储GRT币。
- 55分钟前 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1881天前
-
 2
2
- Overture设置踏板标记的方法
- 1718天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1708天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1906天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1872天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1868天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1883天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1904天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00