Meta引入两个大规模数据中心,配备近50000块英伟达H100 GPU
 发布于2024-12-16 阅读(0)
发布于2024-12-16 阅读(0)
扫一扫,手机访问

Meta日前推出两个功能强大的GPU集群,用于支持下一代生成式AI模型的训练,包括即将推出的Llama 3。
据报道,这两个数据中心都配备了高达24,576块GPU,旨在支持比之前发布的更大、更复杂的生成式AI模型。
作为一种流行的开源算法模型,Meta的Llama能与OpenAI的GPT和Google的Gemini相媲美。
Meta刷新AI集群规模
据极客网了解,这两个GPU集群都搭载了英伟达目前功能最强大的H100 GPU,规模比Meta之前推出的大型集群要庞大得多。此前,Meta的集群拥有大约16,000块Nvidia A100 GPU。
据报道,Meta已经采购了成千上万块英伟达最新推出的GPU。市场调研公司Omdia在最新报告中指出,Meta已经成为英伟达最重要的客户之一。
Meta工程师宣布,他们计划利用全新的GPU集群对现有的AI系统进行微调,以训练出更新更强大的AI系统,其中包括Llama 3。
该工程师指出,Llama 3的开发工作目前正在“进行中”,但并没有透露何时对外发布。
Meta的长期目标是发展通用人工智能(AGI)系统,因为AGI在创造性方面更接近人类,与现有的生成式AI模型有着明显的区别。
新的GPU集群将有助于Meta实现这些目标。此外,该公司正在改进PyTorch AI框架,使其能够支持更多的GPU。
两个GPU集群采用不同架构
值得一提的是,虽然这两个集群的GPU数量完全相同,都能以每秒400GB的端点相互连接,但它们采用了不同的架构。
其中,一个GPU集群可以通过融合以太网网络结构远程访问直接存储器或RDMA,该网络结构采用Arista Networks的Arista 7800与Wedge400和Minipack2 OCP机架交换机构建。另一个GPU集群使用英伟达的Quantum2 InfiniBand网络结构技术构建。
这两个集群都使用了Meta的开放式GPU硬件平台Grand Teton,该平台旨在支持大规模的AI工作负载。Grand Teton的主机到GPU带宽是其前身Zion-EX平台的四倍,计算能力、带宽以及功率是Zion-EX的两倍。
Meta表示,这两个集群采用了最新的开放式机架电源和机架基础设施,旨在为数据中心设计提供更大的灵活性。Open Rack v3允许将电源架安装在机架内部的任何地方,而不是将其固定在母线上,从而实现更灵活的配置。
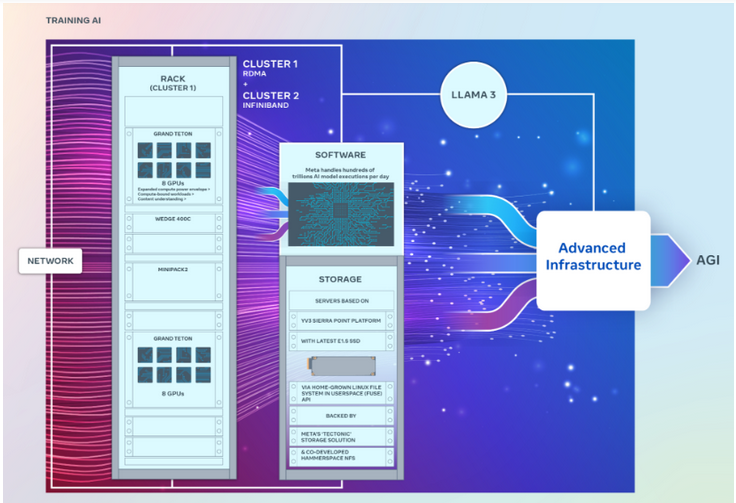
此外,每个机架的服务器数量也是可定制的,从而在每个服务器的吞吐量容量方面实现更有效的平衡。
在存储方面, 这两个GPU集群基于YV3 Sierra Point服务器平台,采用了最先进的E1.S固态硬盘。
更多GPU正在路上
Meta工程师在文中强调,该公司致力于AI硬件堆栈的开放式创新。“当我们展望未来时,我们认识到,以前或目前有效的方法可能不足以满足未来的需求。这就是我们不断评估和改进基础设施的原因。”
Meta是最近成立的AI联盟的成员之一。该联盟旨在创建一个开放的生态系统,以提高AI开发的透明度和信任,并确保每个人都能从其创新中受益。
Meta方面还透露,将继续购买更多的Nvidia H100 GPU,计划在今年年底前拥有35万块以上的GPU。这些GPU将用于持续构建AI基础设施,意味着未来还有更多、更强大的GPU集群问世。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 数字货币钱包地址怎么获得
- 数字货币钱包地址是用于交易的唯一标识符。获取方式如下:1.安装数字货币钱包并创建新地址;2.给地址添加标签;3.分享地址供他人向你发送数字资产。
- 12分钟前 0
-
 正版软件
正版软件
- 回顾ETH Denver 2024七个演讲:MEV、ERC-4377 、区块空间商业模式、公共物品资金、社区
- ETHDenver2024已经圆满结束,在整个活动期间,演讲者们带来了各种各样的议题,从技术创新到社区发展,无一不在探讨着Web3未来前景。现在让我们回顾一下其中的一些精彩演讲,深入洞察行业的最新动态。TL;DR:EigenPhi数据分析师-MEV不断变化的格局:隐私订单和交易可观察性对MEV有影响。搜索者和建设者的合作关系可能导致某些搜索者垄断MEV收入,损害生态系统公平性。以太坊基金会成员-理解ERC4377:ERC4377协议旨在提高智能合约账户易用性和去中心化特性。智能合约交易验证阶段受到限制,防
- 22分钟前 eth 回顾 0
-
 正版软件
正版软件
- Binance Labs宣布投资比特币再质押项目BounceBit!何一:CeFi和DeFi融合
- 本站(120bTC.coM):BinanceLabs宣布对BounceBit进行投资,它是比特币再质押及CeDeFi协议,旨在将比特币从被动资产,转变为加密货币生态系统中的动态参与者。BounceBit是想利用比特币的潜力,将其整合进各种产生收益的活动中,而不改变其底层区块链。这一协议的核心理念是利用以资产为主导的策略,来赋予比特币主导地位,这些策略包括资金费率套利,和发行链上凭证,以进行再质押和挖矿。Binance的共同创办人及BinanceLabs负责人何一表示:「BounceBit通过CeFi和De
- 37分钟前 莱特币投资 如何投资比特币 区块链投资骗局 0
-
 正版软件
正版软件
- 吉利银河神秘新车亮相,科技惊艳全场!
- 4月18日消息,吉利银河今日宣布正式发布,其科技旗舰SUV新品将会在即将到来的4月25日北京国际车展上惊艳登场。根据官方发布的预热图中可以看出,这款新型SUV设计独特,未设置传统的车门把手,而是可能采用创新的前后对开门设计,同时还装备了流媒体后视镜,展现了吉利银河在科技和设计上的前瞻性。去年的银河L7发布会上,吉利已经向公众展示了银河品牌的未来产品线,其中就包括了预计2025年推出的银河L9电混SUV。此外,吉利银河E5紧凑级纯电SUV也已经通过了工信部的申报,预计将在今年第二季度正式上市,这无疑将进一步
- 52分钟前 吉利银河 0
-
 正版软件
正版软件
- 火币里购买狗狗币
- 在火币上购买狗狗币的步骤:创建火币账户并完成KYC验证。充值资金,支持法币付款方式(因国家/地区而异)。搜索“DOGE”交易对,选择“买入”选项卡并输入购买金额。检查交易详细信息,然后点击“买入”以完成交易。
- 1小时前 21:40 0













