利用游戏剧情发展测试人格、抑郁和认知模式:采用大型模型调研心理特质
 发布于2024-12-15 阅读(0)
发布于2024-12-15 阅读(0)
扫一扫,手机访问
心理测量在精神健康、自我了解、和个人发展方面都发挥着重要的作用。
传统的心理测量方法主要依赖于参与者填写自我报告问卷,通过回忆日常生活中的行为和情绪来进行测量。
这样的测量方式虽然高效便捷,但可能引发参与者的抗拒心理,降低被测意愿。
随着大语言模型(LLM)的发展,很多研究发现LLM能够展现出稳定的人格特质,模仿人类细微的情绪与认知模式,还能辅助各种各样的社会科学仿真实验,为教育心理学、社会心理学、文化心理学、临床心理学、心理咨询等诸多心理学研究领域,提供了新的研究思路。
近日,清华大学的研究团队基于大语言模型的多智能体系统,提出一种创新性的心理测量范式。

与传统自我报告问卷不同的是,该研究为每位参与者定制化生成一个可交互的叙事类型游戏,用户可自定义游戏的类型与主题。
随着游戏剧情的发展,参与者需要以第一人称视角,根据各种情节做出不同的选择,从而影响剧情的进展。通过研究参与者在游戏关键时刻的选择,可以评估他们的心理特征。

△自我报告问卷的心理学测量范式(左)与交互叙事类游戏的心理测量范式(右)对比
该研究的贡献主要体现在三个方面:
- 提出一种新的心理学测量范式,将传统问卷转化成基于游戏的交互测量;在保证心理测量信度和效度的基础上,提升参与者的沉浸感,改善被测体验。
- 为了实现游戏化的测量,该研究提出一种基于大语言模型的多智能体交互框架,名为PsychoGAT (Psychological Game AgenTs),确保了心理学测试场景的泛化性,与不同游戏设置下测量的鲁棒性。
- 通过自动化仿真评估与真人评估,在MBTI人格测试,PHQ-9抑郁测量,认知思维陷阱测试等任务上,该研究在心理测量学统计学指标和用户体验感指标上均展现出了显著的优越性。
接下来,我们一起来看看该研究的细节。
PsychoGAT长啥样?

△PsychoGAT框架示意图
智能体交互流程:
给定一个传统的心理学测试问卷,参与者自定义游戏类型和主题,然后由游戏设计师(Game Designer)智能体给出整体的游戏设计大纲。
然后,游戏管理员(Game Controller)智能体生成一个具体的游戏情节,在这个过程中评论员(Critic)智能体会对管理员生成内容进行多轮的审核与优化;优化完成后的游戏情节会被展现给参与者,参与者做出相应的选择后,管理员基于此选择推动剧情发展,按照这样的交互过程循环。
各智能体职能详述:
- 游戏设计师(Game Designer):利用CoT技术,生成第一人称叙事游戏的大纲,并保证这个故事线中所包含的情景,能够使得参与者表现出当前测量的心理特质。
与此同时,将标准的心理学自我报告问卷,根据当前游戏故事线进行改编,使两者的融合更为自然流畅。
- 游戏管理员(Game Controller):将改编后的问卷,按照游戏的故事线,依次进行实例化,变成故事的情节节点,并提供可能的选项,供参与者进行选择。
与此同时,游戏管理员将参与者的选择返回给游戏环境,并基于参与者的选择,控制游戏的剧情走向。为了实现游戏情节的连贯性,管理员智能体采用“记忆更新”机制。
- 评论员(Critic):旨在对游戏管理员的生成内容进行审核与优化。
主要针对以下三个问题:
1)优化一致性:随着游戏剧情推进,长文本问题会变得更加严重,使得“记忆更新”机制也无法完全保证情节一致性。
2)确保无偏性:参与者的选择会影响游戏情节的发展,但在参与者不做出选择之前,管理员不应该预设情节走向,即便之前的选择中参与者体现出了明显的倾向性。
3)改正漏缺项:对管理员生成的游戏情节进行细节审核,检查其是否具备基础的游戏沉浸感。
实验及结果

△三种常见心理学测量范式的对比:传统问卷,心理学家会谈,以及该研究提出的游戏化测评。
此处提到的均为基于AI的自动化测量,特别的,心理学家会谈,指目前与大语言模型结合的,由大语言模型扮演心理学家的会谈范式。
实验阶段,研究人员选择了三个常见的心理学测量任务:MBTI人格测试中的外倾性,PHQ-9抑郁检测,以及CBT疗法中前期的认知扭曲检测。
首先,研究人员和成熟的传统心理学问卷进行对比,旨在检验该研究的心理测量信度和效度。进一步,和其他三种自动化测量方法进行对比,检验不同测量方法的用户体验。
研究人员首先使用GPT-4模拟被测者,在不同的测量方法上记录测量过程与测量结果。这些测量记录被用于计算后续心理测量学信效度指标,以及用户体验感指标。
评价指标有两个:信效度指标和用户体验感指标。
- 信效度指标:心理测量学上,评价一个测量工具是否具有科学性,一般从信度(reliability)和效度(validity)两个维度进行验证。
在该研究中,信度的指标选择了两个统计学量来衡量内部一致性:Cronbach’s Alpha和Guttman’s Lambda 6;效度的指标采用皮尔森系数,分别衡量聚合效度(convergent validity)和区分效度 (discriminant validity)。
- 用户体验感指标,人工评估的指标包括:
1)一致性(Coherence, CH):内容逻辑是否连贯;
2)交互性(Interactivity, IA):是否对用户的选择有恰当且无偏的回应;
3)趣味性(Interest, INT):测量过程是否有趣;
4)沉浸感(Immersion, IM):测量过程是否让参与者沉浸代入;
5)满意度(Satisfaction, ST):整体测量过程的满意度。
下面是实验结果。
首先研究人员检验了该研究提出的PsychoGAT能够作为一个合格的心理学测量工具,结果如下表所示。

△PsychoGAT的信效度检验结果(+通过,++良好,+++优秀)
进一步,研究人员对比了不同心理测量范式的用户体验感,该研究提出的游戏化测评在交互性、趣味性和沉浸感上都显著优于其他方法:

△PsychoGAT的用户体验感结果,以及其他对比方法的相应结果
为了确保人工评估的有效性,研究人员计算了人工评估结果,在PsychoGAT各指标优于其他方法上的评估一致性:

△PsychoGAT的用户体验感指标由于对比方法在人工评估上的一致性
为了对PsychoGAT做进一步分析,研究人员首先检验了不同游戏场景下,游戏化测量的信效度具有很好鲁棒性:
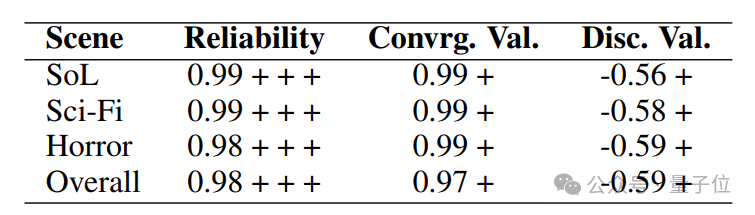
△PsychoGAT在不同游戏场景下测量信效度的鲁棒性
接着,探究了每一个智能体在PsychoGAT中发挥的作用:
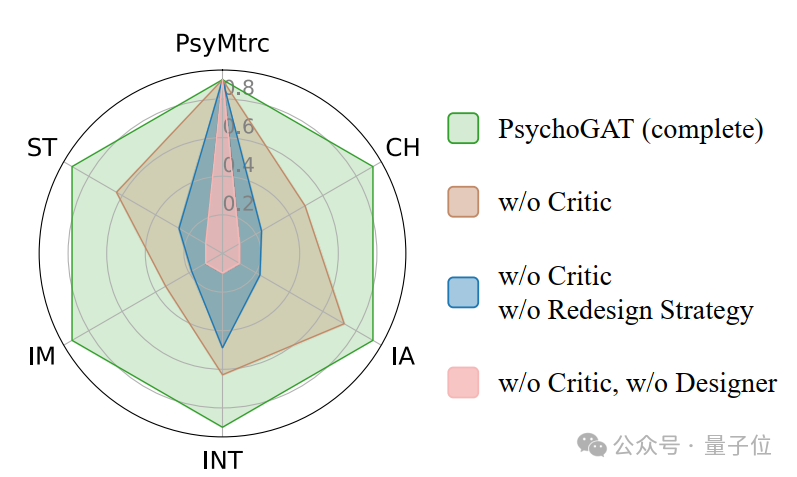
△PsychoGAT不同智能体的作用
最后,为了直观呈现PsychoGAT的游戏生成内容,研究人员用词云可视化了人格外倾性测试和抑郁测试:

△PsychoGAT在外倾性测量和抑郁测量的游戏场景生成可视化。
外倾性测试的内容主要集中在社交场景,而抑郁测试倾向于个人思维和情绪。
更多研究细节,可参考原论文。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 大众将在2024年二季度推出首款纯电动SUV“ID.UNYX”
- 工信部最近公布了最新一批新车申报目录,引发了人们对大众汽车(安徽)有限公司申报的一款纯电动多用途乘用车的广泛关注。这款新车型被命名为“ID.UNYX”,是大众安徽的首款产品,这个名称寓意着与众不同,独树一帜。据悉,"ID.UNYX"是基于大众集团的MEB平台开发的,定位为一款A级轿跑风格SUV。这款全新车型预计将于2024年第二季度正式发布,将作为ID.车型系列中的一员,为消费者提供全新的用户体验,满足市场多样化需求。ID.UNYX的设计风格将不同于现有的ID.车型系列,为消费者带来全新的驾驶感受和产品理
- 3分钟前 大众安徽 0
-
 正版软件
正版软件
- 苹果在巴西开始本地组装iPhone 15,以降低税收并增强竞争力
- 据巴西科技媒体MacMagazine报道,苹果公司最近开始在巴西本土组装iPhone15机型。这一消息源自苹果官网产品页面的最新变化。苹果选择在巴西组装生产iPhone手机可能是为了满足当地需求、降低生产成本或者是推动当地经济发展。这一举措也显示了苹果对巴西市场的重视和对当地消费者的承诺。随着全球市场对智能手机的需求不断增加,苹果公司的决定也是顺应了市场趋势。巴西作为一个重要的新兴市场,对苹果来说具有战略意义。这一举措有望进为了验证这一消息,MacMagazine前往了巴西的苹果商城,并仔细研究了iPho
- 13分钟前 苹果 0
-
 正版软件
正版软件
- 英睿达推出非传统12GB DDR5内存,打破市场常规
- 3月13日消息,众所周知,DDR5内存的常规容量如8GB、16GB、32GB以及24GB和48GB等已为大家所熟知。然而,英睿达近日在英国亚马逊上推出了一款别出心裁的12GBDDR5内存,打破了这一常规。这款内存的速度达到了5600MT/s,同时也支持在5200和4800MT/s模式下运行,显示出其出色的灵活性。据产品页面显示,其电压仅为1.1V,相较于DDR43200内存,速度提升了1.5倍,这无疑将为计算机性能带来显著的提升。预计这款内存将于3月31日开始发货。在价格方面,单条容量为12GB的内存条(
- 28分钟前 英睿达 0
-
 正版软件
正版软件
- Pico即将推出全新的VR头显Pico 4S,用户期待硬件升级
- 近期,科技圈再次掀起了一股虚拟现实(VR)的热潮。据称,字节跳动旗下的VR子公司Pico即将推出全新的独立VR头显——Pico4S。一位名为@Lunayian的用户在社交媒体上发布了一张3D模型图片,声称该图片来自PicoConnectPC客户端,展示了Pico4S的右控制器设计。这款控制器的外观与去年9月在网络上泄露的"Pico5"控制器非常相似,但与Pico4的控制器有一些明显的差异,主要体现在取消了定位环。这一设计调整可能预示着Pico4S将带来全新的用户体验和交互方式。据了解,Pico在去年底已递
- 33分钟前 字节跳动 0
-
 正版软件
正版软件
- Surface Duo找到了第二春:在开源社区中得到新生,支持Windows 11和安卓14
- 微软在双屏智能手机领域的计划似乎遇到了挑战,但令人振奋的是,SurfaceDuo得到了开源社区的支持,仍然展现出生机与活力。SurfaceDuo双屏手机焕发出新的生机,得益于两位开发者GustaveMonce和ThaiNguyen的不懈努力。他们成功让这款手机运行上了Windows11系统,并实现了对最新安卓14系统的适配。据小编了解,GustaveMonce主要负责推进的WindowsonArmforSurfaceDuo项目,在过去的几个月里取得了显著的进展。最近,Monce发布了一种全新的安装方法,通
- 43分钟前 微软 0













