超越DETR:基于纯卷积Query的检测器取得突破!
 发布于2024-12-19 阅读(0)
发布于2024-12-19 阅读(0)
扫一扫,手机访问

标题:DECO: Query-Based End-to-End Object Detection with ConvNets
论文:https://arxiv.org/pdf/2312.13735.pdf
源码:https://github.com/xinghaochen/DECO
原文:https://zhuanlan.zhihu.com/p/686011746@王云鹤
引言
引入Detection Transformer(DETR)后,目标检测领域掀起了一股热潮,许多后续研究都在精度和速度方面对原始DETR进行了改进。然而,关于Transformer是否能够完全主导视觉领域的讨论仍在持续。一些研究如ConvNeXt和RepLKNet表明,CNN结构在视觉领域仍具有巨大的潜力。
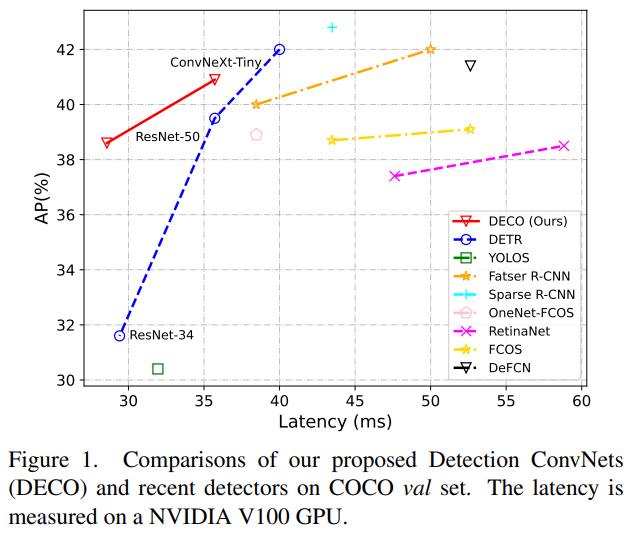
我们这个工作探究的就是如何利用纯卷积的架构,来得到一个性能能打的类 DETR 框架的检测器。致敬 DETR,我们称我们的方法为DECO (Detection ConvNets)。采用 DETR 类似的结构设定,搭配不同的 Backbone,DECO 在 COCO 上取得了38.6%和40.8%的AP,在V100上取得了35 FPS和28 FPS的速度,取得比DETR更好的性能。搭配类似RT-DETR的多尺度特征等模块,DECO取得了47.8% AP和34 FPS的速度,总体性能跟很多DETR改进方法比都有不错的优势。
方法
网络架构
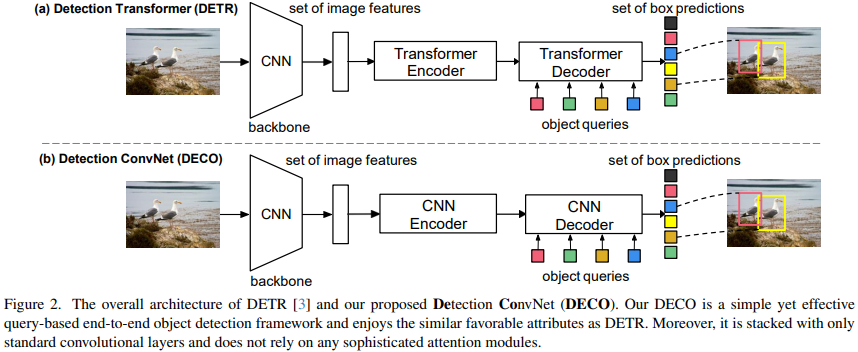
DETR的主要特点是利用Transformer Encoder-Decoder的结构,对一张输入图像,利用一组Query跟图像特征进行交互,可以直接输出指定数量的检测框,从而可以摆脱对NMS等后处理操作的依赖。我们提出的DECO总体架构上跟DETR类似,也包括了Backbone来进行图像特征提取,一个Encoder-Decoder的结构跟Query进行交互,最后输出特定数量的检测结果。唯一的不同在于,DECO的Encoder和Decoder是纯卷积的结构,因此DECO是一个由纯卷积构成的Query-Based端对端检测器。
编码器
DETR 的 Encoder 结构替换相对比较直接,我们选择使用4个ConvNeXt Block来构成Encoder结构。具体来说,Encoder的每一层都是通过叠加一个7x7的深度卷积、一个LayerNorm层、一个1x1的卷积、一个GELU激活函数以及另一个1x1卷积来实现的。此外,在DETR中,因为Transformer架构对输入具有排列不变性,所以每层编码器的输入都需要添加位置编码,但是对于卷积组成的Encoder来说,则无需添加任何位置编码
解码器
相比而言,Decoder的替换则复杂得多。Decoder的主要作用为对图像特征和Query进行充分的交互,使得Query可以充分感知到图像特征信息,从而对图像中的目标进行坐标和类别的预测。Decoder主要包括两个输入:Encoder的特征输出和一组可学的查询向量(Query)。我们把Decoder的主要结构分为两个模块:自交互模块(Self-Interaction Module, SIM)和交叉交互模块(Cross-Interaction Module, CIM)。
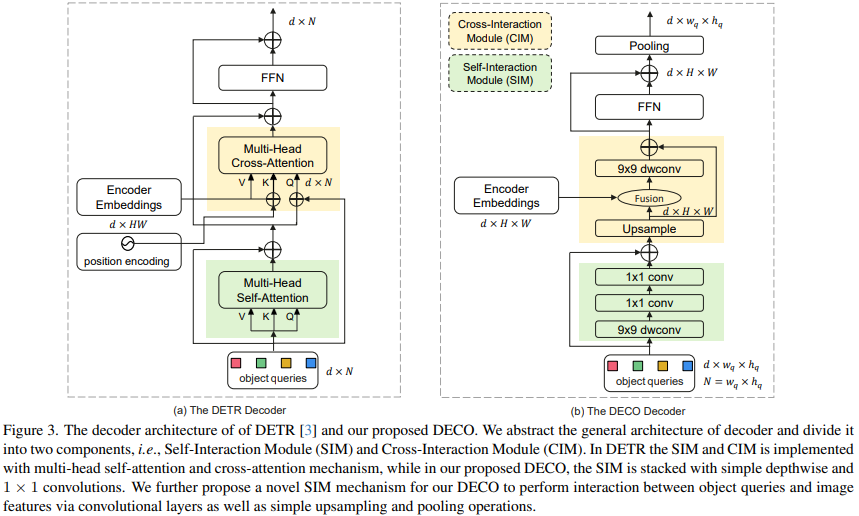
这里,SIM模块主要融合Query和上层Decoder层的输出,这部分的结构,可以利用若干个卷积层来组成,使用9x9 depthwise卷积和1x1卷积分别在空间维度和通道维度进行信息交互,充分获取所需的目标信息以送到后面的CIM模块进行进一步的目标检测特征提取。Query为一组随机初始化的向量,该数量决定了检测器最终输出的检测框数量,其具体的值可以随实际需要进行调节。对DECO来说,因为所有的结构都是由卷积构成的,因此我们把Query变成二维,比如100个Query,则可以变成10x10的维度。
CIM模块的主要作用是让图像特征和Query进行充分的交互,使得Query可以充分感知到图像特征信息,从而对图像中的目标进行坐标和类别的预测。对于Transformer结构来说,利用cross attention机制可以很方便实现这一目的,但对于卷积结构来说,如何让两个特征进行充分交互,则是一个最大的难点。
要把大小不同的SIM输出和encoder输出全局特征进行融合,必须先把两者进行空间对齐然后进行融合,首先我们对SIM的输出进行最近邻上采样:

使得上采样后的特征与Encoder输出的全局特征有相同的尺寸,然后将上采样后的特征和encoder输出的全局特征进行融合,然后进入深度卷积进行特征交互后加上残差输入:
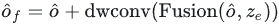
最后将交互后的特征通过FNN进行通道信息交互,之后pooling到目标数量大小得到decoder的输出embedding:
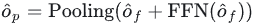
最后我们将得到的输出embedding送入检测头,以进行后续的分类和回归。
多尺度特征
跟原始的DETR一样,上述框架得到的DECO有个共同的短板,即缺少多尺度特征,而这对于高精度目标检测来说是影响很大的。Deformable DETR通过使用一个多尺度的可变形注意力模块来整合不同尺度的特征,但这个方法是跟Attention算子强耦合的,因此没法直接用在我们的DECO上。为了让DECO也能处理多尺度特征,我们在Decoder输出的特征之后,采用了RT-DETR提出的一个跨尺度特征融合模块。实际上,DETR诞生之后衍生了一系列的改进方法,我们相信很多策略对于DECO来说同样是适用的,这也希望感兴趣的人共同来探讨。
实验
我们在COCO上进行了实验,在保持主要架构不变的情况下将DECO和DETR进行了比较,比如保持Query数量一致,保持Decoder层数不变等,仅将DETR中的Transformer结构按上文所述换成我们的卷积结构。可以看出,DECO取得了比DETR更好的精度和速度的Tradeoff。
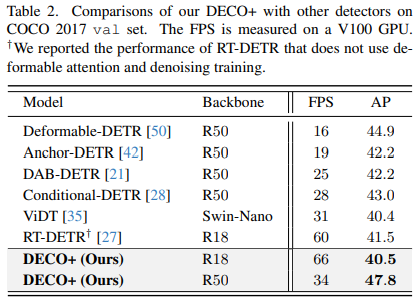
我们也把搭配了多尺度特征后的DECO跟更多目标检测方法进行了对比,其中包括了很多DETR的变体,从下图中可以看到,DECO取得了很不错的效果,比很多以前的检测器都取得了更好的性能。
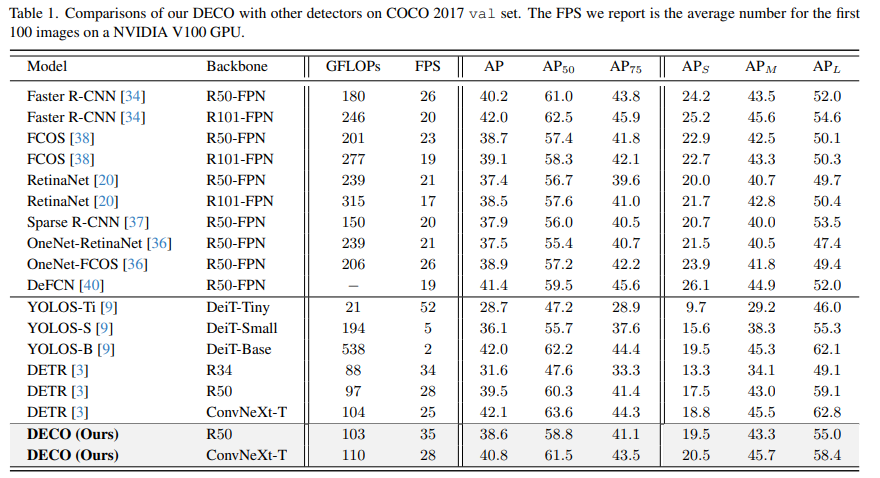
文章中DECO的结构进行了很多的消融实验及可视化,包括在Decoder中选用的具体融合策略(相加、点乘、Concat),以及Query的维度怎么设置才有最优的效果等,也有一些比较有趣的发现,更详细的结果和讨论请参看原文。
总结
本文旨在研究是否能够构建一种基于查询的端到端目标检测框架,而不采用复杂的Transformer架构。提出了一种名为Detection ConvNet(DECO)的新型检测框架,包括主干网络和卷积编码器-解码器结构。通过精心设计DECO编码器和引入一种新颖的机制,使DECO解码器能够通过卷积层实现目标查询和图像特征之间的交互。在COCO基准上与先前检测器进行了比较,尽管简单,DECO在检测准确度和运行速度方面取得了竞争性表现。具体来说,使用ResNet-50和ConvNeXt-Tiny主干,DECO在COCO验证集上分别以35和28 FPS获得了38.6%和40.8%的AP,优于DET模型。希望DECO提供了设计目标检测框架的新视角。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 狗币钱包怎么看地址
- 在狗币钱包中查看地址的方式取决于所使用的钱包类型。软件钱包可在“接收地址”字段中查看地址;硬件钱包可在“地址”选项卡中查看地址;在线钱包可在“地址”字段或“我的地址”中查看地址。
- 10分钟前 0
-
 正版软件
正版软件
- 预测蛋白质共调控和功能,哈佛&MIT训练含19层transformer的基因组语言模型
- 编辑|萝卜皮理解和设计生物系统的基础在于解析机器学习从大量蛋白质序列数据集中学习序列-结构-功能背后的关系,并将其潜藏在关系方面表现出的潜力呈现出来的浸润力。哈佛大学和马省理工学院(MIT)的研究人员在数百万个宏基因组框架上训练基因组组语言模型(gLM),从而分析基因之间潜在的功能和调控关系。“gLM+能够学习「上下文」化的蛋白质嵌入,捕获基因组上下文以及蛋白质序列本身,并编码具有生物学意义和功能相关的信息(例如酶功能、分类学)。该研究以「Genomiclanguagemodelpredictsprote
- 15分钟前 入门 0
-
 正版软件
正版软件
- Tp钱包怎么注册好的地址
- 要注册一个安全的TP钱包地址,需要以下步骤:下载TP钱包官方应用程序。创建新钱包并设置至少8个字符、包含大写和小写字母和数字的强健密码。备份好系统生成的12个英文单词助记词。核对助记词后,输入你的提款地址。记录并安全保存你的唯一钱包地址。
- 30分钟前 0
-
 正版软件
正版软件
- 如何查询波币最新价格?
- 如何查询波币最新价格?选择可靠的价格查询网站或交易所应用程序。在网站或应用程序中搜索TRX。查看TRX的最新价格。如何查询波币最新价格?波币(TRX)是一种加密货币,由波场创始人孙宇晨于2017年创立。波币旨在为去中心化应用提供可扩展和高效的平台。要查询波币最新价格,您可以按照以下步骤操作:选择一个可靠的价格查询网站或应用程序。一些常用的价格查询网站包括:CoinMarketCap:https://coinmarketcap.com/currencies/tron/Coindesk:https://www
- 45分钟前 0
-
 正版软件
正版软件
- 九号公司推出 F2 升级版电动滑板车:25km 续航,2599 元
- 本站4月19日消息,九号电动滑板车F2升级版现已上架并开启预售,首发价2599元,号称同价618。这款电动滑板车采用了LED实时显示屏,10英寸轮胎、高强性车架,承重200斤,电池寿命达到3000小时,续航可达20~25km,时速最高25km/h,号称5年后性能不低于新车的70%。除此外,它还采用了双轮制动(电子刹+碟刹),0.1秒响应,胎面具备破水防滑纹,保证潮湿路面不打滑。本站附参数如下:京东九号(Ninebot)电动滑板车F2F25F302599元领100元券
- 1小时前 17:00 电动滑板车 0













