COLING24|智能剪枝技术助力多模态大型模型实现2-3倍加速,哈工大等机构发布SmartTrim
 发布于2024-12-18 阅读(0)
发布于2024-12-18 阅读(0)
扫一扫,手机访问
基于 Transformer 结构的视觉语言大模型(VLM)在各种下游的视觉语言任务上取得了巨大成功,但由于其较长的输入序列和较多的参数,导致其相应的计算开销地提升,阻碍了在实际环境中进一步部署。为了追求更为高效的推理速度,前人提出了一些针对 VLM 的加速方法,包括剪枝和蒸馏等,但是现有的这些方法大都采用静态架构,其针对不同输入实例采用同样的计算图进行推理,忽略了不同实例之间具有不同计算复杂性的事实:针对复杂的跨模态交互实例,自然需要更多计算才能完全理解图像和相关问题的复杂细节;相反,简单的实例则可以用更少的计算量解决。这也导致较高加速比下的 VLM 的性能严重下降。
为了解决上述问题,哈工大与度小满合作推出了一种新的自适应剪枝算法SmartTrim,专门针对多模态模型。这篇论文已经被自然语言处理领域顶级会议COLING 24接受发表。

前期探究和研究动机
文章首先对VLM中每一层的token表示和attention head的冗余情况进行了分析。研究发现如下:(1)无论是哪种模态的token或者head,层内的相似性始终很高,这表明模型存在着显著的冗余。(2)随着深度的增加,token的冗余度也在逐渐增加。(3)不同实例之间的冗余程度存在较大差异,这进一步说明依赖于输入的自适应剪枝对于加速VLM的重要性。
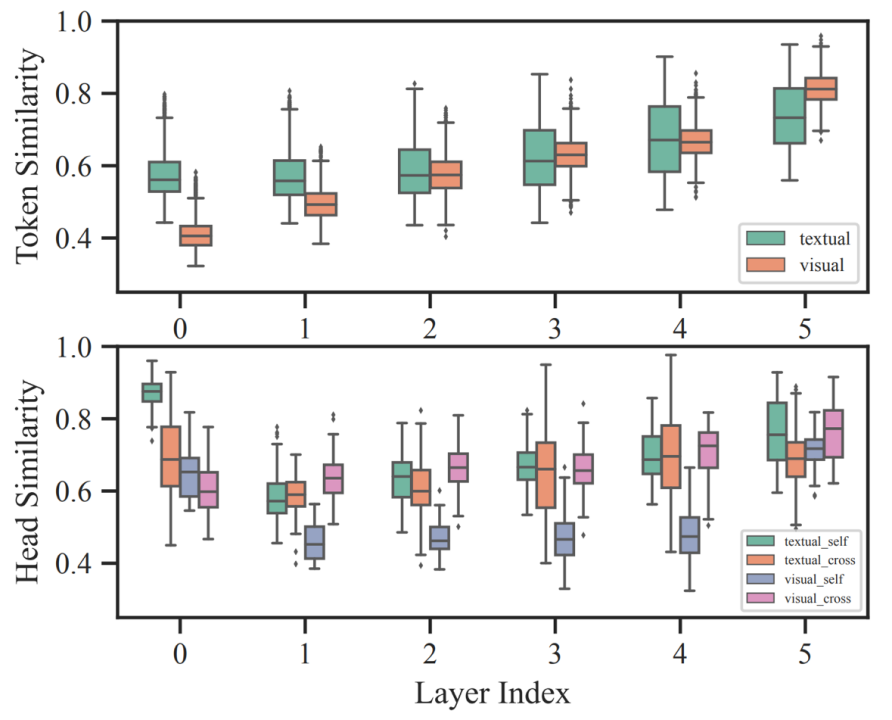
在基于 VQA 微调的 METER 的跨模态编码器中,层内不同 token(上)和 attention head(下)表示的相似性。
方法介绍
基于上述发现,本文提出针对 VLM 的自适应剪枝框架:SmartTrim,从 token 和 attention head 两方面同时对模型冗余部分进行剪枝。
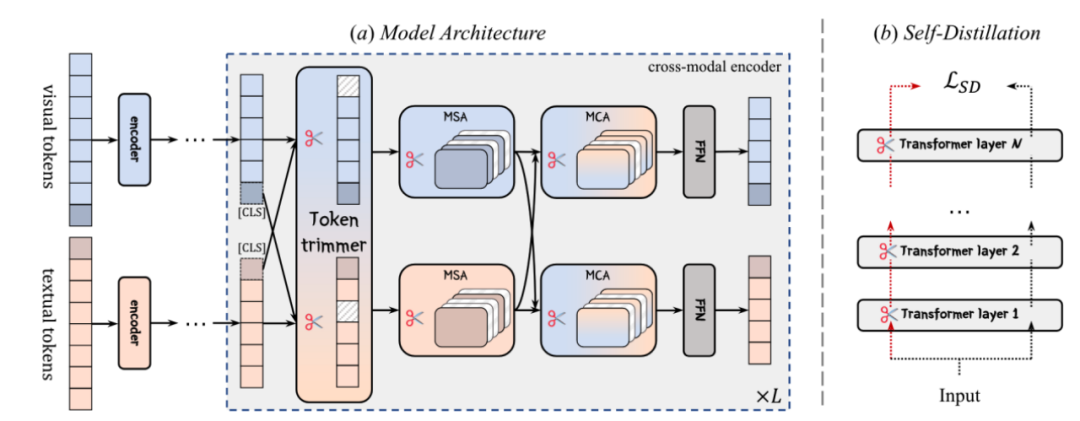
SmartTrim 框架结构图
跨模态感知的 Token 修剪器:
文本和图像各自的 Token 序列首先经过各自编码器进行编码,对于得到的序列表示,经过基于 MLP 结构的跨模态感知 Token 修剪器识别对于当前层不重要的 Token:在识别过程中模型不仅考虑 token 在当前模态序列的重要性,同时还要引入其在跨模态交互中的重要性。最终 token 的重要性分数转化成一个 0/1 的二值 mask 用来去除冗余 token。
模态自适应的注意力头修剪器:
VLM 分别通过 MSA(multi-head self-attention module) 和 MCA (multi-head cross-attention module)捕获模态内和模态间交互。正如前文分析,注意力部分计算开销根据输入的复杂性而变化,导致注意力模块出现的冗余会产生较大的开销。为此,我们将模态自适应注意力头修剪器集成到注意力模块中。该修剪器用以衡量各个注意力头的显著性,根据此对冗余的注意力头做修剪。
模型训练
在模型的训练过程中,我们在优化任务相关的训练目标的同时,还引入了计算开销相关的训练目标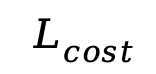 ,让模型在训练过程中对性能和效率进行权衡。针对上述修剪器生成的二值 mask(M)在训练中不可导的问题,我们采用了基于重参数化的技巧从而进行端到端的训练:
,让模型在训练过程中对性能和效率进行权衡。针对上述修剪器生成的二值 mask(M)在训练中不可导的问题,我们采用了基于重参数化的技巧从而进行端到端的训练:
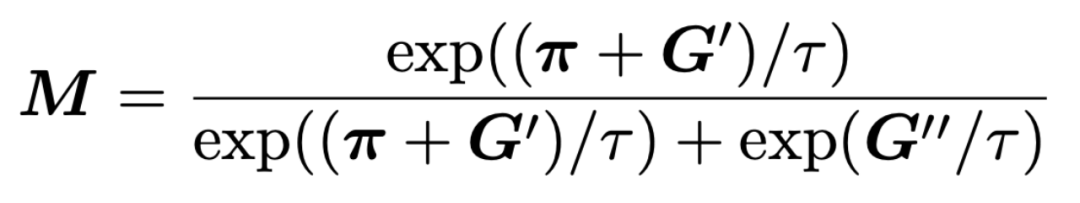
自蒸馏与课程训练策略:
我们还引入一种自蒸馏的训练策略来提高通过自适应剪枝得到的小模型:通过对齐剪枝后的小模型和全容量模型之间输出,使得剪枝模型的输出与全容量模型更为一致,进一步提高小模型的能力。另外我们利用课程学习的训练方式指导模型的训练,使模型稀疏度逐步减低到目标比例,从而保证了优化过程的稳定性。
最终的模型训练目标为:
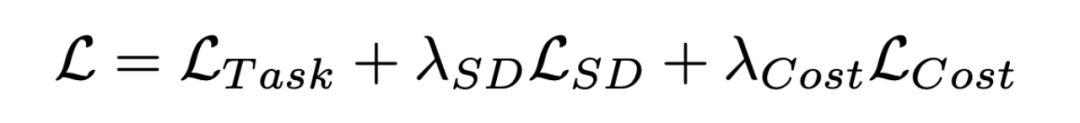
实验结果
我们基于 METER 和 BLIP 这两个 VLM 作为原始模型并在一系列下游 VL 任务上评估 SmartTrim 以及其他方法的性能和效率,如下表所示:我们的方法将原始模型加速了 2-3 倍,同时性能下降最小。
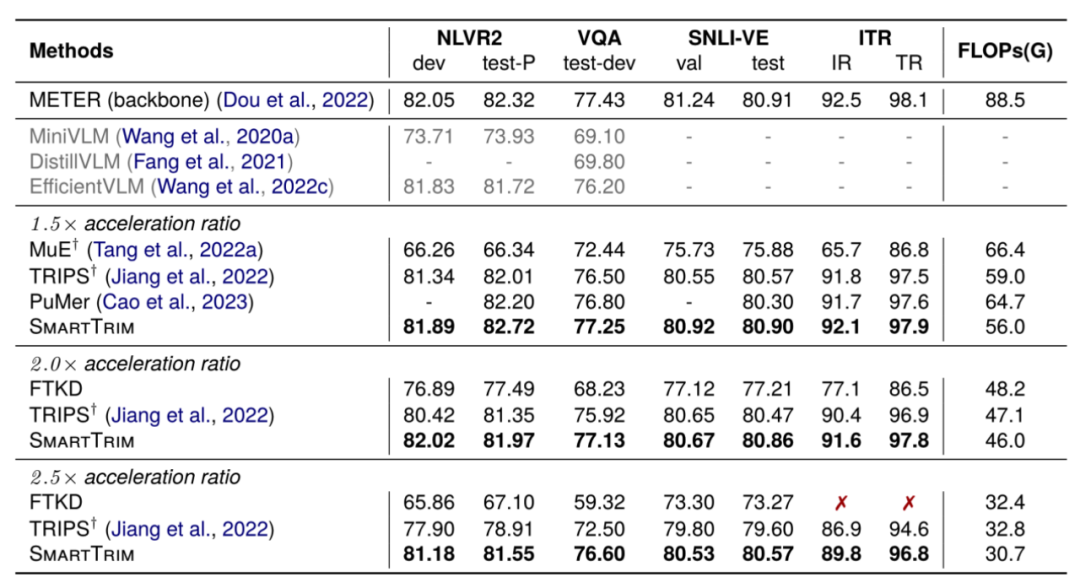
具有不同加速比下的 VLM 加速方法结果。
与前人方法相比,SmartTrim 不需要额外的预训练,而且还通过 token 和 head 两个方面提供了更细粒度地控制模型的计算开销,以更好地探索效率与性能之间的权衡,下面的帕累托图显示我们的方法在 1.5x 的加速比下甚至相比原始模型性能有所提升,而在高加速比下的相比其他加速方法具有显著优势。
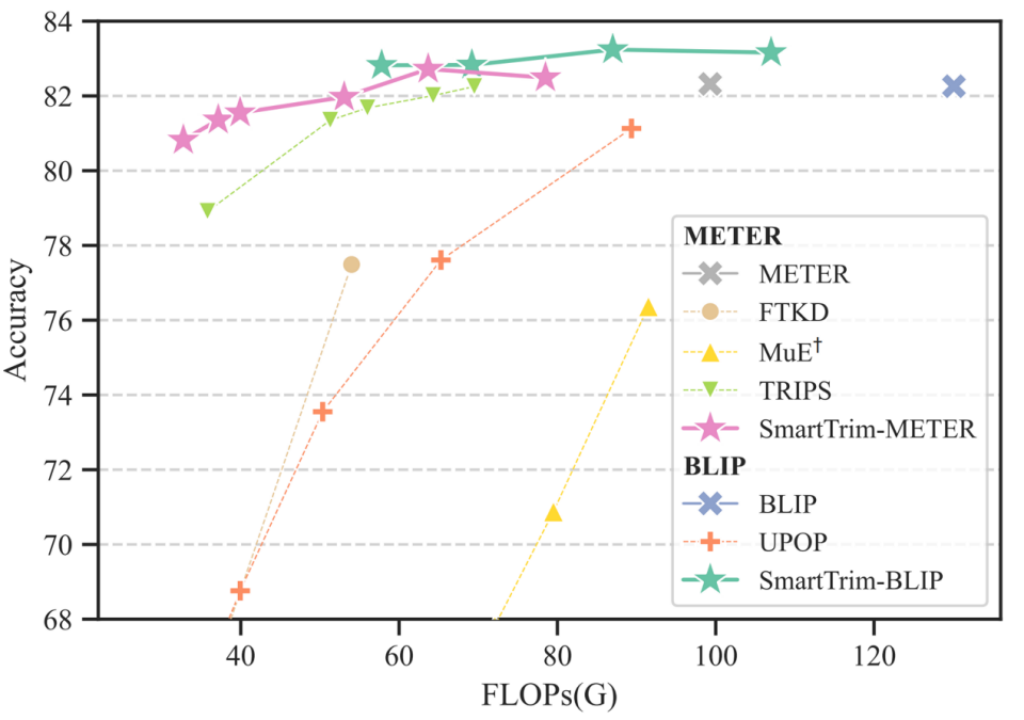
不同 VLM 加速方法在 NLVR2 上的效率与性能权衡的帕累托前沿。
我们进一步展示了一些随着深度增加 SmartTrim 逐步裁剪不同模态的冗余 token 的例子:

Token 的逐步裁剪修剪过程。
上图 (a)-(c) 是由我们提出的跨模态感知 Token 修剪器获得的,可以看到针对不同的问题我们的修剪器网络可以合适地选择更为相关的 patch。(d) 为去掉跨模态信息指导的基线模型地输出,我们也可以观察到其只保留了图片的主体部分但与问题并不相关的 patch token,并最终产生错误的答案。
我们还统计了在 vqa 数据的测试集上我们的 SmartTrim 为不同实例分配的计算量情况,如下图所示。可以发现 SmartTrim 可以自适应地根据跨模态交互的复杂性分配不同的计算开销,为简单实例(图左)分配更少的计算,为困难实例(图右)分配更多计算。
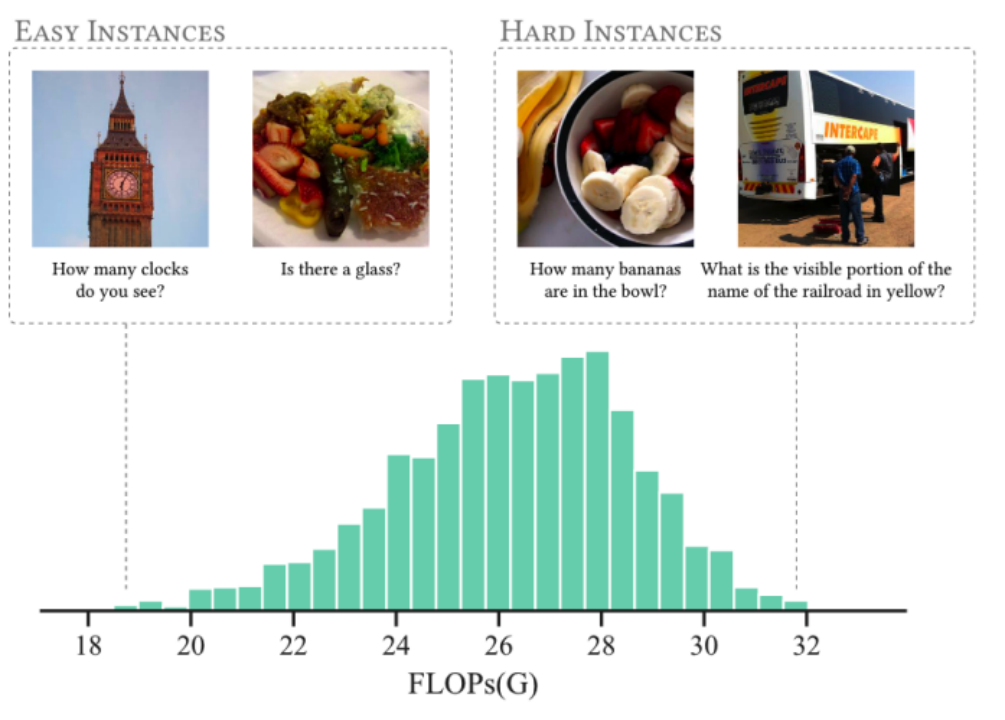
VQA 上 SmartTrim 的 FLOPs 直方图。
更多详细内容可以参考论文原文。论文提出的方法未来将结合到度小满轩辕大模型中,大模型项目地址:https://github.com/Duxiaoman-DI/XuanYuan,欢迎大家访问!
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 长安深蓝G318硬派SUV正式亮相,即将于5月上市 达到新科技高度
- 长安汽车旗下深蓝汽车的首款中大型SUVG318在深蓝超级增程进化日活动中亮相。这款备受称赞的“科技新硬派”车型,将硬派设计与科技完美结合,预计将于5月与消费者见面。虽然售价尚未公布,但已引起市场和消费者的广泛关注。G318的整体设计充满了硬朗的气息,无论是车顶的行李架与射灯一体化设计,还是粗犷的外观拓展部件,都彰显了其不凡的越野能力。据小编了解,该车的静态下载重达到了300KG,动态载重也可达到80KG,为户外探险和长途旅行提供了强大的装载能力。此外,侧开尾门和“小书包”外挂备胎的设计也使得其在实用性上更
- 7分钟前 长安深蓝 0
-
 正版软件
正版软件
- 首个全球性的Sora类开源复现方案发布!所有训练细节和模型权重均公开展示
- 全球首个开源的类Sora架构视频生成模型,来了!整个训练流程,包括数据处理、所有训练细节和模型权重,全部开放。这就是刚刚发布的Open-Sora1.0。它带来的实际效果如下,能生成繁华都市夜景中的车水马龙。还能用航拍视角,展现悬崖海岸边,海水拍打着岩石的画面。亦或是延时摄影下的浩瀚星空。自Sora发布以来,由于其惊人的效果和技术细节的稀缺性,揭示和复现Sora已成为开发社区中最受关注的话题之一。例如,Colossal-AI团队推出了一项能够降低46%成本的Sora训练和推理复现流程。短短两周时间后,该团队
- 22分钟前 人工智能 AI Sora 0
-
 正版软件
正版软件
- 医疗GenAI业务未来无限发展
- 对于医生来说,最热门的新技术有望重新带来一种古老的医疗实践:与患者进行面对面的对话。在佛罗里达州奥兰多举行的HIMSS会议上,3万多名卫生和技术专业人士聚集在一起,展厅的热门话题是环境中的临床文档。通过这项技术,医生可以自愿记录与患者的就诊情况,并借助人工智能将对话自动转换为临床笔记和摘要。NuanceCommunications、Abridge和Suki等公司已经推出了具备这些功能的解决方案。他们认为这将有助于减轻医生的管理负担,让他们更专注于与患者建立有意义的联系。Abridge创始人兼首席执行官Sh
- 37分钟前 人工智能 医疗保健 GenAI 0
-
 正版软件
正版软件
- 东方甄选回应315曝光:提前垫付退款处理生产梅菜扣肉事件
- 本站3月18日消息,今年的央视315晚会曝光了安徽厨先生食品有限公司、阜阳市春天食品有限公司、安徽东辉食品科技有限公司等企业用未经严格处理的槽头肉制作梅菜扣肉预制菜。3月16日,打假人王海在微博发文称“东方甄选”和“疯狂小杨哥”直播间都销售过这款产品。东方甄选在回应中表示,他们当晚进行了自查,并发现涉事产品“御徽缘梅菜扣肉”的生产商是安徽东辉科技食品有限公司。该产品的销售商家为湖北小橙优选科技发展有限公司,而东方甄选最后销售该产品的时间是2023年10月29日。针对质疑,销售商家和生产厂家均表示,“御徽缘
- 52分钟前 东方甄选 梅菜扣肉 0
-
 正版软件
正版软件
- B站今年将关注没有变现能力的个人 UP 主,设定月收入上限作为视频基础激励
- 本站3月18日消息,“视频创作激励计划”是B站推出的创作者扶持项目,主要聚焦内容创作的起步阶段。B站今日发布了视频创作激励年度计划(2024版),宣布自2024年起,该计划将以年度为单位进行更新和发布。今年,计划将在鼓励优质原创内容的基础上,重点关注暂无变现能力的个人UP主,通过激励计划为他们的早期创作和成长提供帮助。24年激励计划规则:1、重点关注暂无变现能力的UP主,作为基础激励的扶持对象。平台将在每月初根据UP主近半年收入水平,判断UP主当月是否享有基础激励,基础激励由内容质量、用户互动、更新频率等
- 1小时前 15:50 B站 哔哩哔哩 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1834天前
-
 2
2
- Overture设置踏板标记的方法
- 1671天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1661天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1859天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1825天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1821天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1836天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1857天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00