开源bGPT或许是深度学习颠覆者?直接模拟二进制或许将开启数字世界新纪元!
 发布于2024-12-15 阅读(0)
发布于2024-12-15 阅读(0)
扫一扫,手机访问
微软亚洲研究院推出的最新成果bGPT,这种基于字节的Transformer模型,为我们探索数字世界开辟了新的大门。
与传统基于词表的语言模型不同,bGPT具有独特之处,即其能够直接处理原始二进制数据,不受特定格式或任务的限制。其旨在全面模拟数字世界,为模型的发展打开了新的可能性。

论文:https://arxiv.org/abs/2402.19155
代码:https://github.com/sanderwood/bgpt
模型:https://huggingface.co/sander-wood/bgpt
项目主页:https://byte-gpt.github.io
研究小组在他们的研究论文中展示了bGPT在建模方面的巨大潜力。通过进行字节级处理,bGPT不仅能够生成文本、图像和音频,还能够模拟计算机的行为,包括格式转换算法和CPU状态的建模。这种将所有数据视为字节序列的方法使得bGPT能够将不同类型的数据整合到同一个框架中。
一经发布,bGPT的论文在X(Twitter)上引起了广泛热议,突显了深度学习模式的潜在变革,为模型真正理解和模拟数字世界中的各种活动打开了新可能性。
二进制数据:构成数字世界的基础DNA
二进制数据是数字世界的基石,它贯穿了计算机处理器以及我们日常使用的电子产品的操作系统,是所有数据、设备和软件的核心。因此,基于这一基础,bGPT的目标是通过研究二进制数据序列来理解数字系统的内在逻辑,从而重塑和模拟各种复杂的数字现象。
bGPT通过字节级的处理,不仅能应用于常规的AI生成和理解任务,还能处理更多的非传统应用。例如,它能直接模拟MIDI——一种音乐传输和存储的标准格式,这在之前的研究中由于MIDI的二进制本质而避免了直接建模。
但bGPT天生适合此类任务,能够精确模拟音乐数据的转换算法,将ABC记谱法转换为MIDI格式时,达到极低的错误率(0.0011 BPB)。
在实际应用中,bGPT通常能够准确地完成ABC符号与MIDI文件之间的转换,有时甚至能纠正原始文件中的错误,使音乐转换更加准确。

bGPT自动将ABC记谱法转换成MIDI格式(上图)与原MIDI数据(下图)的对比,凸显了关键的差异:虽然原MIDI数据中漏掉了一拍(见下图),导致和弦伴奏断开,但由bGPT转换的结果(见上图)正确填补了这一缺失,确保了和弦伴奏的流畅性。
研究团队还将CPU建模作为硬件行为模拟的代表性任务:该任务要求模型接收低级机器指令序列作为输入,其目标是准确预测每个指令执行后CPU状态如何更新,直至程序停止。
在这个任务中,bGPT展现出超过99.99%的准确率,显示了字节模型在处理原生二进制数据方面的强大能力和可扩展性。

在提供了程序和初始CPU状态的情况下,bGPT能够准确地预测CPU执行的完整过程,直到程序终止。在这个示例中,bGPT精确地处理了所有CPU指令。为了便于理解,这里将实际的字节序列转换成了更易读的格式。
从字节到万物:突破边界,向着统一的数据建模进发
bGPT不仅能处理原生二进制数据,还能将多种数据类型融合进一个统一的模型架构中,视一切数据为字节序列。
这种方法不但简化了数据建模流程,还使得从任何数据源的整合变得轻而易举,且无需为特定数据类型定制模型。
研究团队在论文中举例了传统文本、图像及音频文件,展现了bGPT在统一数据建模方面的能力。他们训练的bGPT模型拥有约1亿参数。
实验结果表明,在与GPT-2(文本模型)、ViT(视觉模型)和AST(音频模型)等同规模模型的比较中,bGPT在不同数据类型上均展现出了可媲美的性能。
bGPT在文本生成方面的表现非常出色。得益于其字节级的文本编码,该模型无需依赖词汇表,从而能支持所有语言。
它的分层Transformer架构,尽管计算开销与GPT-2相近,却能生成长达8KB的文本,大大超出了GPT-2的长度限制。在经过Wikipedia数据进行预训练后,bGPT生成的文本在风格和主题上都与GPT-2不相上下,证明了其在文本生成方面的强大能力。
bGPT在Wikipedia数据集上进行预训练,生成的文本样例质量和主题一致性与GPT-2相当。
bGPT可以通过预测图像字节序列中的下一个字节来生成图像。该模型在ImageNet数据集上进行了预训练,生成的图像分辨率为32x32像素。
虽然在当前规模下,通过字节序列准确捕捉图像的二维空间关系有所困难,导致生成的图像存在伪影和噪点,但纹理和光影效果通常还是比较准确的。
此外,这些生成的图像均能被正常解码为BMP文件。研究团队指出,通过扩大bGPT的规模,类似于OpenAI开发的iGPT在像素序列建模方面的方法,或许可以实现更高质量、更逼真的图像生成。
这些是由在ImageNet数据集上进行预训练的bGPT生成的一组图像。虽然图像的纹理和光影效果通常比较准确,但在这些生成的图像中识别主要物体却有一定难度。
bGPT将音频数据视为字节序列,能生成1秒长、采样率为8000 Hz的音频样本。
该模型在LibriSpeech数据集上完成了预训练,并进一步在Speech Commands v2数据集上进行微调和演示。bGPT生成的音频样本保持了较高的准确度,其中一些样本几乎与真实音频无法区分。以下是展示bGPT在音频生成领域能力的示例集。
通过bGPT探索字节构成的数字世界
传统语言模型,不管它们有多强大,主要专注于处理自然语言文本。bGPT模型通过基于字节的处理机制,打破了这种仅限于文本处理的局限性,开辟了一个全新的数据处理范畴。
这一进步让bGPT有能力无缝地处理包括文本、图像、音频在内的各种数据类型,甚至能处理来自算法和硬件的原生二进制数据,为全面模拟和理解数字世界铺平了道路。
虽然bGPT展现出了引人注目的能力,但其在计算开销方面的局限性,如当前在常规显卡上仅能处理最大8KB的字节序列,对于那些需要生成或处理大量数据的应用来说,构成了明显的限制。未来的工作计划将集中在开发更高效的算法和利用硬件的进步上,旨在提高处理更大规模数据序列的能力。
全球的技术爱好者们已经开始展望bGPT未来的潜力,从网络修剪和自我学习的优化到超大规模网络的自我重构能力,这些讨论指向了一个共同的愿景:bGPT最终可能实现一个统一的模型,能够处理和输出所有类型的字节数据,真正成为数字世界的全面模拟器。

研究团队已将bGPT的代码和模型开源。这意味着你可以在自己的数据集上直接训练bGPT,无需做出任何模型架构上的调整,便可探索字节模型在数字领域的广阔前景。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 英睿达推出非传统12GB DDR5内存,打破市场常规
- 3月13日消息,众所周知,DDR5内存的常规容量如8GB、16GB、32GB以及24GB和48GB等已为大家所熟知。然而,英睿达近日在英国亚马逊上推出了一款别出心裁的12GBDDR5内存,打破了这一常规。这款内存的速度达到了5600MT/s,同时也支持在5200和4800MT/s模式下运行,显示出其出色的灵活性。据产品页面显示,其电压仅为1.1V,相较于DDR43200内存,速度提升了1.5倍,这无疑将为计算机性能带来显著的提升。预计这款内存将于3月31日开始发货。在价格方面,单条容量为12GB的内存条(
- 8分钟前 英睿达 0
-
 正版软件
正版软件
- Pico即将推出全新的VR头显Pico 4S,用户期待硬件升级
- 近期,科技圈再次掀起了一股虚拟现实(VR)的热潮。据称,字节跳动旗下的VR子公司Pico即将推出全新的独立VR头显——Pico4S。一位名为@Lunayian的用户在社交媒体上发布了一张3D模型图片,声称该图片来自PicoConnectPC客户端,展示了Pico4S的右控制器设计。这款控制器的外观与去年9月在网络上泄露的"Pico5"控制器非常相似,但与Pico4的控制器有一些明显的差异,主要体现在取消了定位环。这一设计调整可能预示着Pico4S将带来全新的用户体验和交互方式。据了解,Pico在去年底已递
- 13分钟前 字节跳动 0
-
 正版软件
正版软件
- Surface Duo找到了第二春:在开源社区中得到新生,支持Windows 11和安卓14
- 微软在双屏智能手机领域的计划似乎遇到了挑战,但令人振奋的是,SurfaceDuo得到了开源社区的支持,仍然展现出生机与活力。SurfaceDuo双屏手机焕发出新的生机,得益于两位开发者GustaveMonce和ThaiNguyen的不懈努力。他们成功让这款手机运行上了Windows11系统,并实现了对最新安卓14系统的适配。据小编了解,GustaveMonce主要负责推进的WindowsonArmforSurfaceDuo项目,在过去的几个月里取得了显著的进展。最近,Monce发布了一种全新的安装方法,通
- 23分钟前 微软 0
-
 正版软件
正版软件
- 佳能2024年战略:成为无反相机市场领军者,拓展3D影像应用
- 佳能最近公布了他们2024年的企业战略,其中强调了他们在未来两年内力争在无反相机市场取得绝对领先地位的目标。这一战略计划是由佳能影像事业部副总负责人GoTokura在上个月的CP+展会上宣布的。为了实现这一目标,佳能计划通过提供完整的EOSR系统产品线,并积极拓展视频用户群体,同时持续为专业人士提供支持,来加强其在无反相机市场的地位。尽管佳能在美国的可换镜头无反相机市场已经占据领先地位,但公司仍希望进一步巩固其市场地位,以实现“绝对领先”的目标。据了解,尽管佳能在无反相机市场取得了一定进展,但要想保持竞争
- 38分钟前 佳能 0
-
 正版软件
正版软件
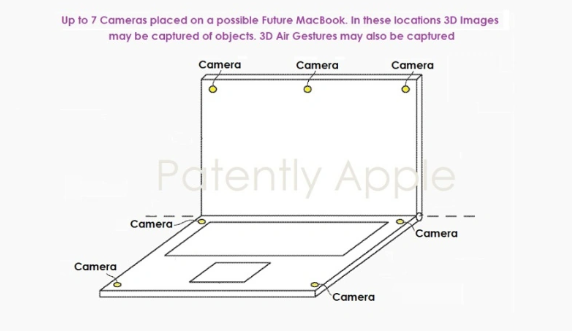
- 苹果推出新专利:折叠电子设备将配备先进摄像头系统
- 近日消息显示,苹果最近在美国成功获得了一项关于新型摄像头系统的专利授权。这项专利可能会为可折叠电子设备带来一场重大的技术革新。据悉,该专利涉及一套内置在可折叠电子设备中的摄像头系统,同时还揭示了一种全新的七摄像头系统,可能被整合到MacBook中。这一系统使用户能够拍摄高质量的3D图像,并捕捉到准确的3D手势动作。该专利描述了一种电子设备,具有可弯曲和重新配置的功能。这些设备配备了摄像头,摄像头分布在不同位置,能够拍摄场景的多个角度。在某些情况下,这些摄像头可以组成一个扇形视野,捕捉到的场景图像会自动拼接
- 53分钟前 苹果 0













