使用Ruby在本地运行开源AI模型以维护客户私密性
 发布于2024-12-18 阅读(0)
发布于2024-12-18 阅读(0)
扫一扫,手机访问
译者 | 陈峻
审校 | 重楼
最近,我们实施了一个定制化的人工智能(AI)项目。鉴于甲方持有着非常敏感的客户信息,为了安全起见,我们不能将它们传递给OpenAI或其他专有模型。因此,我们在AWS虚拟机中下载并运行了一个开源的AI模型,使之完全处于我们的控制之下。同时,Rails应用可以在安全的环境中,对AI进行API调用。当然,如果不必考虑安全问题,我们更倾向于直接与OpenAI合作。

下面,我将和大家分享如何在本地下载开源的AI模型,让它运行起来,以及如何针对其运行Ruby脚本。
为什么要定制?
这个项目的动机很简单:数据安全。在处理敏感的客户信息时,最可靠的做法通常是在公司内部进行。因此,我们需要定制化的AI模型,在提供更高级别的安全控制和隐私保护方面发挥作用。
开源模式
在过去的6个月里,市场上出现了诸如:Mistral、Mixtral和Lama等大量开源的AI模型。它们虽然没有GPT-4那么强大,但是其中不少模型的性能已经超过了GPT-3.5,而且随着时间的推移,它们会越来越强。当然,该选用哪种模型,则完全取决于您的处理能力和需要实现的目标。
由于我们将在本地运行AI模型,因此选择了大小约为4GB的Mistral。它在大多数指标上都优于GPT-3.5。尽管Mixtral的性能优于Mistral,但它是一个庞大的模型,至少需要48GB内存才能运行。
参数
在谈论大语言模型(LLM)时,我们往往会考虑提到它们的参数大小。在此,我们将在本地运行的Mistral模型是一个70亿参数的模型(当然,Mixtral拥有700亿个参数,而GPT-3.5大约有1750亿个参数)。
通常,大型语言模型使用基于神经网络的技术。神经网络是由神经元组成的,每个神经元与下一层的所有其他神经元相连。
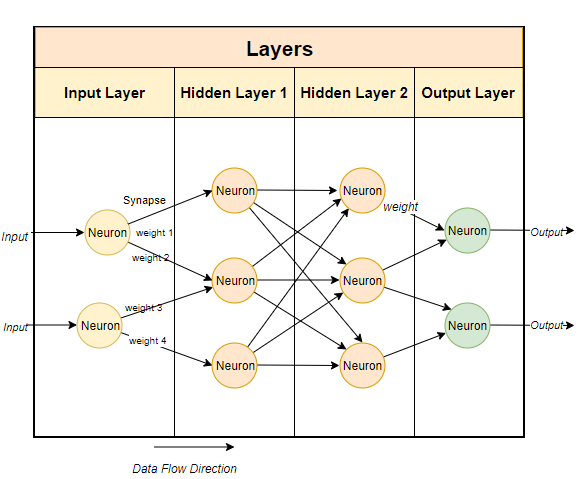
如上图所示,每个连接都有一个权重,通常用百分比表示。每个神经元还有一个偏差(bias),当数据通过某个节点时,偏差会对数据进行修正。
神经网络的目的是要“学到”一种先进的算法、一种模式匹配的算法。通过在大量文本中接受训练,它将逐渐学会预测文本模式的能力,进而对我们给出的提示做出有意义的回应。简单而言,参数就是模型中权重和偏差的数量。它可以让我们了解神经网络中有多少个神经元。例如,对于一个70亿参数的模型来说,大约有100层,每层都有数千个神经元。
在本地运行模型
要在本地运行开源模型,首先必须下载相关应用。虽然市场上有多种选择,但是我发现最简单,也便于在英特尔Mac上运行的是Ollama。
虽然Ollama目前只能在Mac和Linux上运行,不过它未来还能运行在Windows上。当然,您可以在Windows上使用WSL(Windows Subsystem for Linux)来运行Linux shell。
Ollama不但允许您下载并运行各种开源模型,而且会在本地端口上打开模型,让您能够通过Ruby代码进行API调用。这便方便了Ruby开发者编写能够与本地模型相集成的Ruby应用。
获取Ollama
由于Ollama主要基于命令行,因此在Mac和Linux系统上安装Ollama非常简单。您只需通过链接https://olama.ai/下载Ollama,花5分钟左右时间安装软件包,再运行模型即可。
安装首个模型
在设置并运行Ollama之后,您将在浏览器的任务栏中看到Ollama图标。这意味着它正在后台运行,并可运行您的模型。为了下载模型,您可以打开终端并运行如下命令:
ollama run mistral
由于Mistral约有4GB大小,因此您需要花一段时间完成下载。下载完成后,它将自动打开Ollama提示符,以便您与Mistral进行交互和通信。
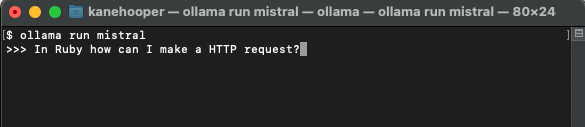
下一次您再通过Ollama运行mistral时,便可直接运行相应的模型了。
定制模型
类似我们在OpenAI中创建自定义的GPT,通过Ollama,您可以对基础模型进行定制。在此,我们可以简单地创建一个自定义的模型。更多详细案例,请参考Ollama的联机文档。
首先,您可以创建一个Modelfile(模型文件),并在其中添加如下文本:
FROM mistral# Set the temperature set the randomness or creativity of the responsePARAMETER temperature 0.3# Set the system messageSYSTEM ”””You are an excerpt Ruby developer. You will be asked questions about the Ruby Programminglanguage. You will provide an explanation along with code examples.”””
上面出现的系统消息是AI模型做出特定反应的基础。
接着,您可以在终端上运行如下命令,以创建新的模型:
ollama create <model-name> -f './Modelfile
在我们的项目案例中,我将该模型命名为Ruby。
ollama create ruby -f './Modelfile'
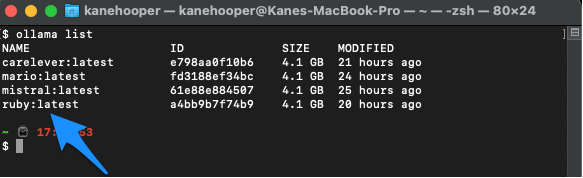
同时,您可以使用如下命令罗列显示自己的现有模型:
ollama list
Ollama run ruby
与Ruby集成
虽然Ollama尚没有专用的gem,但是Ruby开发人员可以使用基本的HTTP请求方法与模型进行交互。在后台运行的Ollama可以通过11434端口打开模型,因此您可以通过“http://localhost:11434”访问它。此外,OllamaAPI的文档也为聊天对话和创建嵌入等基本命令提供了不同的端点。
在本项目案例中,我们希望使用/api/chat端点向AI模型发送提示。下图展示了一些与模型交互的基本Ruby代码:
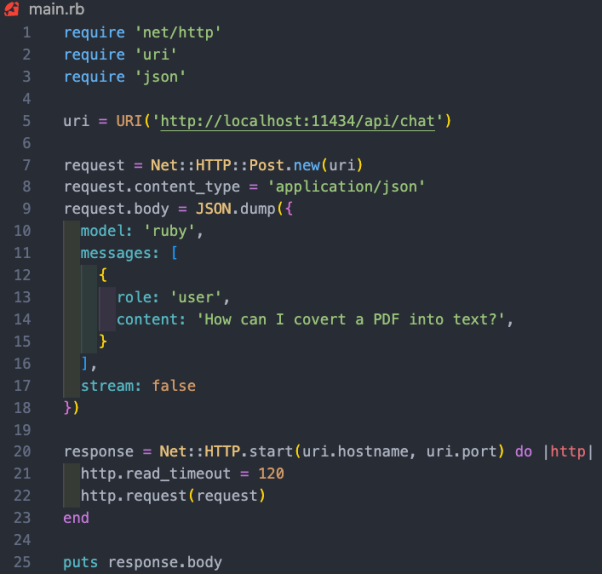
上述Ruby代码段的功能包括:
- 通过“net/http”、“uri”和“json”三个库,分别执行HTTP请求、解析URI和处理JSON数据。
- 创建包含API端点地址(http://localhost:11434/api/chat)的URI对象。
- 使用以URI为参数的Net::HTTP::Post.new方法,创建新的HTTP POST请求。
- 请求的正文被设置为一个代表了哈希值的JSON字符串。该哈希值包含了三个键:“模型”、“消息”和“流”。其中,
- 模型键被设置为“ruby”,也就是我们的模型;
- 消息键被设置为一个数组,其中包含了代表用户消息的单个哈希值;
- 而流键被设置为false。
- 系统引导模型该如何回应信息。我们已经在Modelfile中予以了设置。
- 用户信息是我们的标准提示。
- 模型会以辅助信息作出回应。
- 消息哈希遵循与AI模型交叉的模式。它带有一个角色和内容。此处的角色可以是系统、用户和辅助。其中,
- HTTP请求使用Net::HTTP.start方法被发送。该方法会打开与指定主机名和端口的网络连接,然后发送请求。连接的读取超时时间被设置为120秒,毕竟我运行的是2019款英特尔Mac,所以响应速度可能有点慢。而在相应的AWS服务器上运行时,这将不是问题。
- 服务器的响应被存储在“response”变量中。
案例小结
如上所述,运行本地AI模型的真正价值体现在,协助持有敏感数据的公司,处理电子邮件或文档等非结构化的数据,并提取有价值的结构化信息。在我们参加的项目案例中,我们对客户关系管理(CRM)系统中的所有客户信息进行了模型培训。据此,用户可以询问其任何有关客户的问题,而无需翻阅数百份记录。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:How To Run Open-Source AI Models Locally With Ruby,作者:Kane Hooper
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 小鹏P7i 702 Max鹏翼版正式上市,24.99万元起售挑战电动轿车市场
- 小鹏汽车P7i702Max鹏翼版于3月25日正式发布,售价定为24.99万元。这款新车型是在702Max长续航车型基础上打造的,最引人注目的地方在于其独特的“剪刀门”设计。这一设计不仅提升了车辆的时尚感,还为乘客进出车辆带来了全新体验。新车配备了强劲的动力系统,最大输出功率可达276马力,峰值扭矩达440Nm。搭载86.2千瓦时的电池,在CLTC工况下,续航里程可达702公里,为驾驶者带来稳定而持久的驾驶享受。除了出色的动力系统,小鹏P7i702Max鹏翼版在配置上也毫不逊色。从外观上看,新车提供了星暮紫
- 5分钟前 小鹏汽车 0
-
 正版软件
正版软件
- Yala:链接比特币流动性与生息稳定币
- TL;DR比特币的最初设计优先考虑安全性和去中心化,而不是智能合约和DeFi应用程序等复杂功能。因此,Yala在Ordinals协议上创建一种模块化架构,同时集成去中心化索引器网络和Oracle,为比特币引入智能合约能力,从而发行稳定币$YU。基于这种模块化设计,$YU能够自由地参与任何链上的DeFi活动,从而释放比特币巨大的流动性。Yala的目标是为比特币建立一个模块化的DeFi收益聚合器,通过联邦投票索引器(最终建成完全去中心化索引器)以及带有阈值签名的比特币保险库等机制来确保安全性和去中心化,同时通
- 20分钟前 0
-
 正版软件
正版软件
- 比特币ETF结束连5日净流出!减半后币价无重大波动
- 本站(120btC.coM):在比特币减半前夕,现货ETF结束了自12日以来的五日净流出,比特币减半后并没有明显波动,截稿前价格约64,172美元。比特币现货ETF终结连五日流出SoSoValue数据显示,比特币现货ETF结束自12日以来的五日净流出,4月19日总净流入为5,956万美元。各家ETF4月19日数据如下:灰度GBTC:-4580万美元贝莱德IBIT:2,930万美元富达FBTC:5,480万美元VanEck的HODL也有-180万的净流出。比特币现货ETF流量比特币自高点回撤近两成比特币近期
- 35分钟前 稳定币 比特币减半 主流币 莱特币减半 0
-
 正版软件
正版软件
- 数字货币哪些币种比较好
- 以下是最适合初学者的顶级数字货币:比特币(BTC):去中心化、稀缺性、长期价值以太坊(ETH):可编程区块链平台币安币(BNB):交易平台代币卡尔达诺(ADA):可扩展、高效的平台索拉纳(SOL):高速、低成本的平台在选择币种时,需考虑市场份额、用例、技术、团队和社区,以及个人风险承受能力。
- 45分钟前 0
-
 正版软件
正版软件
- btc钱包地址是什么类型钱包
- BTC钱包地址是属于非托管钱包,用户完全控制自己的资金,对私钥保管负责。
- 1小时前 16:05 0













