放弃等待OpenAI,全球首个类Sora项目率先开源!所有训练细节和模型权重均公开,成本仅需1万美元
 发布于2024-12-18 阅读(0)
发布于2024-12-18 阅读(0)
扫一扫,手机访问
就在不久前,OpenAI Sora凭借其惊人的视频生成效果迅速走红,凸显出与其他文生视频模型的差异,并成为全球瞩目的焦点。
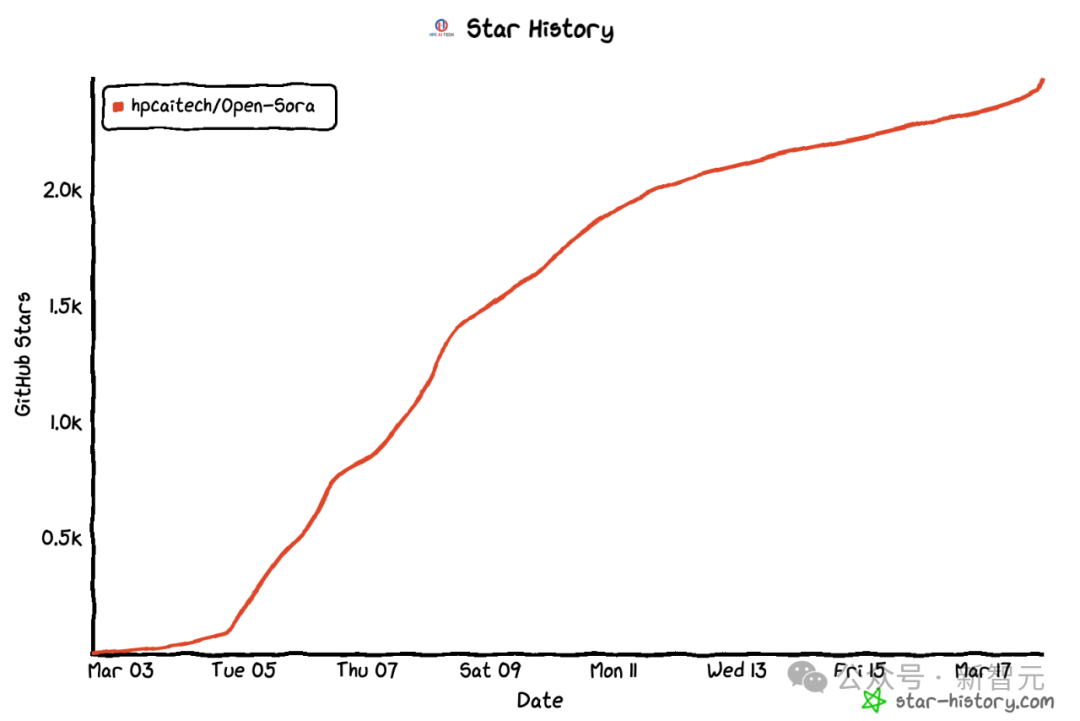
继2周前推出成本直降46%的Sora训练推理复现流程后,Colossal-AI团队全面开源全球首个类Sora架构视频生成模型「Open-Sora 1.0」——涵盖了整个训练流程,包括数据处理、所有训练细节和模型权重,携手全球AI热爱者共同推进视频创作的新纪元。
Open-Sora开源地址:https://github.com/hpcaitech/Open-Sora
先睹为快,我们先看一段由Colossal-AI团队发布的「Open-Sora 1.0」模型生成的都市繁华掠影视频。

Open-Sora 1.0生成的都市繁华掠影
这仅仅是Sora复现技术冰山的一角,关于以上文生视频的模型架构、训练好的模型权重、复现的所有训练细节、数据预处理过程、demo展示和详细的上手教程,Colossal-AI团队已经全面免费开源在GitHub。
新智元第一时间联系了该团队,获悉他们将持续更新Open-Sora相关解决方案和最新动态。感兴趣的朋友可保持关注Open-Sora的开源社区。
全面解读Sora复现方案
接下来,我们将深入解读Sora复现方案的多个关键维度,包括模型架构设计、训练复现方案、数据预处理、模型生成效果展示以及高效训练优化策略。

模型架构设计
模型采用了目前火热的Diffusion Transformer(DiT)[1]架构。
作者团队以同样使用DiT架构的高质量开源文生图模型PixArt-α [2]为基座,在此基础上引入时间注意力层,将其扩展到了视频数据上。
具体来说,整个架构包括一个预训练好的VAE,一个文本编码器,和一个利用空间-时间注意力机制的STDiT(Spatial Temporal Diffusion Transformer)模型。
其中,STDiT 每层的结构如下图所示。它采用串行的方式在二维的空间注意力模块上叠加一维的时间注意力模块,用于建模时序关系。
在时间注意力模块之后,交叉注意力模块用于对齐文本的语意。与全注意力机制相比,这样的结构大大降低了训练和推理开销。
与同样使用空间-时间注意力机制的Latte [3]模型相比,STDiT可以更好的利用已经预训练好的图像DiT的权重,从而在视频数据上继续训练。
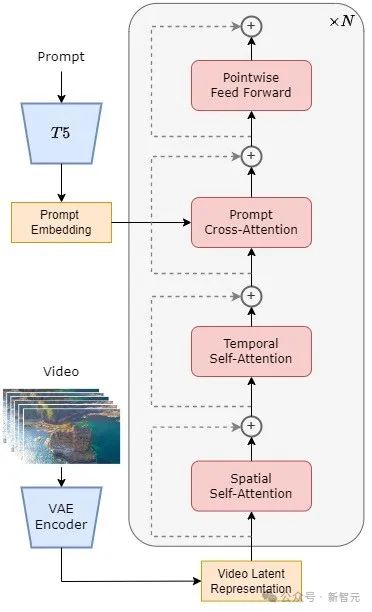
STDiT结构示意图
整个模型的训练和推理流程如下。据了解,在训练阶段首先采用预训练好的Variational Autoencoder(VAE)的编码器将视频数据进行压缩,然后在压缩之后的潜在空间中与文本嵌入(text embedding)一起训练STDiT扩散模型。
在推理阶段,从VAE的潜在空间中随机采样出一个高斯噪声,与提示词嵌入(prompt embedding)一起输入到STDiT中,得到去噪之后的特征,最后输入到VAE的解码器,解码得到视频。

模型的训练流程
训练复现方案
我们向该团队了解到,Open-Sora的复现方案参考了Stable Video Diffusion(SVD)[3]工作,共包括三个阶段,分别是:
1. 大规模图像预训练;
2. 大规模视频预训练;
3. 高质量视频数据微调。
每个阶段都会基于前一个阶段的权重继续训练。相比于从零开始单阶段训练,多阶段训练通过逐步扩展数据,更高效地达成高质量视频生成的目标。

训练方案三阶段
第一阶段:大规模图像预训练
第一阶段通过大规模图像预训练,借助成熟的文生图模型,有效降低视频预训练成本。
作者团队向我们透露,通过互联网上丰富的大规模图像数据和先进的文生图技术,我们可以训练一个高质量的文生图模型,该模型将作为下一阶段视频预训练的初始化权重。
同时,由于目前没有高质量的时空VAE,他们采用了Stable Diffusion [5]模型预训练好的图像VAE。该策略不仅保障了初始模型的优越性能,还显著降低了视频预训练的整体成本。
第二阶段:大规模视频预训练
第二阶段执行大规模视频预训练,增加模型泛化能力,有效掌握视频的时间序列关联。
我们了解到,这个阶段需要使用大量视频数据训练,保证视频题材的多样性,从而增加模型的泛化能力。第二阶段的模型在第一阶段文生图模型的基础上加入了时序注意力模块,用于学习视频中的时序关系。
其余模块与第一阶段保持一致,并加载第一阶段权重作为初始化,同时初始化时序注意力模块输出为零,以达到更高效更快速的收敛。
Colossal-AI团队使用了PixArt-alpha[2]的开源权重作为第二阶段STDiT模型的初始化,以及采用了T5 [6]模型作为文本编码器。同时他们采用了256x256的小分辨率进行预训练,进一步增加了收敛速度,降低训练成本。
第三阶段:高质量视频数据微调
第三阶段对高质量视频数据进行微调,显著提升视频生成的质量。
作者团队提及第三阶段用到的视频数据规模比第二阶段要少一个量级,但是视频的时长、分辨率和质量都更高。通过这种方式进行微调,他们实现了视频生成从短到长、从低分辨率到高分辨率、从低保真度到高保真度的高效扩展。
作者团队表示,在Open-Sora的复现流程中,他们使用了64块H800进行训练。
第二阶段的训练量一共是2808 GPU hours,约合7000美元。第三阶段的训练量是1920 GPU hours,大约4500美元。经过初步估算,整个训练方案成功把Open-Sora复现流程控制在了1万美元左右。
数据预处理
为了进一步降低Sora复现的门槛和复杂度,Colossal-AI团队在代码仓库中还提供了便捷的视频数据预处理脚本,让大家可以轻松启动Sora复现预训练,包括公开视频数据集下载,长视频根据镜头连续性分割为短视频片段,使用开源大语言模型LLaVA [7]生成精细的提示词。
作者团队提到他们提供的批量视频标题生成代码可以用两卡3秒标注一个视频,并且质量接近于GPT-4V。最终得到的视频/文本对可直接用于训练。
借助他们在GitHub上提供的开源代码,我们可以轻松地在自己的数据集上快速生成训练所需的视频/文本对,显著降低了启动Sora复现项目的技术门槛和前期准备。

基于数据预处理脚本自动生成的视频/文本对
模型生成效果展示
下面我们来看一下Open-Sora实际视频生成效果。比如让Open-Sora生成一段在悬崖海岸边,海水拍打着岩石的航拍画面。

再让Open-Sora去捕捉山川瀑布从悬崖上澎湃而下,最终汇入湖泊的宏伟鸟瞰画面。

除了上天还能入海,简单输入prompt,让Open-Sora生成了一段水中世界的镜头,镜头中一只海龟在珊瑚礁间悠然游弋。

Open-Sora还能通过延时摄影的手法,向我们展现了繁星闪烁的银河。

如果你还有更多视频生成的有趣想法,可以访问Open-Sora开源社区获取模型权重进行免费的体验。
链接:https://github.com/hpcaitech/Open-Sora
值得注意的是,作者团队在Github上提到目前版本仅使用了400K的训练数据,模型的生成质量和遵循文本的能力都有待提升。例如在上面的乌龟视频中,生成的乌龟多了一只脚。Open-Sora 1.0也并不擅长生成人像和复杂画面。
作者团队在Github上列举了一系列待做规划,旨在不断解决现有缺陷,提升生成质量。

高效训练加持
除了大幅降低Sora复现的技术门槛,提升视频生成在时长、分辨率、内容等多个维度的质量,作者团队还提供了Colossal-AI加速系统进行Sora复现的高效训练加持。
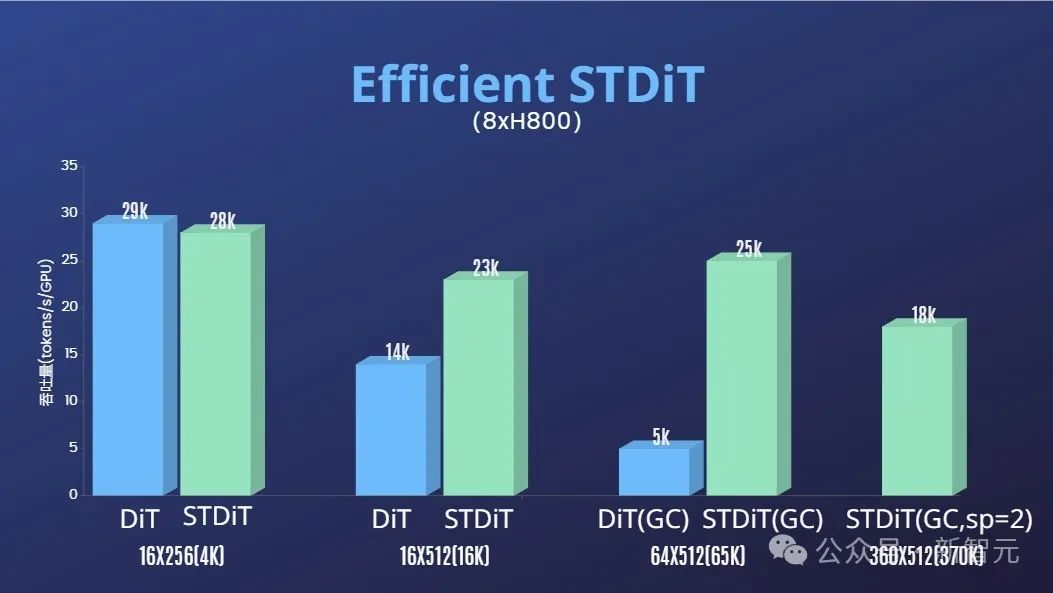
通过算子优化和混合并行等高效训练策略,在处理64帧、512x512分辨率视频的训练中,实现了1.55倍的加速效果。
同时,得益于Colossal-AI的异构内存管理系统,在单台服务器上(8 x H800)可以无阻碍地进行1分钟的1080p高清视频训练任务。

此外,在作者团队的报告中,我们也发现STDiT模型架构在训练时也展现出卓越的高效性。
和采用全注意力机制的DiT相比,随着帧数的增加,STDiT实现了高达5倍的加速效果,这在处理长视频序列等现实任务中尤为关键。
一览Open-Sora模型视频生成效果
欢迎持续关注Open-Sora开源项目:https://github.com/hpcaitech/Open-Sora
作者团队提及,他们将会继续维护和优化Open-Sora项目,预计将使用更多的视频训练数据,以生成更高质量、更长时长的视频内容,并支持多分辨率特性,切实推进AI技术在电影、游戏、广告等领域的落地。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 五菱荣光推出超长双后轮新款,提升了载重能力
- 五菱汽车最近宣布推出了全新的五菱荣光新卡超长款双后轮车型,进一步扩大了其大微卡产品线。这款新车专为大载重微卡市场设计,价格区间定在5.98-7.28万元。该车旨在提供用户更大的装载能力和更出色的行驶稳定性,以满足用户对高性能微卡的需求。五菱荣光新卡超长款双后轮车型提供了汽油和CNG两种不同的动力版本,以满足不同用户的需求。这款新车共有8款配置,包括单排和双排车型的基本款和舒适款,为消费者提供了更多选择。为了感谢广大用户的支持,五菱汽车推出了限时优惠政策,购买新车的用户可享受高达3,000元的置换补贴和同等
- 5分钟前 五菱荣光 0
-
 正版软件
正版软件
- 陶大程团队与港大、UMD合作发布LLM知识蒸馏最新综合研究报道374篇相关工作
- 大语言模型(LargeLanguageModels,LLMs)在过去两年内迅速发展,涌现出一些现象级的模型和产品,如GPT-4、Gemini、Claude等,但大多数是闭源的。研究界目前能接触到的大部分开源LLMs与闭源LLMs存在较大差距,因此提升开源LLMs及其他小模型的能力以减小其与闭源大模型的差距成为了该领域的研究热点。LLM的强大能力,特别是闭源LLM,使得科研人员和工业界的从业者在训练自己的模型时都会利用到这些大模型的输出和知识。这一过程本质上是知识蒸馏(Knowledge,Distillat
- 10分钟前 产业 大语言模型 知识蒸馏 0
-
 正版软件
正版软件
- 曝料者透露:苹果即将推出折叠iPhone和全面屏OLED产品
- 最近,知名爆料者Revegnus(Tech_Reve)在X平台上重新开始更新,并分享了一份据称是来自三星安全部门的苹果产品路线图。除了现已上市的VisionPro头戴设备和即将推出的OLEDiPadPro之外,这份路线图还揭示了苹果在2025年以及未来的产品规划。据悉,在2025年,苹果计划发布的iPhone17Pro和iPhone17ProMax将会进行重大升级。这两款手机的三枚后置镜头都有望采用48MP模组,进一步提升拍照效果,为用户带来更出色的影像体验。此外,苹果还计划在同一年推出iPhoneSE4
- 25分钟前 苹果 0
-
 正版软件
正版软件
- 倾情打造!哪吒L汽车集内外一体,为您奉上极致驾乘体验
- 备受瞩目的哪吒L汽车即将在4月正式上市,引起了众多消费者的关注。这款中大型SUV采用独特的定位和丰富的配置,吸引了广泛的目光。哪吒L汽车是基于创新的山海平台打造的,提供了纯电版和增程版两种动力选择,以满足不同消费者的需求。近日,哪吒汽车CEO张勇在预热活动中透露了哪吒L的豪华配置。他表示,新车将配备独立压缩机双开门冰箱,最低制冷温度可达零下6度,为乘客提供清凉的饮品享受。此外,车内还将搭载两块15.6英寸的彩电,为乘客带来丰富的娱乐体验。哪吒L还配备了8点按摩零重力沙发座椅,为驾乘者提供极致的舒适感受。张
- 40分钟前 哪吒汽车 0
-
 正版软件
正版软件
- Devin对体验的第一印象:令人沉迷的高度完成度,兴致勃勃开始编码,但替代程序员尚需努力
- 由10枚IOI金牌在手的创业团队CognitionAI开发的全球首个AI程序员智能体Devin,一发布就让科技圈坐立不安。在演示中,Devin几乎已经可以独立完成许多需要普通程序员花费大量时间才能完成的任务,而且表现一点也不逊色于普通程序员。但是,产品能力的边界在哪里,实际体验和演示时候有差距,还的看上手实测之后的效果。这位斯坦福的小哥在Devin发布的第一时间就联系了团队,获得了第一手体验的资格。他让Devin帮它做了几个难度不一的项目,录制了一个视频,在推上写下了自己的使用感受。下一个任务是让Devi
- 55分钟前 AI 程序员 0













